Python 爬虫从入门到进阶之路(四)
之前的文章我们做了一个简单的例子爬取了百度首页的 html,我们用到的是 urlopen 来打开请求,它是一个特殊的opener(也就是模块帮我们构建好的)。但是基本的 urlopen() 方法不支持代理、cookie等其他的HTTP/HTTPS高级功能,所以我们需要用到 Python 的 opener 来自定义我们的请求内容。
具体步骤:
- 使用相关的
Handler处理器来创建特定功能的处理器对象; - 然后通过
build_opener()方法使用这些处理器对象,创建自定义opener对象; - 使用自定义的opener对象,调用
open()方法发送请求。
我们先来回顾一下使用 urlopen 获取百度首页的 html 代码实例:
# 导入urllib 库
import urllib.request # url 作为Request()方法的参数,构造并返回一个Request对象
request = urllib.request.Request("http://www.baidu.com")
# Request对象作为urlopen()方法的参数,发送给服务器并接收响应
response = urllib.request.urlopen(request)
# 类文件对象支持 文件对象的操作方法,如read()方法读取文件全部内容,返回字符串
html = response.read().decode("utf-8")
# 打印字符串
print(html)
接下来我们看一下使用 opener 的处理方式:
from urllib import request # 构建一个HTTPHandler 处理器对象,支持处理HTTP请求
http_handler = request.HTTPHandler() # 构建一个HTTPSHandler 处理器对象,支持处理HTTPS请求
# http_handler = request.HTTPSHandler() # 调用 request.build_opener()方法,创建支持处理HTTP请求的opener对象
opener = request.build_opener(http_handler) # 构建 Request请求
request = request.Request("http://www.baidu.com/") # 调用自定义opener对象的open()方法,发送request请求
response = opener.open(request) # 获取服务器响应内容
html = response.read().decode("utf-8") # 打印字符串
print(html)
在上面的第一段代码中,我们是通过直接 import urllib.request 来导入我们需要的包,这样当我们要使用时需要 urllib.request 来使用,第二段代码我们是通过 from urllib import request 来导入我们需要的包,这样当我们使用时直接 request 来使用就可以了。
第一段代码在前面的文章中我们已经说过了,这里就不多做解释了。
第二段代码中,我们使用了 opener 的方法来处理我们的请求,这样我们就可以对代理,cookie 等做进一步的操作,后续文章会讲到。最终结果如下:
在 http_handler = request.HTTPHandler() 中,我们还可以添加一个 debuglevel=1 参数,会将 Debug Log 打开,这样程序在执行的时候,会把收包和发包的报头在屏幕上自动打印出来,方便调试,有时可以省去抓包的工作。
代码如下:
from urllib import request # 构建一个HTTPHandler 处理器对象,支持处理HTTP请求
http_handler = request.HTTPHandler(debuglevel=1) # 构建一个HTTPHandler 处理器对象,支持处理HTTPS请求
# http_handler = request.HTTPSHandler(debuglevel=1) # 调用 request.build_opener()方法,创建支持处理HTTP请求的opener对象
opener = request.build_opener(http_handler) # 构建 Request请求
request = request.Request("http://www.baidu.com/") # 调用自定义opener对象的open()方法,发送request请求
response = opener.open(request) # 获取服务器响应内容
html = response.read().decode("utf-8") # 打印字符串
print(html)
输出结果如下:
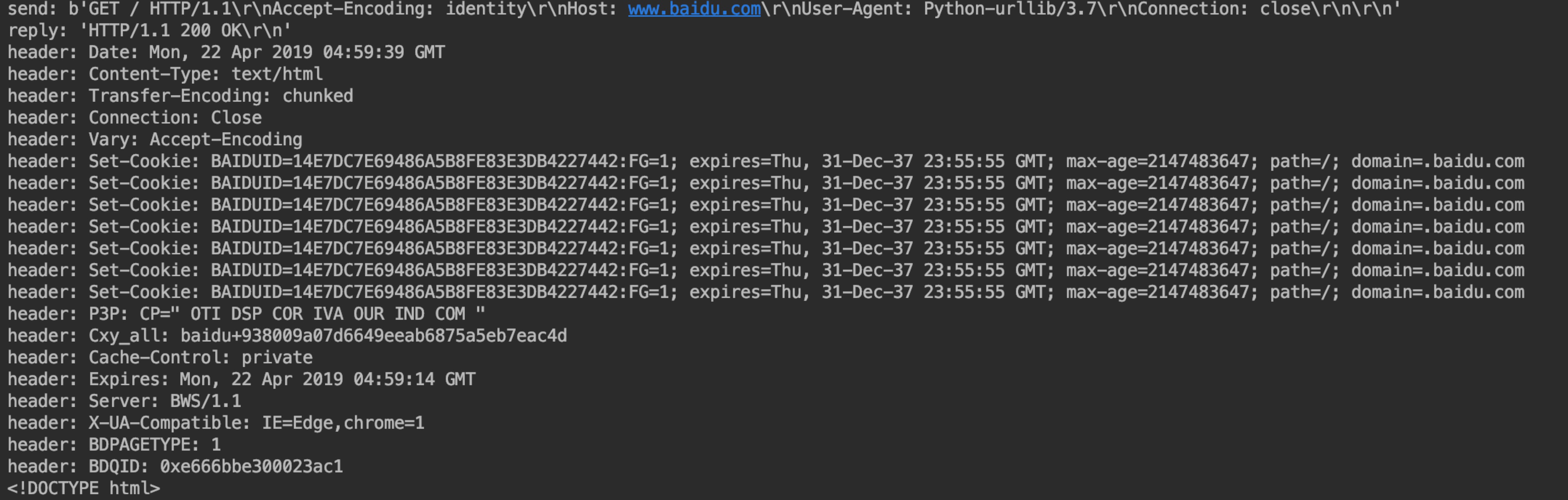
可以看出在响应结果的时候会为我们打印输出一些请求信息。
Python 爬虫从入门到进阶之路(四)的更多相关文章
- Python 爬虫从入门到进阶之路(八)
在之前的文章中我们介绍了一下 requests 模块,今天我们再来看一下 Python 爬虫中的正则表达的使用和 re 模块. 实际上爬虫一共就四个主要步骤: 明确目标 (要知道你准备在哪个范围或者网 ...
- Python 爬虫从入门到进阶之路(二)
上一篇文章我们对爬虫有了一个初步认识,本篇文章我们开始学习 Python 爬虫实例. 在 Python 中有很多库可以用来抓取网页,其中内置了 urllib 模块,该模块就能实现我们基本的网页爬取. ...
- Python 爬虫从入门到进阶之路(六)
在之前的文章中我们介绍了一下 opener 应用中的 ProxyHandler 处理器(代理设置),本篇文章我们再来看一下 opener 中的 Cookie 的使用. Cookie 是指某些网站服务器 ...
- Python 爬虫从入门到进阶之路(九)
之前的文章我们介绍了一下 Python 中的正则表达式和与爬虫正则相关的 re 模块,本章我们就利用正则表达式和 re 模块来做一个案例,爬取<糗事百科>的糗事并存储到本地. 我们要爬取的 ...
- Python 爬虫从入门到进阶之路(十二)
之前的文章我们介绍了 re 模块和 lxml 模块来做爬虫,本章我们再来看一个 bs4 模块来做爬虫. 和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也 ...
- Python 爬虫从入门到进阶之路(十五)
之前的文章我们介绍了一下 Python 的 json 模块,本章我们就介绍一下之前根据 Xpath 模块做的爬取<糗事百科>的糗事进行丰富和完善. 在 Xpath 模块的爬取糗百的案例中我 ...
- Python 爬虫从入门到进阶之路(十六)
之前的文章我们介绍了几种可以爬取网站信息的模块,并根据这些模块爬取了<糗事百科>的糗百内容,本章我们来看一下用于专门爬取网站信息的框架 Scrapy. Scrapy是用纯Python实现一 ...
- Python 爬虫从入门到进阶之路(十七)
在之前的文章中我们介绍了 scrapy 框架并给予 scrapy 框架写了一个爬虫来爬取<糗事百科>的糗事,本章我们继续说一下 scrapy 框架并对之前的糗百爬虫做一下优化和丰富. 在上 ...
- Python 爬虫从入门到进阶之路(五)
在之前的文章中我们带入了 opener 方法,接下来我们看一下 opener 应用中的 ProxyHandler 处理器(代理设置). 使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的. 很 ...
- Python 爬虫从入门到进阶之路(七)
在之前的文章中我们一直用到的库是 urllib.request,该库已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 “HTTP for Hum ...
随机推荐
- 一款 Postman 的开源替代品: Postwoman
1. 前言 大家都知道,Postman是一个非常受欢迎的API接口调试工具,提供有Chrome扩展插件版和独立的APP,不过它的很多高级功能都需要付费才能使用. 如果你连Postman都还没有用过,不 ...
- Oracle GoldenGate for Sql Server连接ODBC失败的处理方法
Oracle GoldenGate for Sql Server连接oracle数据库的时候还是比较容易的,命令行下面只要: GGSCI> dblogin useridalias [ alias ...
- 我的 FPGA 学习历程(15)—— Verilog 的 always 语句综合
在本篇里,我们讨论 Verilog 语言的综合问题,Verilog HDL (Hardware Description Language) 中文名为硬件描述语言,而不是硬件设计语言.这个名称提醒我们是 ...
- pip install pyspider失败的解决办法
td{ width:10000px } 报错 下载pycurl库 地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#pycurl 选择对应的python版本 ...
- web中状态码301和302的区别
web中状态码301和302的区别 总的区别就是:302重定向只是暂时的重定向,搜索引擎会抓取新的内容而保留旧的地址,因为服务器返回302,所以,搜索搜索引擎认为新的网址是暂时的.而301重定向是永久 ...
- 集合系列 Queue(十):LinkedList
我们之前在说到 List 集合的时候已经说过 LinkedList 了.但 LinkedList 不仅仅是一个 List 集合实现,其还是一个双向队列实现. public class LinkedLi ...
- 一致性hash算法--负载均衡
有没有好奇过redis.memcache等是怎么实现集群负载均衡的呢? 其实他们都是通过一致性hash算法实现节点调度的. 讲一致性hash算法前,先简述一下求余hash算法: hash(object ...
- linux服务器JDK1.8环境变量配置
1. 场景描述 软件老王年龄大了,新机器(Linxu)下,配置JDK环境变量老记不住,记录下,有需要的朋友参考下. 2. 解决方案 2.1 上传tar包 ftp上传tar包: jdk-8u181-li ...
- feign使用hystrix熔断的配置
熔断器hystrix 在分布式系统中,每个服务都可能会调用很多其他服务,被调用的那些服务就是依赖服务,有的时候某些依赖服务出现故障也是很正常的. Hystrix 可以让我们在分布式系统中对服务间的调用 ...
- How to: Change the Format Used for the FullAddress and FullName Properties 如何:更改用于FullAddress和FullName属性的格式
There are FullAddress and FullName properties in the Address and Person business classes that are su ...