SQL必知必会 —— 性能优化篇
数据库调优概述
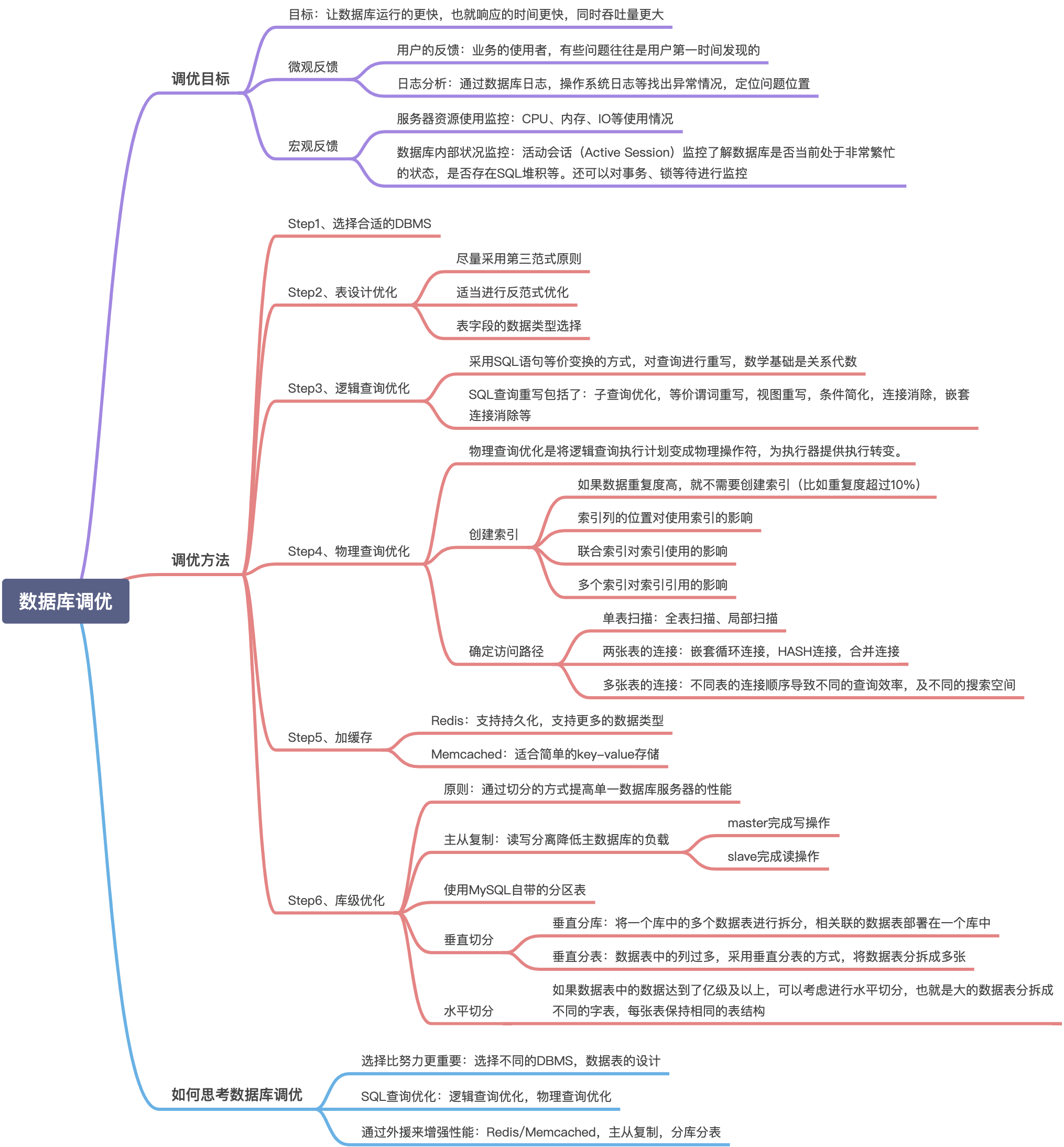
- 数据库中的存储结构是怎样的
在数据库中,不论读一行,还是读多行,都是将这些行所在的页进行加载。也就是说,数据库管理存储空间的基本单位是页(Page)。
一个页中可以存储多个行记录(Row),同时在数据库中,还存在着区(Extent)、段(Segment)和表空间(Tablespace)。行、页、区、段、表空间的关系如下图所示:
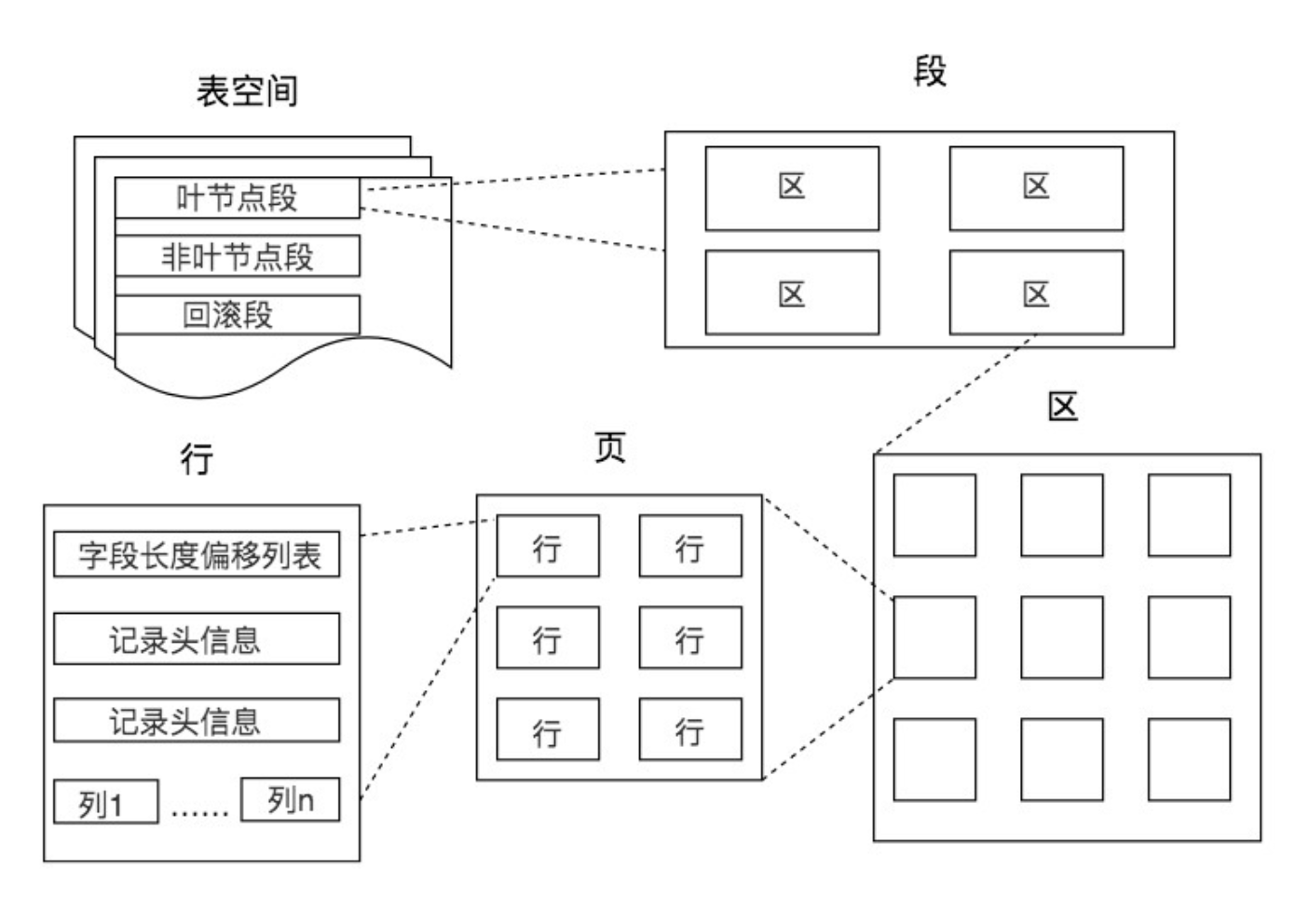
区(Extent)是比页大一级的存储结构,在InnoDB存储引擎中,一个区会分配64个连续的页。因为InnoDB中的页大小默认是16KB,所以一个区的大小是64*16KB = 1MB
段(Segment)由一个或多个区组成,区在文件系统是一个连续分配的空间(在InnoDB中是连续的64个页),不过在段中不要求区与区之间是相邻的。段是数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。
表空间(Tablespace)是一个逻辑容器,表空间存储的对象是段,在一个表空间中可以有一个或多个段,但是一个段只能属于一个表空间。数据库由一个或多个表空间组成,表空间从管理上可以划分为系统表空间、用户表空间、撤销表空间、临时表空间等。
页(Page)如果按类型划分的话,常见的由数据页(保存B+树节点)、系统页、Undo页和事务数据页等。数据页是我们最常使用的页。数据页包括七个部分,分别是文件头(File Header)、页头(Page Header)、最大最小记录(Infimum + supremum)、用户记录(User Records)、空闲空间(Free Space)、页目录(Page Directory)和文件尾(File Tailer)。页结构的示意图如下:
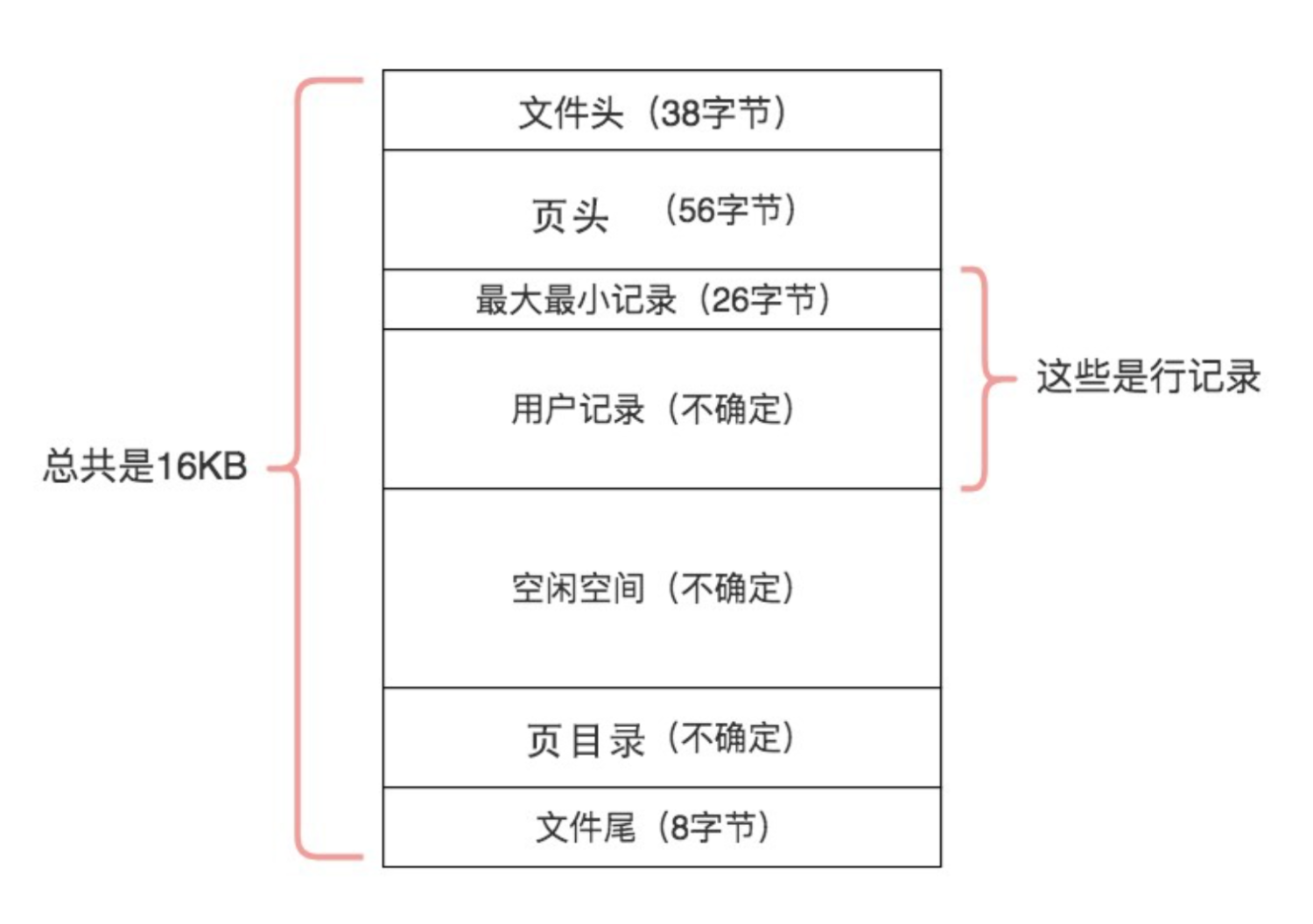
|
名称 |
占用大小 |
说明 |
|
File Header |
38字节 |
文件头,描述页的信息 |
|
Page Header |
56字节 |
页头,页的状态信息 |
|
Infimum + Supremum |
26字节 |
最小和最大记录,这是两个虚拟的行记录 |
|
User Records |
不确定 |
用户记录,存储行记录内容 |
|
Free Space |
不确定 |
空闲空间,页中还没有被使用的空间 |
|
Page Directory |
不确定 |
页目录,存储用户记录的相对位置 |
|
File Trailer |
8字节 |
文件尾,校验页是否完整 |
范式设计
范式(NF):不同等级的规范要求。高阶的范式一定符合低阶范式的要求。
目前关系型数据库共有6种范式,按照范式级别,从低到高分别是:1NG(第一范式)、2NF(第二范式)、3NF(第三范式)、BCNF(巴斯-科德范式)、4NF(第四范式)和5NF(第五范式,又叫完美范式)
反范式:有时候为了提高某些查询性能,可能需要破坏范式规则。
- 数据表中的那些键
范式的定义会使用到主键和候选键(因为主键和候选键可以唯一标识元组),数据库中的键(Key)由一个或者多个属性组成。
- 超键:能唯一标识援助的属性集叫做超键。
- 候选键:如果超键不包括多余的属性,那么这个超键就是候选键。
- 主键:用户可以从候选键中选择一个座位主键。
- 外键:如果数据表R1中的某属性集不是R1的主键,而是另一个数据表R2的主键,那么这个属性集就是数据表R1的外键。
- 主属性:包含在任一候选键中的属性称为主属性。
- 非主属性:与主属性相对,指的是不包含在任何一个候选键中的属性。
通常,也将候选键称之为“码”,把主键也称为“主码”。因为键可能由多个属性组成的,针对单个属性,还可以用主属性和非主属性来进行区分。
从1NF到3NF
- 1NF指的是数据库表中的任何属性都是原子性的,不可再分。
- 2NF指的数据表里的非主属性都要和这个数据表的候选键有完全依赖关系。
- 3NF在满足2NF的同时,滴任何非主属性都不传递依赖于候选键。
- 1NF需要保证表中每个属性都保持原子性;2NF需要保证表中的非主属性与候选键完全依赖;3NF需要保证表中的非主属性与候选键不存在传递依赖。
BCNF(巴斯范式)
在3NF的基础上消除了主属性对候选键的部分依赖或者依赖传递关系。
反范式设计
反范式相当于通过空间换时间。
- 范式的目的是降低数据冗余度,而反范式会增加数据冗余度。
- 如果多张表进行关联查询的适合,想要提升查询的效率,可以允许适当的数据冗余度。
- 如果需要历史快照,可以考虑增加数据冗余度,采用反范式设计
- 数据仓库通常会采用反范式设计
- 实际工作中,需要根据需要将范式和反范式结合使用
数据库与数据仓库的区别?
- 数据库设计的目的在于捕获数据;而数据仓库设计的目的在于分析数据
- 数据库对数据的增删查改实时性要求强,存储在线的用户数据;而数据仓库存储的一般是历史数据
- 数据库设计尽量避免冗余,但有时候为了提供查询效率也允许一定的冗余度;而数据仓库在设计上采用反范式更加常见
索引
数据库中的索引,好比一本书中的目录,它可以帮我们快速进行特定值的定位与查找,从而加快数据查询的效率。索引就是帮助数据库管理系统高效获取数据的数据结构。
索引的种类
从功能逻辑上说,索引主要有4种,分别是普通索引、唯一索引、主键索引和全文索引。
- 普通索引
基础的索引,没有任何约束,主要用于提高查询效率。
- 唯一索引
在普通索引的基础上增加了数据唯一性的约束,在一张数据表里可以有多个唯一索引。
- 主键索引
在唯一索引的基础上增加了不为空的约束,也就是NOT NULL + UNIQUE,一张表里最多只有一个主键索引。
- 全文索引
全文索引用的不多,MySQL自带的全文索引只支持英文。
前三种索引都是一类索引,只不过对数据的约束性逐渐提升。在一张数据表中只能有一个主键索引,这是由主键索引的物理实现方式决定的,因为数据存储在文件中只能按照一种顺序进存储。但可以有多个普通索引或多个唯一索引。
按照物理实现方式,索引可以分为2种:聚集索引和非聚集索引。非聚集索引称为二级索引或辅助索引。
- 聚集索引
按照主键来排序存储数据。每一个表只能有一个聚集索引,因为数据行本身只能按一个顺序存储。
- 非聚集索引
在数据库系统会有单独的存储空间存放非聚集索引,这些索引是按照顺序存储的,单索引指向的内容是随机存储的。
- 区别
- 聚集索引的叶子节点存储的就是数据记录,非聚集索引的叶子节点存储的是数据位置。非聚集索引不会影响数据表的物理存储顺序。
- 一个表只能有一个聚集索引,因为只能有一种顺序存储的方式,但可以有多个非聚集索引,也就是多个索引目录提供数据检索。
- 使用聚集索引的时候,数据的查询效率高,但如果对数据进行插入,删除,更新等操作,效率会比非聚集索引低。
按照字段个数,索引可以分为:单一索引和联合索引
- 单一索引
索引列为一列时为单一索引
- 联合索引
多个列组合在一起创建的索引
索引的数据结构
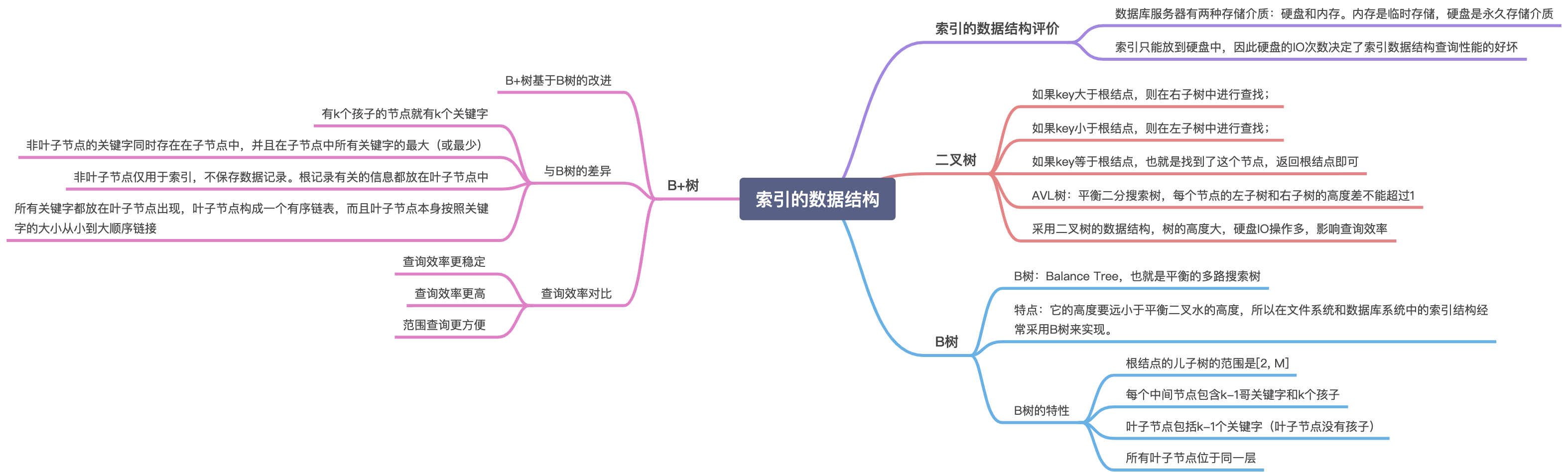
Hash的原理和使用
- 理解Hash
- Hash本身是一个函数,又被称为散列函数,它可以帮助我们大幅提升检索数据的效率。
- Hash算法是通过某种确定性的算法(比如MD5、SHA1、SHA2、SHA3)将输入转变为输出。
- Hash是现代密码学的核心,它被用于各种安全验证场景,比如密码存储,文件验证系统。
- MD5就是Hash函数的一种,Hash函数有多种映射方式。
- B+树索引的区别
- Hash索引不能支持范围查询
- Hash索引不支持联合索引的最左侧原则,即联合索引的部分索引无法使用
- Hash索引不支持ORDER BY排序
- Hash索引不能进行模糊查询
- 如果字段的重复值较多,Hash索引效率可能比B+树索引效率低
索引的使用原则
- 创建索引有哪些规律
- 字段的数值有唯一性的限制,比如用户名
- 频繁作为WHERE查询条件的字段,尤其在数据表大的情况下
- 需要经常GROUP BY 和 ORDER BY的列
- UPDATE、DELETE的WHERE条件列,一般也需要创建索引
- DISTINCT字段需要创建索引
- 做多表JOIN连接操作时,创建索引需要注意以下的原则:
- 首先,连接表的数量尽量不要超过3张,因为每增加一张表就相当于增加了一次嵌套的循环,数量级增长会非常快,严重影响查询的效率。
- 其次,对WHERE条件创建索引,因为WHERE才是对数据条件的过滤。如果在数据量非常大的情况下,没有WHERE条件过滤是非常可怕的。
- 最后,对用于连接的字段创建索引,并且该字段在多张表中的类型必须一致。
- 什么时候不需要创建索引
- WHERE条件(包括GROUP BY、ORDER BY)里用不到的字段不需要创建索引,索引的价值是款素定位,如果起不到定位的字段通常是不需要创建索引的。
- 如果表记录太少,比如少于1000个,那么是不需要创建索引的。
- 字段中如果有大量重复数据,也不用创建索引,比如性别字段。(但也要根据实际情况判断)
- 频繁更新的字段不一定要创建索引。
- 什么情况下索引失效
- 如果索引进行了表达式计算,则会失效。
- 如果对索引使用函数,也会造成失效。
- 在WHERE子句中,如果在OR前的条件列进行了索引,而在OR后的条件列没有进行索引,那么索引会失效。
- 当使用LIKE进行模糊查询的时候,后面不能是%。
- 索引列与NULL或者NOT NULL进行判断的时候也会失效。
- 在使用联合索引时要注意最左原则。
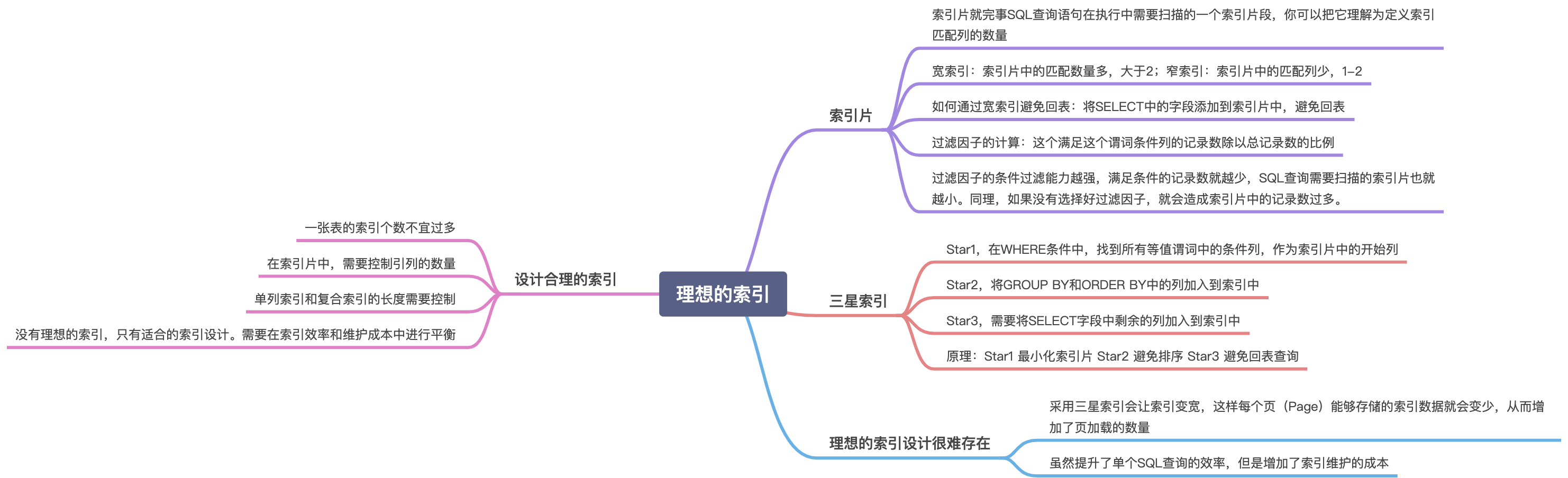
理想的索引
锁
- 关于死锁
死锁就是多个事务(如果是在程序层面就是多个进程)在执行 过程中,因为竞争某个相同的资源而造成阻塞的现象。发生死锁,往往是因为在事务中,锁的获取是逐步进行的。
- 如何避免死锁
- 如果事务涉及多个表,操作比较复杂,那么可以尽量一次锁定所以的资料,而不是逐步来获取,这样可以减少死锁发生的概率。
- 如果事务需要更新数据表中的大部分数据,数据表又比较大,这时可以采用锁升级的方式,比如讲行级锁升级为表级锁,从而减少死锁产生的概率。
- 不同事务并发读写多张数据库,可以访问表的顺序,采用相同的数据降低死锁发生的该。
按照锁粒度进行划分
锁用来对数据进行锁定,我们可以从锁定对象的粒度大小来对锁进行划分,分别为行锁、页锁和表锁。
行锁就是按照行的粒度对数据进行锁定。锁定粒度小,发送锁冲突高了低,可以实现的并发度高。但是对于锁的开销比较大,加锁比较慢,容易出现死锁情况。
页锁就是在页的粒度上进行锁定,锁定的数据资源比行锁高,因为一个页中可以有多个行记录。使用页锁会数显数据浪费的现象。页锁的开销介于表锁和行锁之间,会出现死锁。锁定粒度介于表锁和行锁之间,并发度一般。
表锁就是对数据表进行锁定,锁定粒度大,同时发生锁冲突的概率也会较高,数据访问的并发度低。好处在于对锁的使用开销小,加锁会很快。
行锁、页锁和表锁是相对常见的三种锁,除此之外还可以在区和数据库的粒度上锁定数据,对应区锁和数据库锁。
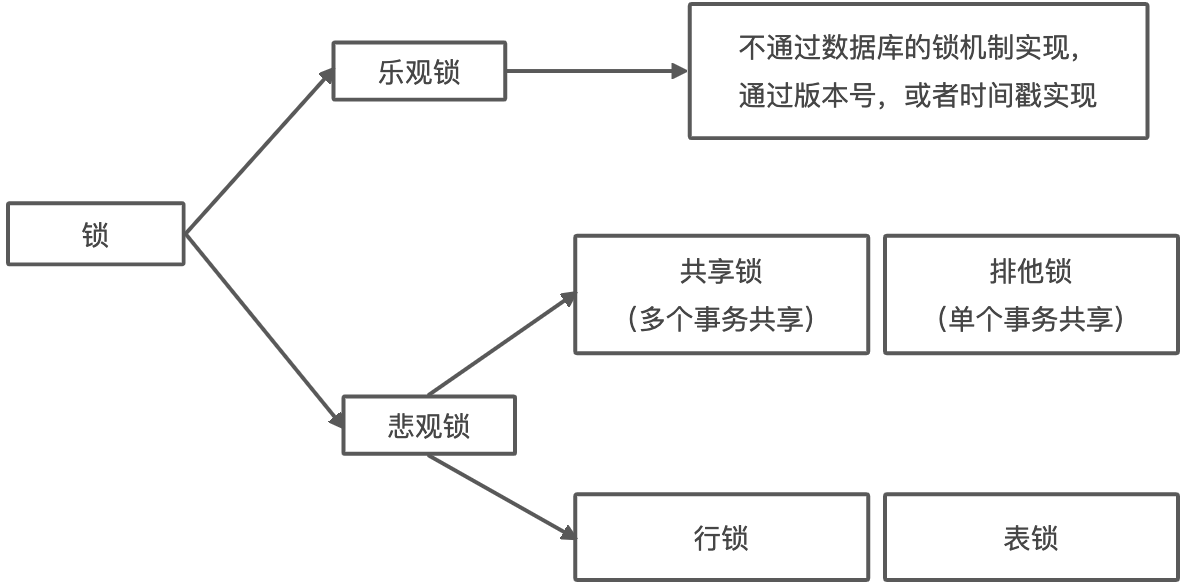
从数据库管理的角度对锁进行划分
分为共享锁和排它锁。
共享锁也叫读锁或S锁,共享锁锁定的资源可以被其他用户读取,但不能修改。
排它锁也叫独占锁、写锁或X锁。排它锁锁定的数据只允许进行锁定操作的事务使用,其他事务无法对已锁定的数据进行查询或修改。
从程序员的角度进行划分
分为乐观锁和悲观锁
乐观锁(Optimistic Locking)认为对同一数据的并发操作不会总发生,属于小概率事件,不用每次都对数据上锁,也就是不采用数据库自身的锁机制,而是通过程序来实现。
在程序上,可以采用版本号机制或时间戳机制实现。
悲观锁(Pessimistic Locking)也是一种思想,对数据被其他事务的修改保持保守态度,会通过数据库自身的锁机制来实现,从而保证数据操作的排它性。
适用场景:
- 乐观锁适合读操作多的场景,相对来说写的操作比较少。它的优点在于成宿实现,不存在死锁问题,不过适用场景也会相对乐观,因为它阻止不了除了程序以外的数据库操作。
- 悲观锁适合写操作多的场景,因为写的操作具有排它性。采用悲观锁的方式,可以在数据库层面阻止其他事务对该数据的操作权限,防止读-写和写-写的冲突。
MVCC
MVCC的英文全称是Multiversion Concurrency Control)多版本并发空置技术。
通过MVVC可以解决一下问题:
- 读写之间阻塞的问题,通过MVCC可以让读写互相不阻塞,即读不阻塞写,写不阻塞读,这样就可以提升事务并发处理能力。
- 降低死锁的概率。这是因为MVCC采用了乐观锁的方式,读取数据时并不需要加锁,对于写操作,也只锁定必要的行。
- 解决一致性读问题。一致性读也被称为快照读,当查询数据库在某个时间点快照时,只能看到这个时间点之前事务更新的结果,而不能看到这个时间点之后事务提交的更新结果。
- 快照读读取的是快照数据。不加锁的简单的SELECT都属于快照读。
- 当前读就是读取最新数据,而不是历史版本的数据。加锁的SELECT,或者对数据进行增删查改都会进行当前读。
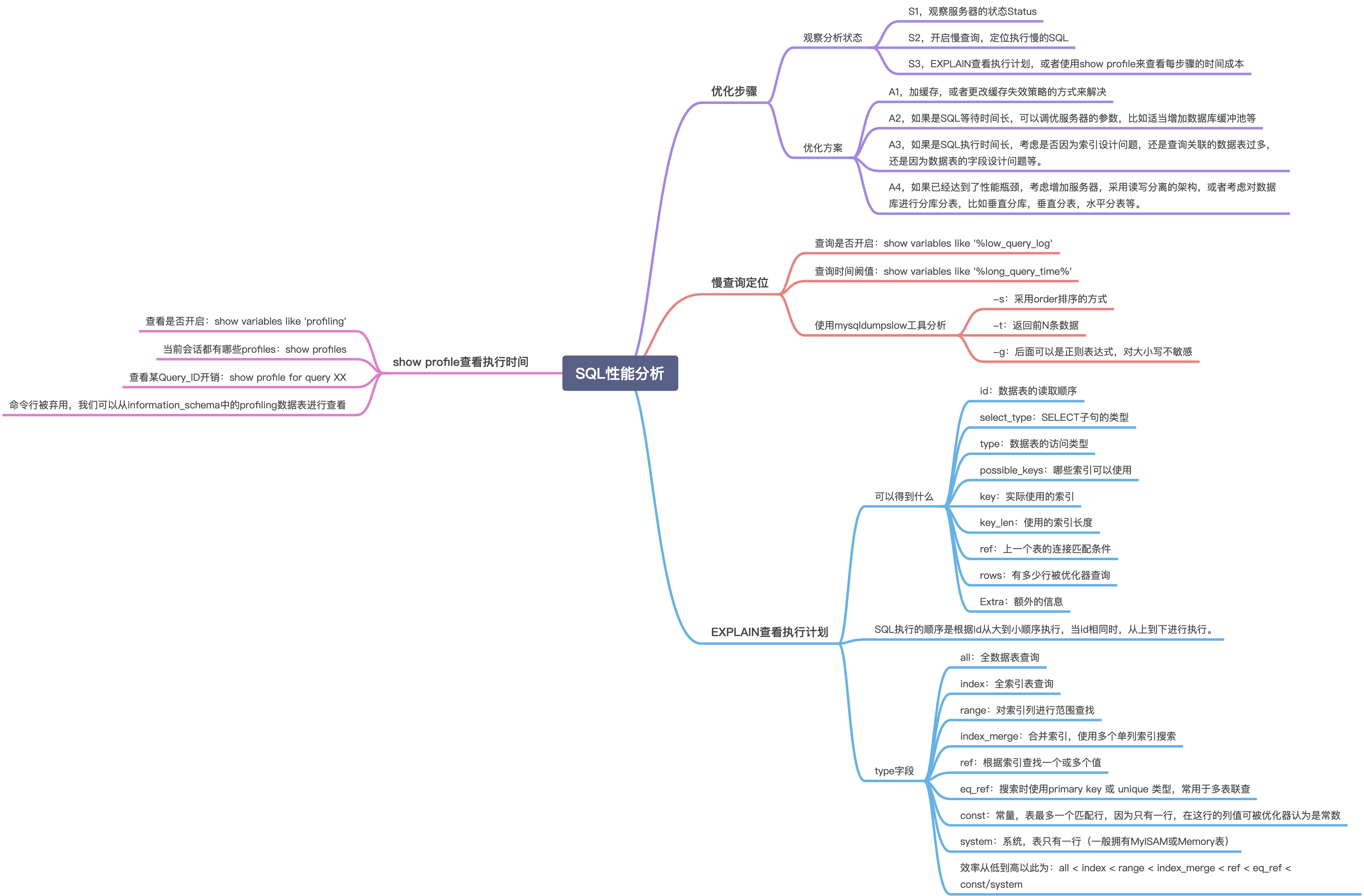
SQL性能分析
初始Redis
Redis属于键值(key - value)数据库,键值数据库会使用哈希表存储键值和数据,其中key作为唯一的标识,而且key和value可以是任何的内容,不论是简单的对象还是复杂的对象都可以存储。键值数据库的查询性能高,易于扩展。
为什么这么快?
Redis采用ANSI C语言编写,它和SQLite一样。
- 采用C语言进行编写的好处是底层代码执行效率高,依赖性低。因为C语言开发的库没有太多运行时(Runtime)依赖,而且系统的兼容性好,稳定性高。
- Redis是基于内存的数据库,这样可以避免磁盘I/O,因此Redis也被称为缓存工具。
- Redis采用key - value方式存储,数据结构简单,也就是使用Hash结构进行操作,数据的操作复杂度为O(1)。
Redis的数据类型
Redis支持的数据类型包括字符串、哈希、列表、集合、有序集合等。
字符串类型是Redis提供的最基本的数据类型,对应的结构是key - value。
set key value
get key
哈希(hash)提供了字段和字段值的映射,对应的结构是key - field - value
设置某个键的哈希值:hset key filed value
同时将多个filed - value设置给某个键key的:hmset key field value [filed value...]
获取某个键的某个field字段值:hget key field
一次获得某个键的多个field字段值:hmget key field[field...]
字符串列表(list)的底层是一个双向链表结构,可以向列表的两端添加元素,复杂度为O(1),同时也可以火球列表中的某个片段。
向列表列表左侧增加元素:LPUSH key value [...]
向列表右侧增加元素:RPUSH key value [...]
获取列表中某一片段的内容:LRANGE key start stop
字符串集合(set)是字符串类型的无序集合,与列表(list)的区别在于集合中的元素是无序的,同时元素不能重复。
集合中添加元素:SADD key member [...]
集合中删除某元素:SREM key member [...]
获取集合中所有的元素:SMEMBERS key
判断集合中是否存在某个元素:SISMEMBER key member
有序字符串集合(SortedSet,简称ZSET)理解成集合的升级版。ZSET是在集合的基础上增加了一个分数属性,这个属性在添加修改元素的时候可以被指定。每次指定后,ZSET都会按照分数来进行自动排序。
有序结合中添加元素和分数:ZADD key score member [...]
获取某个元素的分数:ZSCORE key member
删除一个或多个元素:ZREM key member[member...]
获取某个范围的元素列表(分数从小到大进行排序):ZRANGE key start stop[WITHCORES]
Redis的事务处理机制
Redis的事务处理机制与RDBMS的事务有一些不同。
- Redis不支持事务的回滚机制(Rollback)。当事务发生了错误(只要不是语法错误),整个事务依然会继续执行下去,直到事务队列中所有命令都执行完毕。
- Redis是内存数据库,与基于文件的RDBMS不同,通常只进行内存计算和操作,无法保证持久性。不过Redis提供了两种持久化模式,分别是RDB模式和AOF模式。
- RDB(Redis DataBase)持久化可以把当前进程的数据生成快照保存到磁盘上,触发RDB持久化的方式分为手动触发和自动触发。因为持久化操作与命令操作不是同步进行的,所以无法保证事务的持久性。
- AOF(Append Only Field)持久化采用日志的形式记录每个写操作,弥补了RDB在数据一致性上的不足,但是采用AOF模式,就意味着每条执行命令都需要写入文件中,会大大降低Redis的访问性能。
启动AOF模式需要手动开启,有3种不同的配置方式,默认为everysec,也就是每秒同步一次。其次还有always和no模式,分别代表只要有数据发生修改就会写入AOF文件,以及由操作系统决定什么时候记录到AOF文件中。
Redis的事务处理命令
- MULTI:开启一个事务;
- EXEC:事务执行,将一次性执行事务内的所有命令;
- DISCARD:取消事务;
- WATCH:监视一个或多个键,如果事务执行前某个键发生了改动,那么事务也会被打断;
- UNWATCH:取消WATCH命令对所有键的监视。
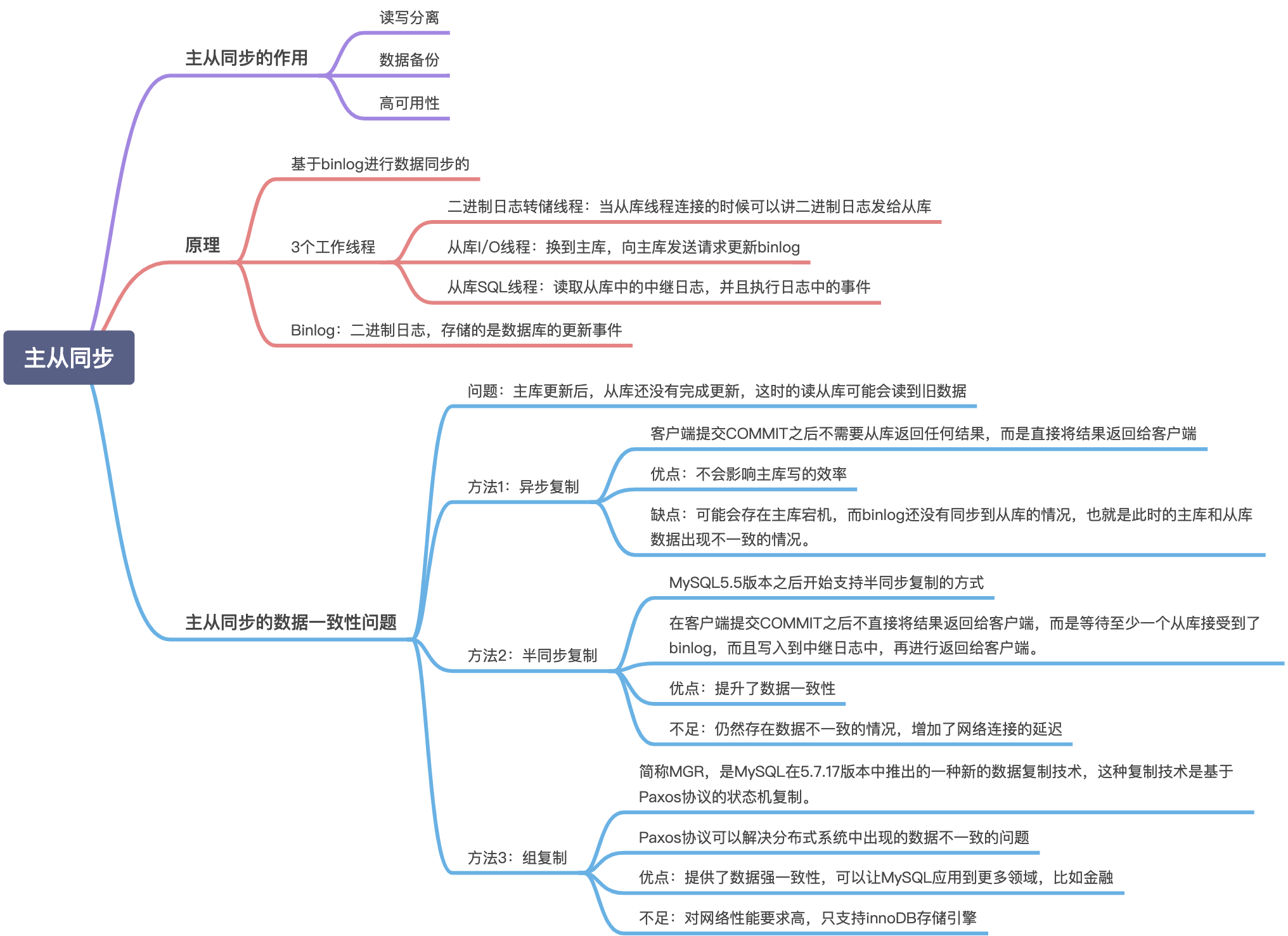
主从同步
SQL必知必会 —— 性能优化篇的更多相关文章
- SQL必知必会,带你系统学习
你一定听说过大名鼎鼎的Oracle.MySQL.MongoDB等,这些数据库都是基于一个语言标准发展起来的,那就是SQL. SQL可以帮我们在日常工作中处理各种数据,如果你是程序员.产品经理或者是运营 ...
- 读书笔记汇总 - SQL必知必会(第4版)
本系列记录并分享学习SQL的过程,主要内容为SQL的基础概念及练习过程. 书目信息 中文名:<SQL必知必会(第4版)> 英文名:<Sams Teach Yourself SQL i ...
- 读书笔记--SQL必知必会18--视图
读书笔记--SQL必知必会18--视图 18.1 视图 视图是虚拟的表,只包含使用时动态检索数据的查询. 也就是说作为视图,它不包含任何列和数据,包含的是一个查询. 18.1.1 为什么使用视图 重用 ...
- SQL 必知必会
本文介绍基本的 SQL 语句,包括查询.过滤.排序.分组.联结.视图.插入数据.创建操纵表等.入门系列,不足颇多,望诸君指点. 注意本文某些例子只能在特定的DBMS中实现(有的已标明,有的未标明),不 ...
- 《SQL必知必会》学习笔记二)
<SQL必知必会>学习笔记(二) 咱们接着上一篇的内容继续.这一篇主要回顾子查询,联合查询,复制表这三类内容. 上一部分基本上都是简单的Select查询,即从单个数据库表中检索数据的单条语 ...
- 《SQL必知必会》笔记
SQL必知必会(第4版) 作者:[美]Ben Forta 本书介绍了sql在不同数据库工具(Oracle.SQLite.SQL server.MySQL.MariaDB.PostgreSQL...)是 ...
- SQL 必知必会 总结(一)
SQL必知必会 总结(一) 第 1 课 了解SQL 1.数据库(database): 保存有组织的数据容器(通常是一个文件或一组文件). 2.数据库管理系统(DBMS): 数据库软件,数据库是通过 D ...
- SQL必知必会 -------- SELECT、注释
主要是看<SQL必知必会>第四版的书,而写的一些SQL笔记,红色的是方便以后查询的sql语句,工作中主要是使用mysql数据库,所以笔记也是围绕mysql而写的. 下文调试的数据表sql语 ...
- 【SQL必知必会笔记(1)】数据库基础、SQL、MySQL8.0.16下数据库、表的创建及数据插入
文章目录 1.数据库基础 1.1 数据库(database) 1.2 表(table) 1.3 列和数据类型 1.4 行 1.5 主键 2.什么是SQL 3.创建后续练习所需数据库.表(MySQL8. ...
- 读书笔记--SQL必知必会--建立练习环境
书目信息 中文名:<SQL必知必会(第4版)> 英文名:<Sams Teach Yourself SQL in 10 Minutes - Fourth Edition> MyS ...
随机推荐
- 顶级开源项目 Sentry 20.x JS-SDK 设计艺术(Unified API篇)
SDK 开发 顶级开源项目 Sentry 20.x JS-SDK 设计艺术(理念与设计原则篇) 顶级开源项目 Sentry 20.x JS-SDK 设计艺术(开发基础篇) 顶级开源项目 Sentry ...
- 「视频小课堂」Logstash如何成为镇得住场面的数据管道(文字版)
视频地址 B站视频地址:Logstash如何成为镇得住场面的数据管道 公众号视频地址:Logstash如何成为镇得住场面的数据管道 知乎视频地址:Logstash如何成为镇得住场面的数据管道 内容 首 ...
- HDU(1420)Prepared for New Acmer(JAVA语言)【快速幂模板】
思路:快速幂裸题. //注意用long,否则会超范围 Problem Description 集训进行了将近2个礼拜,这段时间以恢复性训练为主,我一直在密切关注大家的训练情况,目前为止,对大家的表现相 ...
- Github 1.9K Star的数据治理框架-Amundsen
Amundsen的使命,整理有关数据的所有信息,并使其具有普遍适用性. 这是Amundsen官网的一句话,对于元数据的管理工作,复杂且繁琐.可用的工具很多各有千秋,数据血缘做的较好的应该是Apache ...
- 【故障公告】阿里云 RDS SQL Server 数据库实例 CPU 100% 引发全站故障
非常抱歉,今天 8:48 开始,我们使用的阿里云 RDS SQL Server 数据库实例突然出现 CPU 100% 问题,引发全站故障,由此给您带来麻烦,请您谅解. 发现故障后立即进行主备切换,和 ...
- Golang+Protobuf+PixieJS 开发 Web 多人在线射击游戏(原创翻译)
简介 Superstellar 是一款开源的多人 Web 太空游戏,非常适合入门 Golang 游戏服务器开发. 规则很简单:摧毁移动的物体,不要被其他玩家和小行星杀死.你拥有两种资源 - 生命值(h ...
- OGG-集成模式抽取与数据库参数streams_pool_size关系
一.学习目标 Oracle数据库,使用OGG集成模式抽取进程启动时,如果没有配置合理的streams_pool_size参数可能会过一段时间就报错abend! 那么我们如何配置这个参数的大小?如何计算 ...
- wap视频广告遇到的问题
最近在做一个wap端的视频广告,耗了很多心力在上面,仍旧做不好.没想到wap浏览器对video标签这么不友好.广告需要在原编辑视频播完后插入并自动播放. ios浏览器点击播放按钮后喜欢自动全屏播放,希 ...
- 如何自己设计一个类似dubbo的rpc框架?
(1)上来你的服务就得去注册中心注册吧,你是不是得有个注册中心,保留各个服务的信息,可以用zookeeper来做,对吧 (2)然后你的消费者需要去注册中心拿对应的服务信息吧,对吧,而且每个服务可能会存 ...
- 【NCRE】常见的网络入侵与攻击的基本方法
本节内容来自<全国计算机等级考试三级教程--网络教程>2020版 实训任务五. 因为一直记不住几个常见的DOS攻击,这里记录一下,顺便找个好方法记住.跟CTF关联以后这部分知识确实感触颇深 ...