Python3数据驱动ddt
对于同一个方法执行大量数据的程序时,我们可以采用ddt数据驱动的方式,来对数据规范化整理及输出
一、需要使用python的ddt库,ddt,data,unpack方法
1、仅使用ddt和data,代码如下
import unittest
from ddt import ddt, data, unpack test_data = (1, 2, 3)
@ddt # 需要在要引用的类前面加上 @ddt声明
class TestAdd(unittest.TestCase):
@data(test_data) # 调用ddt的数据
def test_add(self, a):
print(a)
test_add函数那里的形参a可以随便定义,程序会自动去接收 @data里面的值
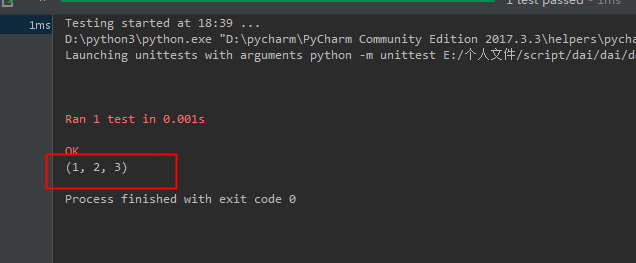
输出结果
2、使用unpack功能,此方法主要是拆分数据类型,例如元组(1, 2, 3),在data下面加上 unpack后,会将数据类型拆分为
"""元组、列表数据驱动"""
import unittest
from ddt import ddt, data, unpack test_data = ((1, 2, 3), (4, 5, 6), (7, 8, 9))
@ddt # 需要在要引用的类前面加上 @ddt声明
class TestAdd(unittest.TestCase):
@data(test_data) # 调用ddt的数据
@unpack
def test_add(self, a, b, c):
print('数据类型为', type(a), '数值为', a)
print('数据类型为', type(b), '数值为', b)
print('数据类型为', type(c), '数值为', c)
输出结果为:

会将test_data大元组拆分为,子类数值,并自动匹配数据类型。 例如将初始数据变为列表类型,并且列表里面的项未字符类型时
import unittest
from ddt import ddt, data, unpack #test_data = ((1, 2, 3), (4, 5, 6), (7, 8, 9))
test_data = ['A', 'B', 'C']
@ddt # 需要在要引用的类前面加上 @ddt声明
class TestAdd(unittest.TestCase):
@data(test_data) # 调用ddt的数据
@unpack
def test_add(self, a, b, c):
print('数据类型为', type(a), '数值为', a)
print('数据类型为', type(b), '数值为', b)
print('数据类型为', type(c), '数值为', c)
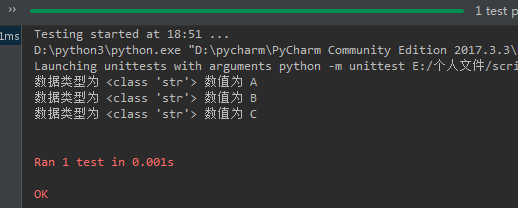
结果如下:
所以,ddt和data可以实现数据调用, unpack能对调用的大量数据进行拆分,得到最小等分的数据并进行使用。 注意,拆分之后的数据在函数test_data引用时,形参要和拆分的数量一致,即拆分了3个变量,那么我们调用函数的形参也必须是3个a,b,c (形参变量名不限,可以任意取,除了系统关键字)
二、对字典类型的数据进行数据驱动及拆分
字典是以键对值的形式来展示的,调用和拆分与列表、元组一样。 唯一不同点,在调用函数引用时,形参必须是字典的键值
"""字典类型数据驱动"""
import unittest
from ddt import ddt, data, unpack test_data = {"tall": 180, "sex": "boy"}
@ddt
class TestAdd(unittest.TestCase):
@data(test_data)
@unpack
def test_add(self, tall, sex): # 此处的形参必须要是字典的键值
print("身高是", tall, "性别是", sex)
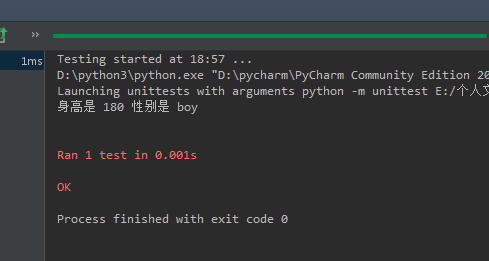
运行结果:
三、拓展使用
我们在进行数据驱动时,一般是从excel中读取数据,然后引用。 excel中的数据读取
from openpyxl import load_workbook class ReadExcel: # 读取Excel里面的内容
def __init__(self, file_name, sheet_name):
self.file_name = file_name
self.sheet_name = sheet_name def get_title(self): # 读取Excel里面的title数据
wb = load_workbook(self.file_name) # 打开Excel工作簿
sheet1 = wb[self.sheet_name]
title = [] # 定义一个空列表,将读取的title字段进行存储
for i in range(1, sheet1.max_column+1):
title.append(sheet1.cell(1, i).value)
return title def do_excel(self):
wb = load_workbook(self.file_name)
sheet1 = wb[self.sheet_name]
title = self.get_title() # 调用title内容
all_data = []
for j in range(2, sheet1.max_row+1): # 获取最大行数,加入循环
row_data={}
for i in range(3, sheet1.max_column+1): # 获取最大列数,进行嵌套循环
row_data[title[i-1]] = sheet1.cell(j, i).value # 把拿到的数据进行字典的键对值匹配
all_data.append(row_data)
return all_data
然后ddt进行引用即可
Python3数据驱动ddt的更多相关文章
- python webdriver 测试框架-数据驱动DDT的例子
先在cmd环境 运行 pip install ddt 安装数据驱动ddt模块 脚本: #encoding=utf-8 from selenium import webdriver import un ...
- Python 数据驱动ddt 使用
准备工作: pip install ddt 知识点: 一,数据驱动和代码驱动: 数据驱动的意思是 根据你提供的数据来测试的 比如 ATP框架 需要excel里面的测试用例 代码驱动是必须得写代码 ...
- 数据驱动ddt
在设计用例的时候,有些用例操作过程是一样的,只是参数数据输入的不同,如果用例重复的去写操作过程会增加代码量,对于这种多组数据的测试用例,可以使用数据驱动设计模式,一组数据对应一个测试用例,用例自动加载 ...
- unittest使用数据驱动ddt
简介 ddt(data driven test)数据驱动测试:由外部数据集合来驱动测试用例,适用于测试方法不变,但需要大量变化的数据进行测试的情况,目的就是为了数据和测试步骤的分离 由于unittes ...
- Python数据驱动DDT的应用
在开始之前,我们先来明确一下什么是数据驱动,在百度百科中数据驱动的解释是:数据驱动测试,即黑盒测试(Black-box Testing),又称为功能测试,是把测试对象看作一个黑盒子.利用黑盒测试法进行 ...
- python接口自动化测试 - 数据驱动DDT模块的简单使用
DDT简单介绍 名称:Data-Driven Tests,数据驱动测试 作用:由外部数据集合来驱动测试用例的执行 核心的思想:数据和测试代码分离 应用场景:一组外部数据来执行相同的操作 优点:当测试数 ...
- unittest---unittest数据驱动(ddt)
在做测试的时候,有些地方无论是接口还是UI只是参数数据的输入不一样,操作过程是一样的.重复去写操作过程会增加代码量,我们可以通过参数化的方式解决这个问题,也叫做数据驱动,我们通过python做参数化的 ...
- python之数据驱动ddt操作(方法三)
import unittestfrom selenium import webdriverfrom selenium.webdriver.common.by import Byimport unitt ...
- python之数据驱动ddt操作(方法二)
import unittestfrom ddt import ddt,unpack,datafrom selenium import webdriverfrom selenium.webdriver. ...
随机推荐
- 高并发 Nginx+Lua OpenResty系列(5)——Lua开发库Redis
Redis客户端 lua-resty-redis是为基于cosocket API的ngx_lua提供的Lua redis客户端,通过它可以完成Redis的操作.默认安装OpenResty时已经自带了该 ...
- 【设计模式】行为型07备忘录模式(Memento Pattern)
参考地址:http://www.runoob.com/design-pattern/memento-pattern.html 对原文总结调整,以及修改代码以更清晰的展示: 备忘录模式(快照模式): ...
- 阿里云ECS发送企业邮件
<?phpuse PHPMailer\PHPMailer\PHPMailer;require '../vendor/autoload.php'; $mail = new PHPMailer(tr ...
- CSS中属性的详细运用(新手必看)
=不同的浏览器有不同的默认字体大小font-size 这里以谷歌浏览器为准字体大小为10px (其他浏览器是12px) 1.这里强调一个备注:属性继承 a 是特殊的,要改变a里面的颜色,必须在它后 ...
- J-link使用SWD下载的连线方式
手头有两块开发板,一个是F103ZET6,另一个是C8T6.后者开发板没有JTAG口,所以只能用SWD下载和调试程序. 有如下总结: 1.有些开发板对boot的电平有要求,网上说boot0要接高电平. ...
- 分析了16年的福利彩票记录,原来可以用Python这么买彩票
目录 0 引言 1 环境 2 需求分析 3 代码实现 4 后记 0 引言 上周被一则新闻震惊到了,<2454万元大奖无人认领!福彩史上第二大弃奖在广东中山产生 >,在2019年5月2日开奖 ...
- 使用SpringSecurity搭建授权认证服务(1) -- 基本demo认证原理
使用SpringSecurity搭建授权认证服务(1) -- 基本demo 登录认证是做后台开发的最基本的能力,初学就知道一个interceptor或者filter拦截所有请求,然后判断参数是否合理, ...
- spark入门(四)日志配置
1 背景 在测试spark计算时,将作业提交到yarn(模式–master yarn-cluster)上,想查看print到控制台这是很难的,因为作业是提交到yarn的集群上,所以,去yarn集群上看 ...
- JVM中有哪些内存区域,分别是用来干什么的
前言 之前我们探讨过一个.class文件是如何被加载到jvm中的.但是jvm内又是如何划分内存的呢?这个内被加载到了那一块内存中?jvm内存划分也是面试当中必被问到的一个面试题. 什么是jvm内存区域 ...
- 你懂什么叫js继承吗
说到继承呢?肯定有很多做java的朋友都觉得是一个比较简单的东西了.毕竟面向对象的三大特征就是:封装.继承和多态嘛.但是真正对于一个javascript开发人员来说,很多时候其实你使用了继承,但其实你 ...