scrapy实战4 GET方法抓取ajax动态页面(以糗事百科APP为例子):
一般来说爬虫类框架抓取Ajax动态页面都是通过一些第三方的webkit库去手动执行html页面中的js代码, 最后将生产的html代码交给spider分析。本篇文章则是通过利用fiddler抓包获取json数据分析Ajax页面的具体请求内容,找到获取数据的接口url,直接调用该接口获取数据,省去了引入python-webkit库的麻烦,而且由于一般ajax请求的数据都是结构化数据,这样更省去了我们利用xpath解析html的痛苦。
手机打开糗事百科APP ,利用fiddler抓包获取json数据 检查 得到的接口url是否能正常访问 如果能访问在换个浏览器试试 如图
打开之后的json数据如图推荐用json—handle插件(chrome安装)打开
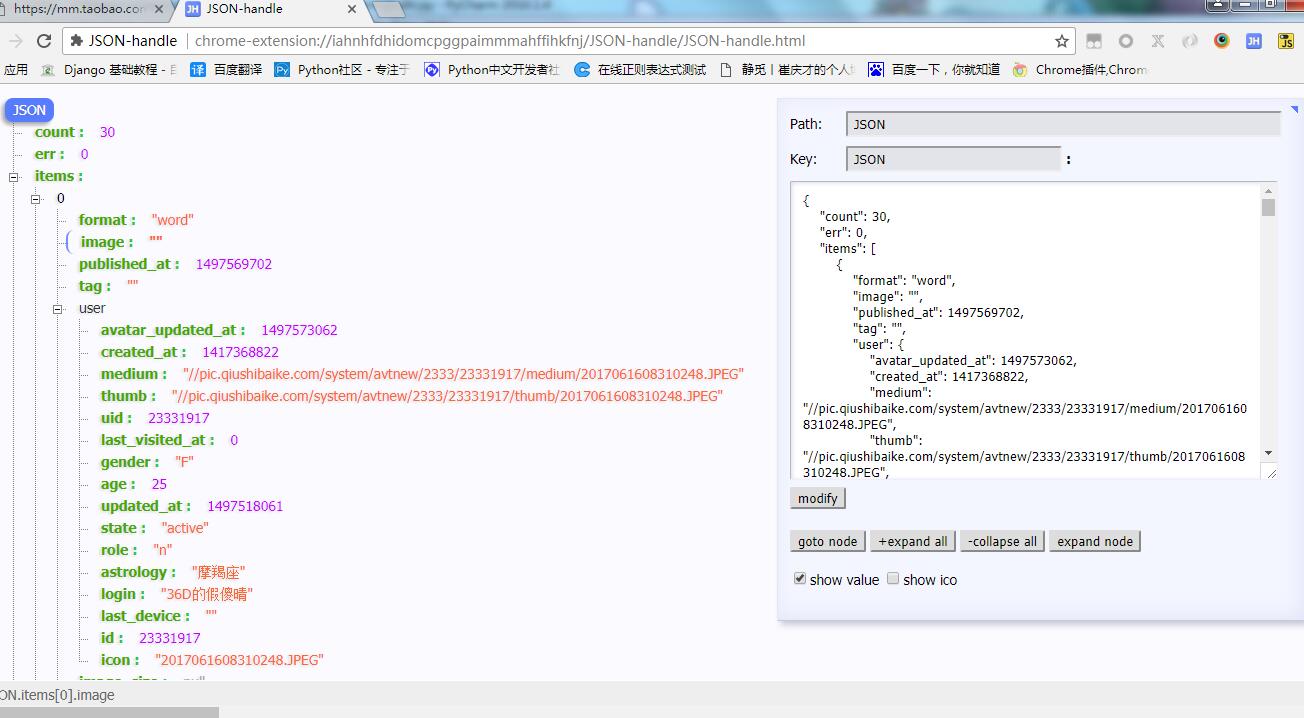
代码实现:以99页为例
items.py
import scrapy class QiushibalkeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
uid=scrapy.Field()
nickname = scrapy.Field()
gender=scrapy.Field() astrology=scrapy.Field() content=scrapy.Field()
crawl_time=scrapy.Field()
spiders/qiushi.py
# -*- coding: utf-8 -*-
import scrapy
import json
from qiushibalke.items import QiushibalkeItem
from datetime import datetime
class QiushiSpider(scrapy.Spider):
name = "qiushi"
allowed_domains = ["m2.qiushibaike.com"]
def start_requests(self):
for i in range(1,100):
url = "https://m2.qiushibaike.com/article/list/text?page={}".format(i)
yield scrapy.Request(url,callback=self.parse_item) def parse_item(self, response):
datas = json.loads(response.text)["items"]
print(datas)
for data in datas:
# print(data['votes']['up'])
# print(data['user']['uid'])
# print(data['user']["login"])
# print(data['user']["gender"])
# print(data['user']["astrology"]) item = QiushibalkeItem()
item["uid"]= data['user']["uid"] item["nickname"] = data['user']["login"]
item["gender"] = data['user']["gender"] item["astrology"] = data['user']["astrology"]
item["content"]=data["content"]
item["crawl_time"] = datetime.now() yield item
pipelines.py
import pymysql
class QiushibalkePipeline(object):
def process_item(self, item, spider):
con = pymysql.connect(host="127.0.0.1", user="youusername", passwd="youpassword", db="qiushi", charset="utf8")
cur = con.cursor()
sql = ("insert into baike(uid,nickname,gender,astrology,content,crawl_time)"
"VALUES(%s,%s,%s,%s,%s,%s)")
lis = (item["uid"],item["nickname"],item["gender"],item["astrology"],item["content"],item["crawl_time"])
cur.execute(sql, lis)
con.commit()
cur.close()
con.close() return item
settings.py
BOT_NAME = 'qiushibalke' SPIDER_MODULES = ['qiushibalke.spiders']
NEWSPIDER_MODULE = 'qiushibalke.spiders'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 5
COOKIES_ENABLED = False
DEFAULT_REQUEST_HEADERS = {
"User-Agent":"qiushibalke_10.13.0_WIFI_auto_7",
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
}
ITEM_PIPELINES = {
'qiushibalke.pipelines.QiushibalkePipeline': 300,
# 'scrapy_redis.pipelines.RedisPipeline':300,
}
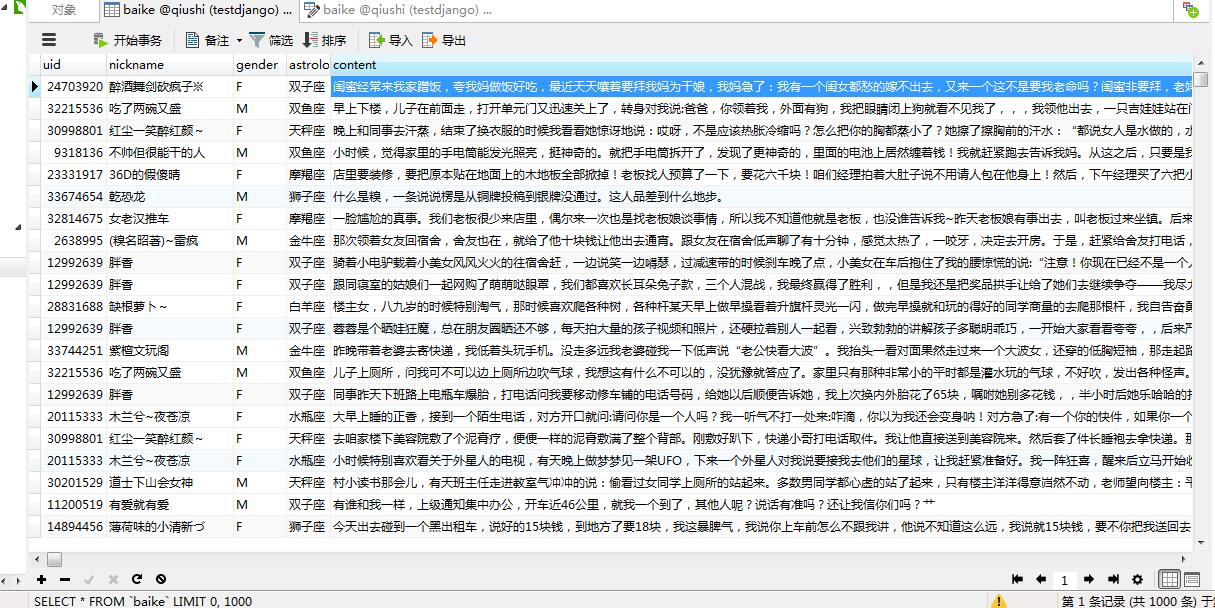
数据如图:
scrapy实战4 GET方法抓取ajax动态页面(以糗事百科APP为例子):的更多相关文章
- scrapy实战5 POST方法抓取ajax动态页面(以慕课网APP为例子):
在手机端打开慕课网,fiddler查看如图注意圈起来的位置 经过分析只有画线的page在变化 上代码: items.py import scrapy class ImoocItem(scrapy.It ...
- C#利用phantomJS抓取AjAX动态页面
在C#中,一般常用的请求方式,就是利用HttpWebRequest创建请求,返回报文.但是有时候遇到到动态加载的页面,却只能抓取部分内容,无法抓取到动态加载的内容. 如果遇到这种的话,推荐使用phan ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Python爬虫实战之爬取糗事百科段子【华为云技术分享】
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- 芝麻HTTP:Python爬虫实战之爬取糗事百科段子
首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致之前的代码没法用了,会导致无法输出和CPU占用过高的 ...
- Scrapy爬虫框架教程(四)-- 抓取AJAX异步加载网页
欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章 sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
随机推荐
- asp .net mvc 获得用户IP
string strHostName = System.Net.Dns.GetHostName(); //clientIPAddress是一个数组,可能有多个数据 var clientIPAddres ...
- XF 滑块和步进控件
<?xml version="1.0" encoding="utf-8" ?> <ContentPage xmlns="http:/ ...
- 赵伟国辞去TCL集团董事等职位,紫光参与TCL定增浮盈已超7亿
集微网消息,TCL 集团于8月9日晚间发布公告称,公司董事会于近日收到董事赵伟国先生的书面辞职报告,赵伟国先生因个人原因申请辞去公司董事及公司战略委员会委员职务.辞任后,赵伟国先生不再担任公司任何职务 ...
- c#代码安装字体文件
public class FontOperate { [DllImport("kernel32.dll", SetLastError = true)] static extern ...
- 恢复Win10照片查看器
批处理文件: @echo off&cd\&color 0a&cls echo 恢复Win10照片查看器 reg add "HKLM\SOFTWARE\Microsof ...
- Android多线程(一)
在Android应用的开发过程中,我们不可避免的要使用多线程,获取服务器数据.下载网络数据.遍历文件目录查找特定文件等等耗时的工作都离不开线程的知识.Android继承了Java的多线程体系,同时又实 ...
- 核心思想:许多公司都没有认识到云储存的革命性(类似QQ把它搞成了用户的家、再也离不开了)
在云储存刚刚兴起的时候,也就是dropbox刚刚进入大家视野的时候.许多人都是简单的认为这只是一个提供在线存储的服务而已,许多公司都没有认识到云储存的革命性. 对于这些大公司贸然进入一些新的领域是需要 ...
- [转]Android 如何有效的解决内存泄漏的问题
Android 如何有效的解决内存泄漏的问题 前言:最近在研究Handler的知识,其中涉及到一个问题,如何避免Handler带来的内存溢出问题.在网上找了很多资料,有很多都是互相抄的,没有实际的 ...
- 深入了解Windows句柄到底是什么(句柄是逻辑指针,或者是指向结构体的指针,图文并茂,非常清楚)good
总是有新入门的Windows程序员问我Windows的句柄到底是什么,我说你把它看做一种类似指针的标识就行了,但是显然这一答案不能让他们满意,然后我说去问问度娘吧,他们说不行网上的说法太多还难以理解. ...
- qt 自动重启(两种方法)
所谓自动重启就是程序自动关闭后在重新打开: 一般一个qt程序main函数如下: int main(int argc, char* argv[]) { QApplication app(argc, ar ...