Pandas之:Pandas简洁教程
Pandas之:Pandas简洁教程
简介
pandas是建立在Python编程语言之上的一种快速,强大,灵活且易于使用的开源数据分析和处理工具,它含有使数据清洗和分析⼯
作变得更快更简单的数据结构和操作⼯具。pandas经常和其它⼯具⼀同使⽤,如数值计算⼯具NumPy和SciPy,分析库statsmodels和scikit-learn,和数据可视化库matplotlib等。
pandas是基于NumPy数组构建的,虽然pandas采⽤了⼤量的NumPy编码⻛格,但⼆者最⼤的不同是pandas是专⻔为处理表格和混杂数据设计的。⽽NumPy更适合处理统⼀的数值数组数据。
本文是关于Pandas的简洁教程。
对象创建
因为Pandas是基于NumPy数组来构建的,所以我们在引用的时候需要同时引用Pandas和NumPy:
In [1]: import numpy as np
In [2]: import pandas as pd
Pandas中最主要的两个数据结构是Series和DataFrame。
Series和一维数组很相似,它是由NumPy的各种数据类型来组成的,同时还包含了和这组数据相关的index。
我们来看一个Series的例子:
In [3]: pd.Series([1, 3, 5, 6, 8])
Out[3]:
0 1
1 3
2 5
3 6
4 8
dtype: int64
左边的是索引,右边的是值。因为我们在创建Series的时候并没有指定index,所以index是从0开始到n-1结束。
Series在创建的时候还可以传入np.nan表示空值:
In [4]: pd.Series([1, 3, 5, np.nan, 6, 8])
Out[4]:
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
DataFrame是⼀个表格型的数据结构,它含有⼀组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
DataFrame既有⾏索引也有列索引,它可以被看做由Series组成的字典(共⽤同⼀个索引)。
看一个创建DataFrame的例子:
In [5]: dates = pd.date_range('20201201', periods=6)
In [6]: dates
Out[6]:
DatetimeIndex(['2020-12-01', '2020-12-02', '2020-12-03', '2020-12-04',
'2020-12-05', '2020-12-06'],
dtype='datetime64[ns]', freq='D')
上面我们创建了一个index的list。
然后使用这个index来创建一个DataFrame:
In [7]: pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
Out[7]:
A B C D
2020-12-01 1.536312 -0.318095 -0.737956 0.143352
2020-12-02 1.325221 0.065641 -2.763370 -0.130511
2020-12-03 -1.143560 -0.805807 0.174722 0.427027
2020-12-04 -0.724206 0.050155 -0.648675 -0.645166
2020-12-05 0.182411 0.956385 0.349465 -0.484040
2020-12-06 1.857108 1.245928 -0.767316 -1.890586
上面的DataFrame接收三个参数,第一个参数是DataFrame的表格数据,第二个参数是index的值,也可以看做是行名,第三个参数是列名。
还可以直接传入一个字典来创建一个DataFrame:
In [9]: pd.DataFrame({'A': 1.,
...: 'B': pd.Timestamp('20201202'),
...: 'C': pd.Series(1, index=list(range(4)), dtype='float32'),
...: 'D': np.array([3] * 4, dtype='int32'),
...: 'E': pd.Categorical(["test", "train", "test", "train"]),
...: 'F': 'foo'})
...:
Out[9]:
A B C D E F
0 1.0 2020-12-02 1.0 3 test foo
1 1.0 2020-12-02 1.0 3 train foo
2 1.0 2020-12-02 1.0 3 test foo
3 1.0 2020-12-02 1.0 3 train foo
上面的DataFrame中,每个列都有不同的数据类型。
我们用个图片来更好的理解DataFrame和Series:
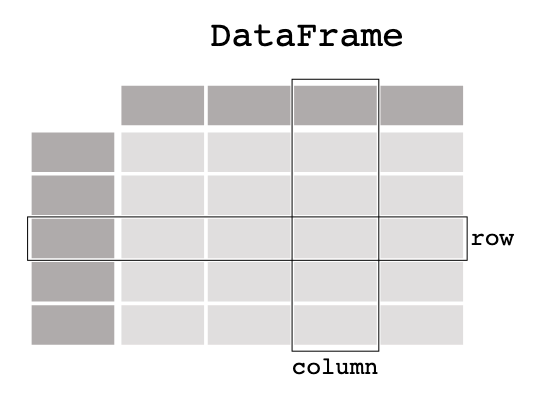
它就像是Excel中的表格,带有行头和列头。
DataFrame中的每一列都可以看做是一个Series:

查看数据
创建好Series和DataFrame之后,我们就可以查看他们的数据了。
Series可以通过index和values来获取其索引和值信息:
In [10]: data1 = pd.Series([1, 3, 5, np.nan, 6, 8])
In [12]: data1.index
Out[12]: RangeIndex(start=0, stop=6, step=1)
In [14]: data1.values
Out[14]: array([ 1., 3., 5., nan, 6., 8.])
DataFrame可以看做是Series的集合,所以DataFrame带有更多的属性:
In [16]: df.head()
Out[16]:
A B C D
2020-12-01 0.446248 -0.060549 -0.445665 -1.392502
2020-12-02 -1.119749 -1.659776 -0.618656 1.971599
2020-12-03 0.610846 0.216937 0.821258 0.805818
2020-12-04 0.490105 0.732421 0.547129 -0.443274
2020-12-05 -0.475531 -0.853141 0.160017 0.986973
In [17]: df.tail(3)
Out[17]:
A B C D
2020-12-04 0.490105 0.732421 0.547129 -0.443274
2020-12-05 -0.475531 -0.853141 0.160017 0.986973
2020-12-06 0.288091 -2.164323 0.193989 -0.197923
head跟tail分别取得DataFrame的头几行和尾部几行。
同样的DataFrame也有index和columns:
In [19]: df.index
Out[19]:
DatetimeIndex(['2020-12-01', '2020-12-02', '2020-12-03', '2020-12-04',
'2020-12-05', '2020-12-06'],
dtype='datetime64[ns]', freq='D')
In [20]: df.values
Out[20]:
array([[ 0.44624818, -0.0605494 , -0.44566462, -1.39250227],
[-1.11974917, -1.65977552, -0.61865617, 1.97159943],
[ 0.61084596, 0.2169369 , 0.82125808, 0.80581847],
[ 0.49010504, 0.73242082, 0.54712889, -0.44327351],
[-0.47553134, -0.85314134, 0.16001748, 0.98697257],
[ 0.28809148, -2.16432292, 0.19398863, -0.19792266]])
describe方法可以对数据进行统计:
In [26]: df.describe()
Out[26]:
A B C D
count 6.000000 6.000000 6.000000 6.000000
mean 0.040002 -0.631405 0.109679 0.288449
std 0.687872 1.128019 0.556099 1.198847
min -1.119749 -2.164323 -0.618656 -1.392502
25% -0.284626 -1.458117 -0.294244 -0.381936
50% 0.367170 -0.456845 0.177003 0.303948
75% 0.479141 0.147565 0.458844 0.941684
max 0.610846 0.732421 0.821258 1.971599
还可以对DataFrame进行转置:
In [27]: df.T
Out[27]:
2020-12-01 2020-12-02 2020-12-03 2020-12-04 2020-12-05 2020-12-06
A 0.446248 -1.119749 0.610846 0.490105 -0.475531 0.288091
B -0.060549 -1.659776 0.216937 0.732421 -0.853141 -2.164323
C -0.445665 -0.618656 0.821258 0.547129 0.160017 0.193989
D -1.392502 1.971599 0.805818 -0.443274 0.986973 -0.197923
可以按行和按列进行排序:
In [28]: df.sort_index(axis=1, ascending=False)
Out[28]:
D C B A
2020-12-01 -1.392502 -0.445665 -0.060549 0.446248
2020-12-02 1.971599 -0.618656 -1.659776 -1.119749
2020-12-03 0.805818 0.821258 0.216937 0.610846
2020-12-04 -0.443274 0.547129 0.732421 0.490105
2020-12-05 0.986973 0.160017 -0.853141 -0.475531
2020-12-06 -0.197923 0.193989 -2.164323 0.288091
In [29]: df.sort_values(by='B')
Out[29]:
A B C D
2020-12-06 0.288091 -2.164323 0.193989 -0.197923
2020-12-02 -1.119749 -1.659776 -0.618656 1.971599
2020-12-05 -0.475531 -0.853141 0.160017 0.986973
2020-12-01 0.446248 -0.060549 -0.445665 -1.392502
2020-12-03 0.610846 0.216937 0.821258 0.805818
2020-12-04 0.490105 0.732421 0.547129 -0.443274
选择数据
通过DataFrame的列名,可以选择代表列的Series:
In [30]: df['A']
Out[30]:
2020-12-01 0.446248
2020-12-02 -1.119749
2020-12-03 0.610846
2020-12-04 0.490105
2020-12-05 -0.475531
2020-12-06 0.288091
Freq: D, Name: A, dtype: float64
通过切片可以选择行:
In [31]: df[0:3]
Out[31]:
A B C D
2020-12-01 0.446248 -0.060549 -0.445665 -1.392502
2020-12-02 -1.119749 -1.659776 -0.618656 1.971599
2020-12-03 0.610846 0.216937 0.821258 0.805818
或者这样:
In [32]: df['20201202':'20201204']
Out[32]:
A B C D
2020-12-02 -1.119749 -1.659776 -0.618656 1.971599
2020-12-03 0.610846 0.216937 0.821258 0.805818
2020-12-04 0.490105 0.732421 0.547129 -0.443274
loc和iloc
使用loc可以使用轴标签来选取数据。
In [33]: df.loc[:, ['A', 'B']]
Out[33]:
A B
2020-12-01 0.446248 -0.060549
2020-12-02 -1.119749 -1.659776
2020-12-03 0.610846 0.216937
2020-12-04 0.490105 0.732421
2020-12-05 -0.475531 -0.853141
2020-12-06 0.288091 -2.164323
前面是行的选择,后面是列的选择。
还可以指定index的名字:
In [34]: df.loc['20201202':'20201204', ['A', 'B']]
Out[34]:
A B
2020-12-02 -1.119749 -1.659776
2020-12-03 0.610846 0.216937
2020-12-04 0.490105 0.732421
如果index的名字不是切片的话,将会给数据降维:
In [35]: df.loc['20201202', ['A', 'B']]
Out[35]:
A -1.119749
B -1.659776
Name: 2020-12-02 00:00:00, dtype: float64
如果后面列是一个常量的话,直接返回对应的值:
In [37]: df.loc['20201202', 'A']
Out[37]: -1.1197491665145112
iloc是根据值来选取数据,比如我们选择第三行:
In [42]: df.iloc[3]
Out[42]:
A 0.490105
B 0.732421
C 0.547129
D -0.443274
Name: 2020-12-04 00:00:00, dtype: float64
它其实和df.loc['2020-12-04']是等价的:
In [41]: df.loc['2020-12-04']
Out[41]:
A 0.490105
B 0.732421
C 0.547129
D -0.443274
Name: 2020-12-04 00:00:00, dtype: float64
同样可以传入切片:
In [43]: df.iloc[3:5, 0:2]
Out[43]:
A B
2020-12-04 0.490105 0.732421
2020-12-05 -0.475531 -0.853141
可以传入list:
In [44]: df.iloc[[1, 2, 4], [0, 2]]
Out[44]:
A C
2020-12-02 -1.119749 -0.618656
2020-12-03 0.610846 0.821258
2020-12-05 -0.475531 0.160017
取具体某个格子的值:
In [45]: df.iloc[1, 1]
Out[45]: -1.6597755161871708
布尔索引
DataFrame还可以通过布尔值来进行索引,下面是找出列A中所有元素大于0的:
In [46]: df[df['A'] > 0]
Out[46]:
A B C D
2020-12-01 0.446248 -0.060549 -0.445665 -1.392502
2020-12-03 0.610846 0.216937 0.821258 0.805818
2020-12-04 0.490105 0.732421 0.547129 -0.443274
2020-12-06 0.288091 -2.164323 0.193989 -0.197923
或者找出整个DF中,值大于0的:
In [47]: df[df > 0]
Out[47]:
A B C D
2020-12-01 0.446248 NaN NaN NaN
2020-12-02 NaN NaN NaN 1.971599
2020-12-03 0.610846 0.216937 0.821258 0.805818
2020-12-04 0.490105 0.732421 0.547129 NaN
2020-12-05 NaN NaN 0.160017 0.986973
2020-12-06 0.288091 NaN 0.193989 NaN
可以给DF添加一列:
In [48]: df['E'] = ['one', 'one', 'two', 'three', 'four', 'three']
In [49]: df
Out[49]:
A B C D E
2020-12-01 0.446248 -0.060549 -0.445665 -1.392502 one
2020-12-02 -1.119749 -1.659776 -0.618656 1.971599 one
2020-12-03 0.610846 0.216937 0.821258 0.805818 two
2020-12-04 0.490105 0.732421 0.547129 -0.443274 three
2020-12-05 -0.475531 -0.853141 0.160017 0.986973 four
2020-12-06 0.288091 -2.164323 0.193989 -0.197923 three
使用isin()来进行范围值的判断判断:
In [50]: df[df['E'].isin(['two', 'four'])]
Out[50]:
A B C D E
2020-12-03 0.610846 0.216937 0.821258 0.805818 two
2020-12-05 -0.475531 -0.853141 0.160017 0.986973 four
处理缺失数据
现在我们的df有a,b,c,d,e这5列,如果我们再给他加一列f,那么f的初始值将会是NaN:
In [55]: df.reindex(columns=list(df.columns) + ['F'])
Out[55]:
A B C D E F
2020-12-01 0.446248 -0.060549 -0.445665 -1.392502 one NaN
2020-12-02 -1.119749 -1.659776 -0.618656 1.971599 one NaN
2020-12-03 0.610846 0.216937 0.821258 0.805818 two NaN
2020-12-04 0.490105 0.732421 0.547129 -0.443274 three NaN
2020-12-05 -0.475531 -0.853141 0.160017 0.986973 four NaN
2020-12-06 0.288091 -2.164323 0.193989 -0.197923 three NaN
我们给前面的两个F赋值:
In [74]: df1.iloc[0:2,5]=1
In [75]: df1
Out[75]:
A B C D E F
2020-12-01 0.446248 -0.060549 -0.445665 -1.392502 one 1.0
2020-12-02 -1.119749 -1.659776 -0.618656 1.971599 one 1.0
2020-12-03 0.610846 0.216937 0.821258 0.805818 two NaN
2020-12-04 0.490105 0.732421 0.547129 -0.443274 three NaN
2020-12-05 -0.475531 -0.853141 0.160017 0.986973 four NaN
2020-12-06 0.288091 -2.164323 0.193989 -0.197923 three NaN
可以drop所有为NaN的行:
In [76]: df1.dropna(how='any')
Out[76]:
A B C D E F
2020-12-01 0.446248 -0.060549 -0.445665 -1.392502 one 1.0
2020-12-02 -1.119749 -1.659776 -0.618656 1.971599 one 1.0
可以填充NaN的值:
In [77]: df1.fillna(value=5)
Out[77]:
A B C D E F
2020-12-01 0.446248 -0.060549 -0.445665 -1.392502 one 1.0
2020-12-02 -1.119749 -1.659776 -0.618656 1.971599 one 1.0
2020-12-03 0.610846 0.216937 0.821258 0.805818 two 5.0
2020-12-04 0.490105 0.732421 0.547129 -0.443274 three 5.0
2020-12-05 -0.475531 -0.853141 0.160017 0.986973 four 5.0
2020-12-06 0.288091 -2.164323 0.193989 -0.197923 three 5.0
可以对值进行判断:
In [78]: pd.isna(df1)
Out[78]:
A B C D E F
2020-12-01 False False False False False False
2020-12-02 False False False False False False
2020-12-03 False False False False False True
2020-12-04 False False False False False True
2020-12-05 False False False False False True
2020-12-06 False False False False False True
合并
DF可以使用Concat来合并多个df,我们先创建一个df:
In [79]: df = pd.DataFrame(np.random.randn(10, 4))
In [80]: df
Out[80]:
0 1 2 3
0 1.089041 2.010142 -0.532527 0.991669
1 1.303678 -0.614206 -1.358952 0.006290
2 -2.663938 0.600209 -0.008845 -0.036900
3 0.863718 -0.450501 1.325427 0.417345
4 0.789239 -0.492630 0.873732 0.375941
5 0.327177 0.010719 -0.085967 -0.591267
6 -0.014350 1.372144 -0.688845 0.422701
7 -3.355685 0.044306 -0.979253 -2.184240
8 -0.051961 0.649734 1.156918 -0.233725
9 -0.692530 0.057805 -0.030565 0.209416
然后把DF拆成三部分:
In [81]: pieces = [df[:3], df[3:7], df[7:]]
最后把使用concat把他们合起来:
In [82]: pd.concat(pieces)
Out[82]:
0 1 2 3
0 1.089041 2.010142 -0.532527 0.991669
1 1.303678 -0.614206 -1.358952 0.006290
2 -2.663938 0.600209 -0.008845 -0.036900
3 0.863718 -0.450501 1.325427 0.417345
4 0.789239 -0.492630 0.873732 0.375941
5 0.327177 0.010719 -0.085967 -0.591267
6 -0.014350 1.372144 -0.688845 0.422701
7 -3.355685 0.044306 -0.979253 -2.184240
8 -0.051961 0.649734 1.156918 -0.233725
9 -0.692530 0.057805 -0.030565 0.209416
还可以使用join来进行类似SQL的合并:
In [83]: left = pd.DataFrame({'key': ['foo', 'foo'], 'lval': [1, 2]})
In [84]: right = pd.DataFrame({'key': ['foo', 'foo'], 'rval': [4, 5]})
In [85]: left
Out[85]:
key lval
0 foo 1
1 foo 2
In [86]: right
Out[86]:
key rval
0 foo 4
1 foo 5
In [87]: pd.merge(left, right, on='key')
Out[87]:
key lval rval
0 foo 1 4
1 foo 1 5
2 foo 2 4
3 foo 2 5
分组
先看上面的DF:
In [99]: df2
Out[99]:
key lval rval
0 foo 1 4
1 foo 1 5
2 foo 2 4
3 foo 2 5
我们可以根据key来进行group,从而进行sum:
In [98]: df2.groupby('key').sum()
Out[98]:
lval rval
key
foo 6 18
group还可以按多个列进行:
In [100]: df2.groupby(['key','lval']).sum()
Out[100]:
rval
key lval
foo 1 9
2 9
本文已收录于 http://www.flydean.com/01-python-pandas-overview/
最通俗的解读,最深刻的干货,最简洁的教程,众多你不知道的小技巧等你来发现!
欢迎关注我的公众号:「程序那些事」,懂技术,更懂你!
Pandas之:Pandas简洁教程的更多相关文章
- Pandas之:Pandas高级教程以铁达尼号真实数据为例
Pandas之:Pandas高级教程以铁达尼号真实数据为例 目录 简介 读写文件 DF的选择 选择列数据 选择行数据 同时选择行和列 使用plots作图 使用现有的列创建新的列 进行统计 DF重组 简 ...
- pandas数组(pandas Series)-(4)NaN的处理
上一篇pandas数组(pandas Series)-(3)向量化运算里说到,将两个 pandas Series 进行向量化运算的时候,如果某个 key 索引只在其中一个 Series 里出现,计算的 ...
- pandas数组(pandas Series)-(1)
导入pandas import pandas as pd countries = ['Albania', 'Algeria', 'Andorra', 'Angola', 'Antigua and Ba ...
- [Pandas]利用Pandas处理excel数据
Python 处理excel的第三包有很多,比如XlsxWriter.xlrd&xlwt.OpenPyXL.Microsoft Excel API等,最后综合考虑选用了Pandas. Pand ...
- pandas | 使用pandas进行数据处理——Series篇
本文始发于个人公众号:TechFlow,原创不易,求个关注 上周我们关于Python中科学计算库Numpy的介绍就结束了,今天我们开始介绍一个新的常用的计算工具库,它就是大名鼎鼎的Pandas. Pa ...
- pandas数组(pandas Series)-(5)apply方法自定义函数
有时候需要对 pandas Series 里的值进行一些操作,但是没有内置函数,这时候可以自己写一个函数,使用 pandas Series 的 apply 方法,可以对里面的每个值都调用这个函数,然后 ...
- pandas数组(pandas Series)-(3)向量化运算
这篇介绍下有index索引的pandas Series是如何进行向量化运算的: 1. index索引数组相同: s1 = pd.Series([1, 2, 3, 4], index=['a', 'b' ...
- pandas数组(pandas Series)-(2)
pandas Series 比 numpy array 要强大很多,体现在很多方面 首先, pandas Series 有一些方法,比如: describe 方法可以给出 Series 的一些分析数据 ...
- 【pandas】pandas.to_datatime()---时间格式转换
标准时间格式:2012-12-21 时间转换函数:pandas.to_datatime() # -*- coding: utf- -*- # 生成数据 import pandas as pd data ...
随机推荐
- Appium 自动化测试框架:关键字驱动+数据驱动
1. 关键字驱动框架简介 2. 框架结构说明 3. 框架代码实现 action 包 page_action.py business_process 包 case_process.py data_so ...
- 深入探索Android热修复技术原理读书笔记 —— 热修复技术介绍
1.1 什么是热修复 对于广大的移动开发者而言,发版更新是最为寻常不过的事了.然而,如果你 发现刚发出去的包有紧急的BUG需要修复,那你就必须需要经过下面这样的流程: 这就是传统的更新流程,步骤十分繁 ...
- hdu1261 JAVA
题意: 一个A和两个B一共可以组成三种字符串:"ABB","BAB","BBA".给定若干字母和它们相应的个数,计算一共可以组成多少个不同的 ...
- LA3708墓地雕塑
题意: 有N个墓碑,等距离的分布在一个圆形墓地的周围,然后又要添加m个墓碑,最后要求所有的墓碑还是等距离,添加的墓碑可以放在任意位置,问之前的N个墓碑的最少移动距离之和是多少? 思路: ...
- Linux基本内容
当你学会开发完成一个项目之后,你就可以将项目进行上线,而且其实并不难,你需要先对Linux操作系统了解一下,博客下面的内容是基于CentOs7服务器. 购买服务器 参考链接 Linux宝塔面板 Lin ...
- OCR横向评测 -- 软工案例分析
目录 第一部分 调研&评测 使用感受 1. 使用门槛 2. 界面设计 3. 数据标注 4. 模型训练 5. 模型预测 6. 体验评价与改进建议 好的方面: 可能需要改进的方面: 7. BUG反 ...
- [Java] 数据分析 -- 大数据
单词计数 需求:输入小说文本,输出每个单词出现的次数 实现:分map.combine.reduce三个阶段实现 1 /* Data Analysis with Java 2 * John R. Hub ...
- 对Linux系统内核版本稳定性测试介绍
对Linux系统内核版本稳定性测试介绍 在对 Linux 内核版本稳定性的测试中,需要明确地声明并证明为什么版本是稳定的或者是不稳定的. 然而还没有被证明和证实当前现有的系统范围内的压力测试可以测试 ...
- 【Git】git clone报错 git fatal: Unable to find remote helper for 'https'
[参考资料] https://stackoverflow.com/questions/8329485/unable-to-find-remote-helper-for-https-during-git ...
- Chm文件阅读软件测试需求
转发: .Chm文件阅读软件测试需求 . xchm问题太多就不考虑了: kchm是问题少一些 windows打开是乱码就不去考虑 必须在windows打开正常的再在龙芯上打开 1windows打开是乱 ...