HDFS06 DataNode
DataNode
DataNode工作机制
一个数据块在DataNode上以文字形式存储在磁盘上,包括一下两个文件。
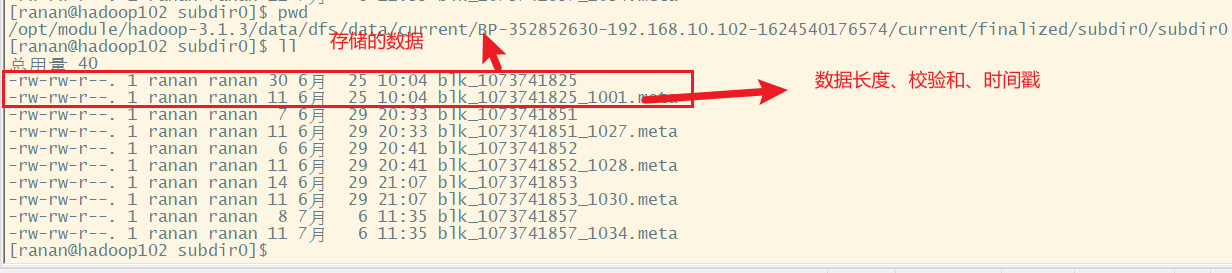
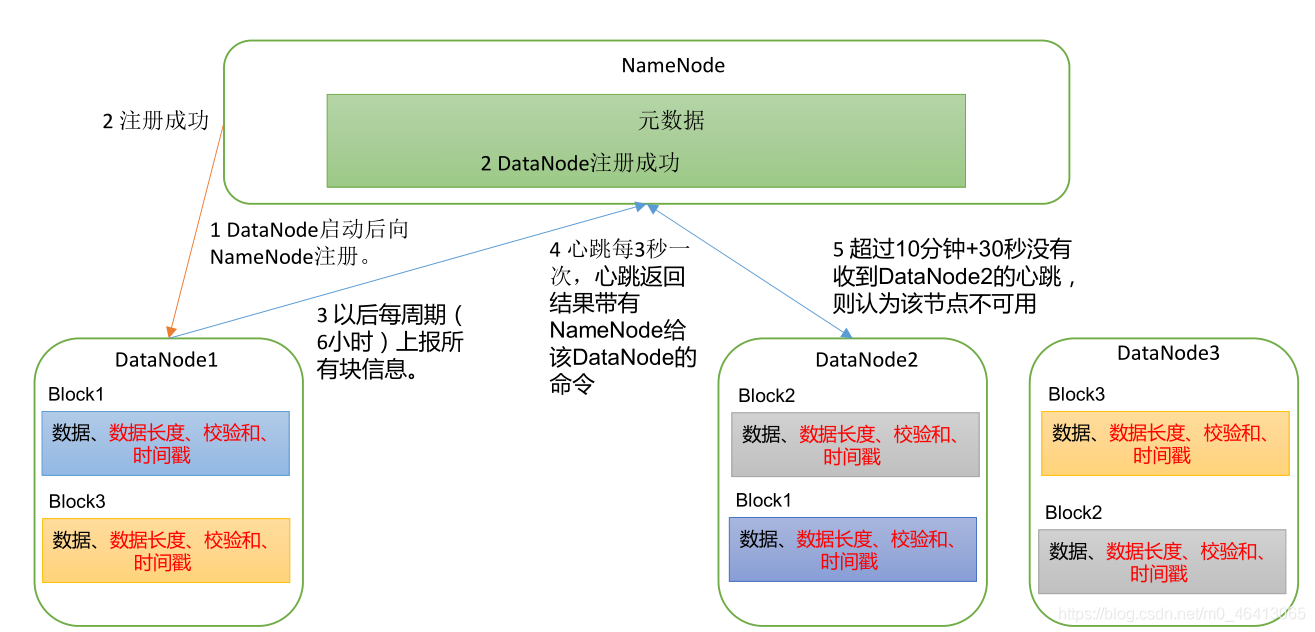
1.DataNode启动后告诉NameNode本机的块信息(块是否完好),并周期性(默认6个小时)上报所有块消息(块是否完好)。
如DataNode1中Block1的数据长度、校验和、时间戳,Block3的数据长度、校验和、时间戳
DN先扫描自己节点块信息列表,默认6小时扫描一次,扫描自己的块是否有损害。
<property>
<name>dfs.datanode.directoryscan.interval</name> --数据节点自查时间间隔
<value>21600s</value>
<description>Interval in seconds for Datanode to scan data
directories and reconcile the difference between blocks in memory and on
the disk.
Support multiple time unit suffix(case insensitive), as described
in dfs.heartbeat.interval.
</description>
</property>
DN再向NN汇报当前解读的信息,时间间隔默认6小时。
<property>
<name>dfs.blockreport.intervalMsec</name> --块信息报告的时间间隔ms
<value>21600000</value>
<description>Determines block reporting interval in
milliseconds.</description>
</property>
2.心跳每3s一次,DataNode->NameNode我还活着,心跳返回结果带有NameNode->DataNode的命令。
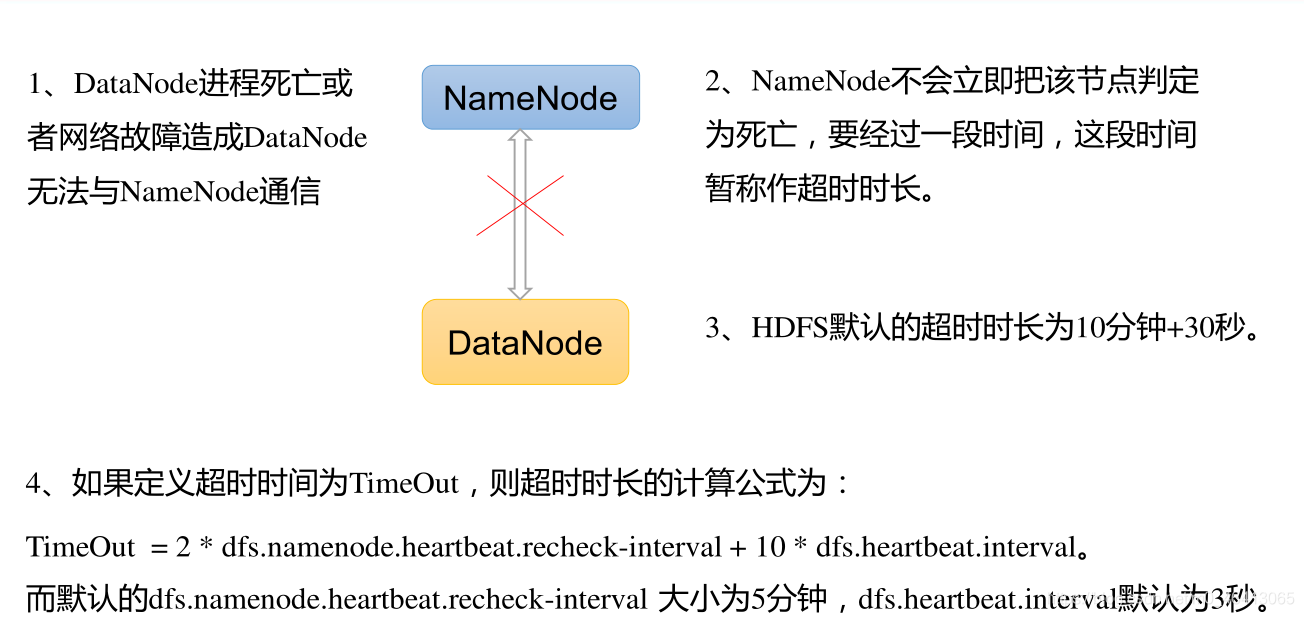
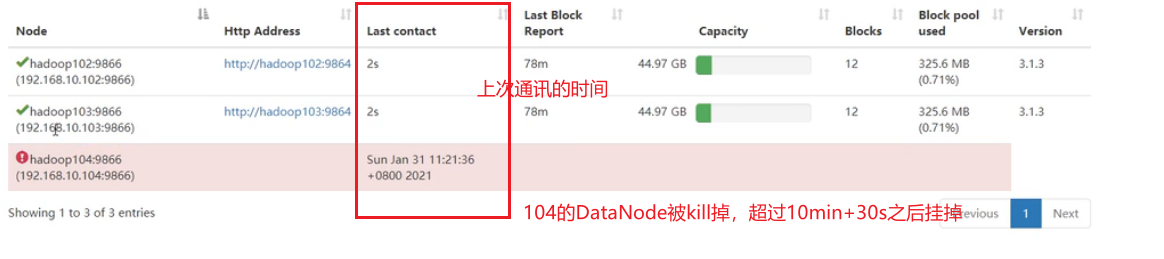
3.超过10分钟+30s没有收到心跳的话,则认为该节点不可用。就认为该节点挂了,不会再向其传输信息。
数据完整性
DataNode 节点保证数据完整性的方法。
1.当 DataNode 读取 Block 的时候,它会计算 CheckSum。
2.如果计算后的 CheckSum,与 Block 创建时值不一样,说明 Block 已经损坏。
3.Client 读取其他 DataNode 上的 Block。
4.常见的校验算法 crc(32),md5(128),sha1(160)
5.DataNode 在其文件创建后周期验证 CheckSum。
DataNode掉线时限参数设置
注意
hdfs-site.xml 配置文件中的 heartbeat.recheck.interval 的单位为毫秒,dfs.heartbeat.interval 的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>

HDFS06 DataNode的更多相关文章
- HDFS DataNode 设计实现解析
前文分析了 NameNode,本文进一步解析 DataNode 的设计和实现要点. 文件存储 DataNode 正如其名是负责存储文件数据的节点.HDFS 中文件的存储方式是将文件按块(block)切 ...
- 手动处理datanode磁盘间使用不均的问题
http://wiki.apache.org/hadoop/FAQ#On_an_individual_data_node.2C_how_do_you_balance_the_blocks_on_the ...
- Hadoop集群datanode磁盘不均衡的解决方案
一.引言: Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加新的数据节点,节点与节点之间磁盘大小不一样等等.当hdfs出现不平衡状况的时候,将引发很多问题,比 ...
- hadoop 完全分布式 下 datanode无法启动解决方法
问题描述: 在集群模式下更改节点后,启动集群发现 datanode一直启动不起来. 我集群配置:有5个节点,分别为master slave1-5 . 在master以Hadoop用户执行:start- ...
- 格式化namenode,造成无法启动datanode
一个常见的问题:格式化namenode,造成无法启动datanode的问题. 问题描述: 无法启动datanode,查看日志,datanote尝试n次启动无效后,会出现这个语句 INFO ...
- 检查Chunksum与Chunk Data之间的缓冲区发送到DataNode节点
我们会看到左边"iOS Apps"下面有四个选项:"Certificates"."Identifiers"."Devices&qu ...
- 解决hadoop启动后datanode无法启动问题
hadoop部署完成后datanode无法启动问题解决 1.检查是否有遗留的hadoop进程还在运行,如果有的话,先stop-all.sh或kill杀掉: 2.在master节点上,删除/tmp/ha ...
- Hadoop2.6 datanode配置在线更新
datanode 的配置可以在线更新了,http://blog.cloudera.com/blog/2015/05/new-in-cdh-5-4-how-swapping-of-hdfs-datano ...
- NameNode & DataNode
NameNode类位于org.apache.hadoop.hdfs.server.namenode包下. NameNode serves as both directory namespace man ...
随机推荐
- C++链表常见面试考点
链表常见问题: 单链表找到倒数第n个节点 用两个指针指向链表头,第一个指针先向前走n步,然后两个指针同步往前走,当第一个指针指向最后一个节点时,第二个指针就指向了倒数第n个节点. 判断链表有没有环 快 ...
- 看动画学算法之:双向队列dequeue
目录 简介 双向队列的实现 双向队列的数组实现 双向队列的动态数组实现 双向队列的链表实现 双向链表的时间复杂度 简介 dequeue指的是双向队列,可以分别从队列的头部插入和获取数据,也可以从队列的 ...
- OpenWrt编译问题记录
错误一.config.status: error: cannot find input file: `xmetadataretriever/Makefile.in' configure: creati ...
- Linux下安装、配置、启动与访问RabbitMQ
一.下载 首先第一步要下载三个rpm安装包,为了方便安装与学习,给出下载途径 网盘网址:https://pan.baidu.com/s/18Z64Lb9KQpRh10RzqZBdoQ 提取码:094v ...
- Iceberg概述
背景 随着大数据领域的不断发展, 越来越多的概念被提出并应用到生产中而数据湖概念就是其中之一, 其概念参照阿里云的简介: 数据湖是一个集中式存储库, 可存储任意规模结构化和非结构化数据, 支持大数据和 ...
- SpringBoot 整合 Docker
最近备忘录新加的东西倒是挺多的,但到了新环境水土不服没动力去整理笔记 1. Demo Project 首先准备一个简单的项目,用来部署到 Docker 主机上,并且能验证该项目是否成功运行 1.1 接 ...
- Flink 实践教程:入门(6):读取 PG 数据写入 ClickHouse
作者:腾讯云流计算 Oceanus 团队 流计算 Oceanus 简介 流计算 Oceanus 是大数据产品生态体系的实时化分析利器,是基于 Apache Flink 构建的具备一站开发.无缝连接.亚 ...
- Pycharm下载安装详细教程
目录 1.Pycharm 简介 2.Pycharm下载 3.环境变量的配置 4.Pycharm的使用 1.Pycharm 简介 PyCharm是一种Python IDE(Integrated Deve ...
- scrapy的安装,scrapy创建项目
简要: scrapy的安装 # 1)pip install scrapy -i https://pypi.douban.com/simple(国内源) 一步到位 # 2) 报错1: building ...
- Java将增加虚拟线程,挑战Go协程
我们知道 Go 语言最大亮点之一就是原生支持并发,这得益于 Go 语言的协程机制.一个 go 语句就可以发起一个协程 (goroutin).协程本质上是一种用户态线程,它不需要操作系统来进行调度,而是 ...