GCN和GCN在文本分类中应用
1.GCN的概念
传统CNN卷积可以处理图片等欧式结构的数据,却很难处理社交网络、信息网络等非欧式结构的数据。一般图片是由c个通道h行w列的矩阵组成的,结构非常规整。而社交网络、信息网络等是图论中的图(定点和边建立起的拓扑图)。
传统CNN卷积面对输入数据维度必须是确定的,进而CNN卷积处理后得到的输出数据的维度也是确定的。欧式结构数据中的每个点周边结构都一样,如一个像素点周围一定有8个像素点,即每个节点的输入维度和输出维度都是固定的。而非欧式结构数据则不一定,如社交网络中A和B是朋友,A有n个朋友,但B不一定有n个朋友,即每个节点的输入维度和输出维度都是不确定的。
所以不能使用CNN来对社交网络、信息网络等数据进行处理,因为对A节点处理后得到输出数据的维度和对B节点处理后得到输出数据维度是不一样的。为了得到社交网络、信息网络的空间特征所以我们使用GCN(Graph Convolutional Network)来处理。
2. GCN工作原理

图1 一个GCN的实例(图片来源网页[3])
同一般的卷积神经网络不同,GCN输入的数据是一个图拓扑矩阵,这个拓扑矩阵一般是图的邻接矩阵。
2.1 概念定义
| 概念 | 定义 |
|---|---|
| G | 一个拓扑图定义为G=(V,E) 其中V是节点集合,E是边集合。 |
| N | N是图中节点个数,即|V| |
| F | 节点的特征数,不同学习任务F不同 |
| X | 网络初始化矩阵, X是N行F列的矩阵 |
| D | 图的度矩阵,Dij表示点i和点j是否存在连接 |
| A | 图结构表征矩阵, A是N行N列的矩阵,A通常是G的邻接矩阵 |
| Hi | GCN中每层输出矩阵 Hi是一个N行F列矩阵 |
| Wi | GCN中每层权值矩阵 Wi是一个F行F列矩阵 |
2.2 GCN计算方式
在GCN中,第1层又H0 = X,从i层到i+1层网络计算其中一个简单传播规则,即传播规则1:
\[\begin{array}{l}
{{\bf{H}}^{i + 1}} = f\left( {{{\bf{H}}^i},{\bf{A}}} \right) \\
\quad \;\;\; = \sigma \left( {{\bf{A}}{{\bf{H}}^i}{{\bf{W}}^i}} \right) \\
\end{array}\]
其中激活函数σ一般为ReLu函数。尽然这个规则下GCN是一个简单模型,但已经足够强大,当然实际使用传播规则是下面几个:
传播规则2
\[\begin{array}{l}
{{\bf{H}}^{i + 1}} = f\left( {{{\bf{H}}^i},{\bf{A}}} \right) \\
\quad \;\;\; = \sigma \left( {{{\bf{D}}^{ - \frac{1}{2}}}{\bf{A}}{{\bf{D}}^{ - \frac{1}{2}}}{{\bf{H}}^i}{{\bf{W}}^i}} \right) \\
\end{array}\]
传播规则3
\[\begin{array}{l}
{{\bf{H}}^{i + 1}} = f\left( {{{\bf{H}}^i},{\bf{A}}} \right) \\
\quad \;\;\; = \sigma \left( {\left( {{\bf{I}} + {{\bf{D}}^{ - \frac{1}{2}}}{\bf{A}}{{\bf{D}}^{ - \frac{1}{2}}}} \right){{\bf{H}}^i}{{\bf{W}}^i}} \right) \\
\end{array}\]
传播规则4
\[\begin{array}{l}
{{\bf{H}}^{i + 1}} = f\left( {{{\bf{H}}^i},{\bf{A}}} \right) \\
\quad \;\;\; = \sigma \left( {{{\bf{D}}^{ - \frac{1}{2}}}\left( {{\bf{D}} - {\bf{A}}} \right){{\bf{D}}^{ - \frac{1}{2}}}{{\bf{H}}^i}{{\bf{W}}^i}} \right) \\
\end{array}\]
传播规则5
\[\begin{array}{l}
{{\bf{H}}^{i + 1}} = f\left( {{{\bf{H}}^i},{\bf{A}}} \right) \\
\quad \;\;\; = \sigma \left( {{{{\bf{\hat D}}}^{ - \frac{1}{2}}}{\bf{\hat A}}{{{\bf{\hat D}}}^{ - \frac{1}{2}}}{{\bf{H}}^i}{{\bf{W}}^i}} \right) \\
\end{array}\]
其中\({\bf{\hat A}}{\rm{ = }}{\bf{A}}{\rm{ + }}{\rm I}\),I是一个N×N的单位矩阵。而\({\bf{\hat D}}\)是\({\bf{\hat A}}\)
是一个对角线矩阵,其中${{\bf{\hat D}}{ii}} = \sum\limits_j {{{{\bf{\hat A}}}{ij}}} $。
最后根据不同深度学习任务来定制相应的GCN网络输出。
3 GCN在文本分类中的应用
3.1 文本分类常用算法
文本分类是自然语言处理比较常见的问题,常见的文本分类主要基于传统的cnn、lstm以及最近几年比较热门的transform、bert等方法,传统分类的模型主要处理排列整齐的矩阵特征,也就是很多论文中提到的Euclidean Structure,但是我们科学研究或者工业界的实际应用场景中,往往会遇到非Euclidean Structure的数据,如社交网络、信息网络,传统的模型无法处理该类数据,提取特征进一步学习,因此GCN 应运而生,本文主要介绍GCN在文本分类中的应用。
3.2 GCN在文本分类中具体应用
首先我们将我们的文本语料构建拓扑图,改图的节点由文档和词汇组成,即图中节点数|v|=|doc|+|voc| 其中|doc|表示文档数,|voc|表示词汇总量,对于特征矩阵X,我们采用单位矩阵I表示,即每个节点的向量都是one-hot形式表示,下面我们将介绍如何定义邻接矩阵A,其公式如所示,对于文档节点和词汇节点的权重,我们采用TF-IDF表示,对于词汇节点之间的权重,我们采用互信息表示(PMI, point-wise mutual information),在实验中,PMI表现好于两个词汇的共现词汇数,其公式如所示:
\[{A_{ij}} = \left\{ \begin{array}{l}
{\rm{PMI}}\left( {i,j} \right)\quad \quad \quad \quad i和j是词语而且{\rm{PMI}}\left( {i,j} \right) > {\rm{0}} \\
{\rm{TF - IDF}}\left( {i,j} \right)\quad \;\;i是文档j是词语 \\
1\quad \quad \quad \quad \quad \quad \quad \;\;\;i = j \\
0\quad \quad \quad \quad \quad \quad \quad \;\;其他\\
\end{array} \right.\]

其中#W(i)表示在固定滑动窗口下词汇i出现的数量,#W(i, j)表示在固定滑动窗口下词汇i,j同时出现的数量,当PMI(i, j)为正数表示词汇i和词汇j有较强的语义关联性,当PMI(i, j)为负数的时候表示词汇i,j语义关联性较低,在构建完图后,我们代入GCN中,构建两层GCN,如下:

我们采用经典的交叉熵来定义损失函数:

其中YD表示带标签的文挡集合,Ydf 表示标注类别,Zdf为预测的类别。
下面介绍GCN在多个公开数据集上的实验结果,其中数据源为:
表1: Summary statistic of datasets

GCN在文本分类上的实验结果见表2。
表2: GCN在在文本分类上的实验结果
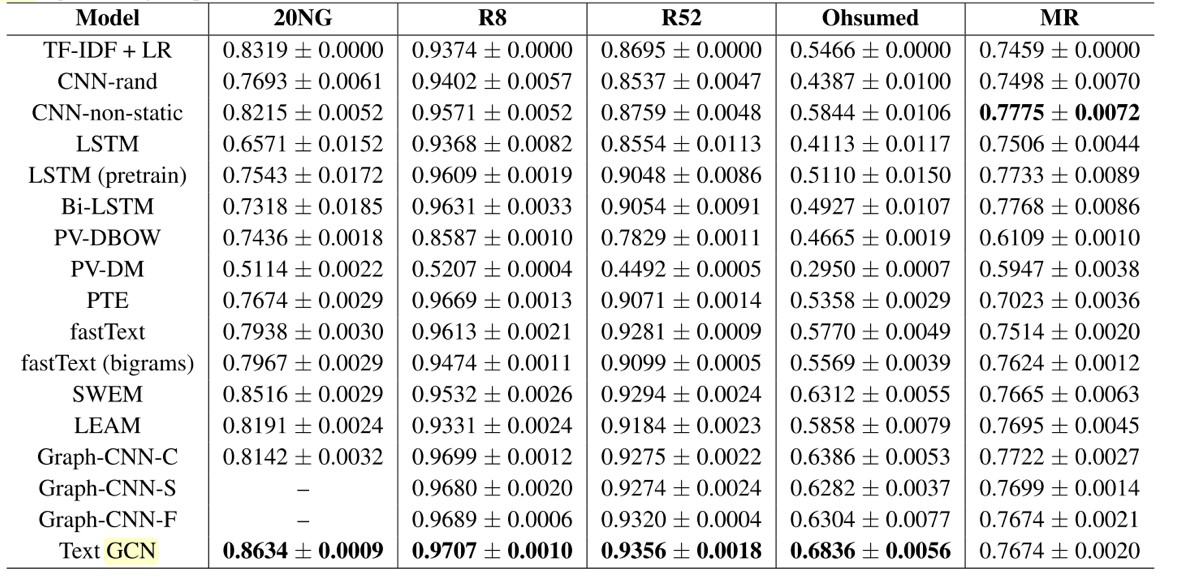
这种新颖的文本分类方法称为文本图卷积网络(Text-GCN),巧妙地将文档分类问题转为图节点分类问题。Text-GCN可以很好地捕捉文档地全局单词共现信息和利用好文档有限地标签。一个简单的双层Text-GCN已经取得良好地成果。
参考文献
[1] Kipf T N, Welling M. Semi-supervised classification with graph convolutional networks[J]. arXiv preprint arXiv:1609.02907, 2016.
[2] Yao L, Mao C, Luo Y. Graph convolutional networks for text classification[J]. arXiv preprint arXiv:1809.05679, 2018.
[3] http://tkipf.github.io/graph-convolutional-networks/
GCN和GCN在文本分类中应用的更多相关文章
- 文本图Tranformer在文本分类中的应用
原创作者 | 苏菲 论文来源: https://aclanthology.org/2020.emnlp-main.668/ 论文题目: Text Graph Transformer for Docum ...
- 小样本学习(few-shot learning)在文本分类中的应用
1,概述 目前有效的文本分类方法都是建立在具有大量的标签数据下的有监督学习,例如常见的textcnn,textrnn等,但是在很多场景下的文本分类是无法提供这么多训练数据的,比如对话场景下的意图识别, ...
- 文本分类实战(八)—— Transformer模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- CNN 文本分类
谈到文本分类,就不得不谈谈CNN(Convolutional Neural Networks).这个经典的结构在文本分类中取得了不俗的结果,而运用在这里的卷积可以分为1d .2d甚至是3d的. 下面 ...
- 文本分类学习 (八)SVM 入门之线性分类器
SVM 和线性分类器是分不开的.因为SVM的核心:高维空间中,在线性可分(如果线性不可分那么就使用核函数转换为更高维从而变的线性可分)的数据集中寻找一个最优的超平面将数据集分隔开来. 所以要理解SVM ...
- 用于文本分类的RNN-Attention网络
用于文本分类的RNN-Attention网络 https://blog.csdn.net/thriving_fcl/article/details/73381217 Attention机制在NLP上最 ...
- 【NLP_Stanford课堂】文本分类2
一.实验评估参数 实验数据本身可以分为是否属于某一个类(即correct和not correct),表示本身是否属于某一类别上,这是客观事实:又可以按照我们系统的输出是否属于某一个类(即selecte ...
- 基于Text-CNN模型的中文文本分类实战 流川枫 发表于AI星球订阅
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 基于Text-CNN模型的中文文本分类实战
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
随机推荐
- 【数据库】postgresql数据库创建自增序列id的注意事项
1.创建一张表 CREATE TABLE "public"."tt" ( "name" varchar(128), "status ...
- HTML--CSS样式表的基本概念
CSS(Cascading Style Sheet 叠层样式表) 作用:美化HTML网页 (一)样式表分类 一.内联样式表 和HTML联合显示,控制精准,但是可重用性差,冗余多. 例如:<p ...
- Mysql优化(出自官方文档) - 第三篇
目录 Mysql优化(出自官方文档) - 第三篇 1 Multi-Range Read Optimization(MRR) 2 Block Nested-Loop(BNL) and Batched K ...
- jquery实现最简单的下拉菜单
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...
- golang 任意类型之间相互转换
在处理一些参数的时候,可能需要将参数转换为各种类型,这里实现一个通用的转换函数,实现各种类型之间的相互转换. 当然,如果源数据格式和目标数据类型不一致,是会返回错误的.例如将字符串“一二三”转换为数值 ...
- 在 Windows 上使用 Python 进行 web 开发
本文由葡萄城技术团队于原创并首发 转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 上一篇我们介绍了在Windows 10下进行初学者入门开发Python的指 ...
- 用scrapy爬取搜狗Lofter图片
用scrapy爬取搜狗Lofter图片 # -*- coding: utf-8 -*- import json import scrapy from scrapy.http import Reques ...
- jquery 动态载入页面,并且保证 url 变动
最近做一个新的项目,项目页头,导航,页尾是不变的,只有中间部分是通过加载其他页面,达到内容刷新的. 大概结构如下, 要求, 1. 正文部分可以通过加载一个页面达到刷新效果 2. 保留加载的页面 url ...
- 5、数组的复制(test2.java、test3.java)
对于数组的复制,在最开始的时候最容易犯的一个错误,那就是自己认为的申请一个数组,然后将已存在的数组赋值到新申请数组名上,这样是错误的,这样仅仅是将数组的地址复制了过去,并不是,将数组内的元素拷贝过去, ...
- hadoop安装解决之道
# 壹.故障现象 ```xml Microsoft Windows [版本 10.0.18362.239] (c) 2019 Microsoft Corporation.保留所有权利. C:\User ...