为什么spark中只有ALS
--Ethan Rosenthal
ALS的意思是交替最小二乘法(Alternating Least Squares),它只是是一种优化算法的名字,被用在求解spark中所提供的推荐系统模型的最优解。spark中协同过滤的文档中一开始就说了,这是一个基于模型的协同过滤(model-based CF),其实它是一种近几年推荐系统界大火的隐语义模型中的一种。隐语义模型又叫潜在因素模型,它试图通过数量相对少的未被观察到的底层原因,来解释大量用户和产品之间可观察到的交互。操作起来就是通过降维的方法来补全用户-物品矩阵,对矩阵中没有出现的值进行估计。基于这种思想的早期推荐系统常用的一种方法是SVD(奇异值分解)。该方法在矩阵分解之前需要先把评分矩阵R缺失值补全,补全之后稀疏矩阵R表示成稠密矩阵R',然后将R’分解成如下形式:
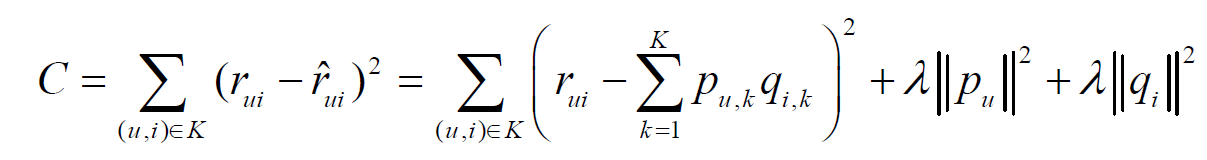
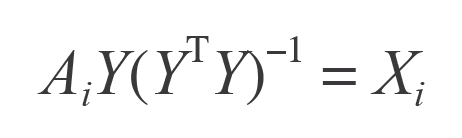
我们知道,在推荐系统中用户和物品的交互数据分为显性反馈和隐性反馈数据的。在ALS中这两种情况也是被考虑了进来的,分别可以训练如下两种模型:
val model1 = ALS.train(ratings, rank, numIterations, lambda)//显性反馈模型val model2 = ALS.trainImplicit(ratings, rank, numIterations, lambda, alpha)//隐性反馈模型
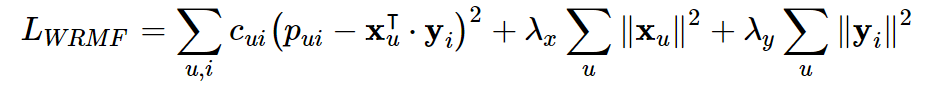
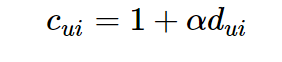
model.recommendProducts(userID, N)
model.predict(user, item)model.predict(RDD[int, int])
model.productFeaturesmodel.userFeatures
1.《spark机器学习》
为什么spark中只有ALS的更多相关文章
- Spark中常用的算法
Spark中常用的算法: 3.2.1 分类算法 分类算法属于监督式学习,使用类标签已知的样本建立一个分类函数或分类模型,应用分类模型,能把数据库中的类标签未知的数据进行归类.分类在数据挖掘中是一项重要 ...
- 推荐系统-协同过滤在Spark中的实现
作者:vivo 互联网服务器团队-Tang Shutao 现如今推荐无处不在,例如抖音.淘宝.京东App均能见到推荐系统的身影,其背后涉及许多的技术.本文以经典的协同过滤为切入点,重点介绍了被工业界广 ...
- Spark中常用工具类Utils的简明介绍
<深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 <深入理解Spark:核心思想与源码分析> ...
- SPARK 中 DriverMemory和ExecutorMemory
spark中,不论spark-shell还是spark-submit,都可以设置memory大小,但是有的同学会发现有两个memory可以设置.分别是driver memory 和executor m ...
- Scala 深入浅出实战经典 第65讲:Scala中隐式转换内幕揭秘、最佳实践及其在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第61讲:Scala中隐式参数与隐式转换的联合使用实战详解及其在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载: 百度云盘:http://pan.baidu.com/s/1c0noOt ...
- Scala 深入浅出实战经典 第60讲:Scala中隐式参数实战详解以及在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第51讲:Scala中链式调用风格的实现代码实战及其在Spark中应用
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第48讲:Scala类型约束代码实战及其在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-64讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
随机推荐
- Ubuntu 磁盘挂载错误
一.错误 报错原因: 在删除或者复制移动时,磁盘或者u盘等外接硬件设备,忽然掉落(断掉,接口松动),在次挂载磁盘时就会出现错误 错误日志: $MFTMirr does not match $MFT ( ...
- 重启iis的命令是什么?三种简单的重启方式
第一种.界面操作 打开“控制面板”->“管理工具”->“服务”.找到“IIS Admin Service” 右键点击“重新启动” 弹出 “停止其它服务” 窗口,点击“是”. 第二种.Net ...
- JavaFX 集成 Sqlite 和 Hibernate 开发爬虫应用
目录 [隐藏] 0.1 前言: 0.2 界面 0.3 Maven 环境 0.4 项目结构 0.5 整合 Hibernate 0.5.1 SQLiteDialect.java 数据库方言代码 0.5.2 ...
- 比特平面分层(一些基本的灰度变换函数)基本原理及Python实现
1. 基本原理 在灰度图中,像素值的范围为[0, 255],即共有256级灰度.在计算机中,我们使用8比特数来表示每一个像素值.因此可以提取出不同比特层面的灰度图.比特层面分层可用于图片压缩:只储存较 ...
- CSS3:pointer-events | a标签禁用
用纯css就能实现取消事件响应的方法,pointer-events,使用起来更加简单,它可以: pointer-events: auto | none | visiblePainted | visib ...
- React躬行记(13)——React Router
在网络工程中,路由能保证信息从源地址传输到正确地目的地址,避免在互联网中迷失方向.而前端应用中的路由,其功能与之类似,也是保证信息的准确性,只不过来源变成URL,目的地变成HTML页面. 在传统的前端 ...
- Mysql超详解
Mysql超详解 一.命令框基本操作及连接Mysql 找到Mysql安装路径,查看版本 同时按快捷键win+R会弹出一个框,在框中输入cmd 点击确定后会出现一个黑框,这是命令框,我们的操作要在这命令 ...
- HashMap源码分析之面试必备
今天我们就面试会问到关于HashMap的问题进行一个汇总,以及对这些问题进行解答. 1.HashMap的数据结构是什么? 2.为啥是线程不安全的? 3.Hash算法是怎样实现的? 4.HashMa ...
- 在linux系统下安装mysql详解,以及远程调用连接不上mysql的解决方法。
步骤: 1)查看CentOS自带的mysql 输入 rpm -qa | grep mysql 2)将自带的mysql卸载 3)上传Mysql的安装包到linux 4)安装mysql的依赖(不是必须) ...
- WebSocket和HTTP协议的区别
HTTP: 1,无状态协议. 2,短连接.(Ajax轮询方式或Long poll方式实现“持久连接”状态) 2,被动型. 客户端请求->服务器端响应.服务端不能主动联系客户端,只能有客户端发 ...