从Excel到Python:最常用的36个Pandas函数
本文涉及pandas最常用的36个函数,通过这些函数介绍如何完成数据生成和导入、数据清洗、预处理,以及最常见的数据分类,数据筛选,分类汇总,透视等最常见的操作。
生成数据表
常见的生成数据表的方法有两种,第一种是导入外部数据,第二
种是直接写入数据。Excel中的“文件”菜单中提供了获取外部数据的功能,支持数据库和文本文件和页面的多种数据源导入。
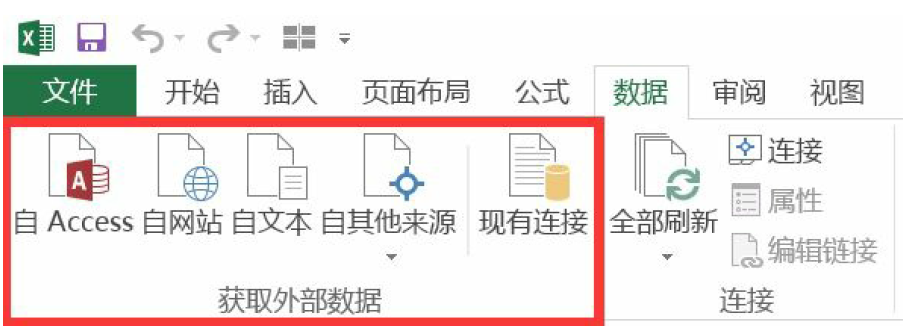
Python支持从多种类型的数据导入。在开始使用Python进行数据
导入前需要先导入pandas库,为了方便起见,我们也同时导入numpy
库.
import numpy as np
import pandas as pd
导入外部数据
df=pd.DataFrame(pd.read_csv('name.csv',header=1))
df=pd.DataFrame(pd.read_Excel('name.xlsx'))c
里面有很多可选参数设置,例如列名称、索引列、数据格式等
直接写入数据
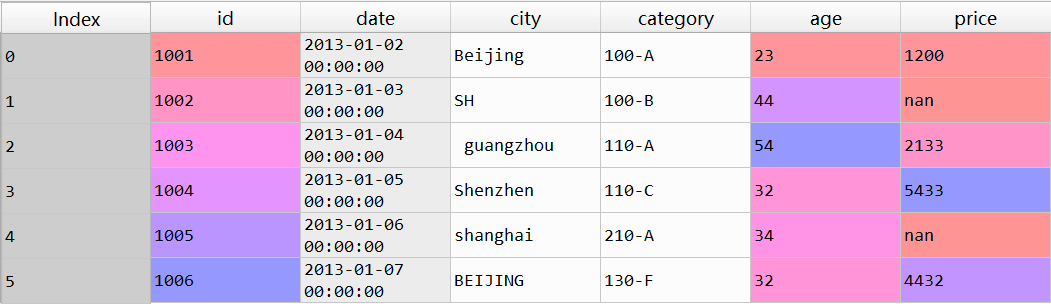
df = pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006],
"date":pd.date_range('20130102', periods=6),
"city":['Beijing ', 'SH', ' guangzhou ', 'Shen
zhen', 'shanghai', 'BEIJING '],
"age":[23,44,54,32,34,32],
"category":['100-A','100-B','110-A','110-C','2
10-A','130-F'],
"price":[1200,np.nan,2133,5433,np.nan,4432]},
columns =['id','date','city','category','age',
'price'])
数据表检查
数据表检查的目的是了解数据表的整体情况,获得数据表的关键信息、数据的概况,例如整个数据表的大小、所占空间、数据格式、是否有
空值和重复项和具体的数据内容,为后面的清洗和预处理做好准备。
1.数据维度(行列)
Excel中可以通过CTRL+向下的光标键,和CTRL+向右的光标键
来查看行号和列号。Python中使用shape函数来查看数据表的维度,也就是行数和列数。
df.shape
2.数据表信息
使用info函数查看数据表的整体信息,包括数据维度、列名称、数据格式和所占空间等信息。
数据表信息
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 6 columns):
id 6 non-null int64
date 6 non-null datetime64[ns]
city 6 non-null object
category 6 non-null object
age 6 non-null int64
price 4 non-null float64
dtypes: datetime64[ns](1), float64(1), int64(2), object(2)
memory usage: 368.0+ bytes
3.查看数据格式
Excel中通过选中单元格并查看开始菜单中的数值类型来判断数
据的格式。Python中使用dtypes函数来返回数据格式。

Dtypes是一个查看数据格式的函数,可以一次性查看数据表中所
有数据的格式,也可以指定一列来单独查看
#查看数据表各列格式
df.dtypes
id int64
date datetime64[ns]
city object
category object
age int64
price float64
dtype: object
#查看单列格式
df['B'].dtype
dtype('int64')
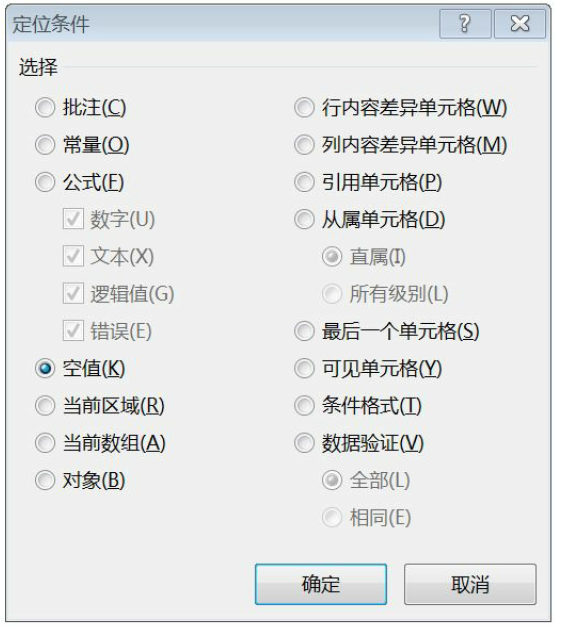
4.查看空值
Excel中查看空值的方法是使用“定位条件”在“开始”目录下的“查找和选择”目录.
Isnull是Python中检验空值的函数
#检查数据空值
df.isnull()

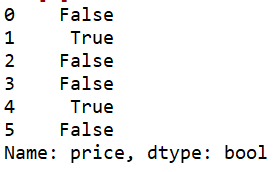
#检查特定列空值
df['price'].isnull()
5.查看唯一值
Excel中查看唯一值的方法是使用“条件格式”对唯一值进行颜色
标记。
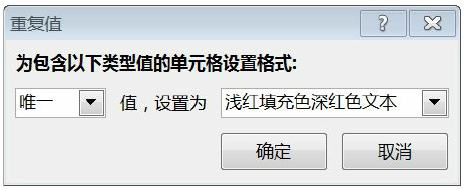
Python中使用unique函数查看唯一值。
#查看city列中的唯一值
df['city'].unique()
array(['Beijing ', 'SH', ' guangzhou ', 'Shenzhen', 'shanghai', '
BEIJING '], dtype=object)
6.查看数据表数值
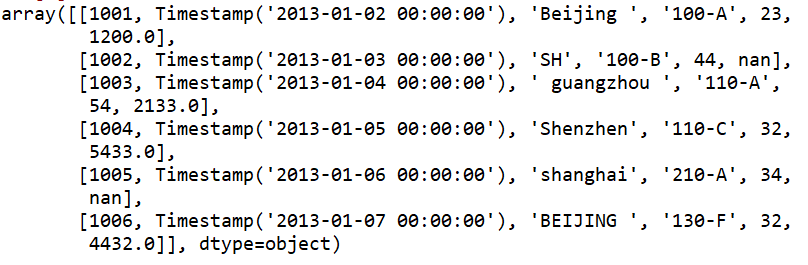
Python中的Values函数用来查看数据表中的数值
#查看数据表的值
df.values
7.查看列名称
Colums函数用来单独查看数据表中的列名称。
#查看列名称
df.columns
Index(['id', 'date', 'city', 'category', 'age', 'price'], dtype='
object')
8.查看前10行数据
Head函数用来查看数据表中的前N行数据
#查看前3行数据
df.head(3)
9.查看后10行数据
Tail行数与head函数相反,用来查看数据表中后N行的数据
#查看最后3行
df.tail(3)
数据表清洗
本章介绍对数据表中的问题进行清洗,包括对空值、大小写问题、数据格式和重复值的处理。
1.处理空值(删除或填充)
Excel中可以通过“查找和替换”功能对空值进行处理
Python中处理空值的方法比较灵活,可以使用 Dropna函数用来删除数据表中包含空值的数据,也可以使用fillna函数对空值进行填充。
#删除数据表中含有空值的行
df.dropna(how='any')

也可以使用数字对空值进行填充
#使用数字0填充数据表中空值
df.fillna(value=0)
使用price列的均值来填充NA字段,同样使用fillna函数,在要填充的数值中使用mean函数先计算price列当前的均值,然后使用这个均值对NA进行填充。
#使用price均值对NA进行填充
df['price'].fillna(df['price'].mean())
Out[8]:
0 1200.0
1 3299.5
2 2133.0
3 5433.0
4 3299.5
5 4432.0
Name: price, dtype: float64

2.清理空格
字符中的空格也是数据清洗中一个常见的问题
#清除city字段中的字符空格
df['city']=df['city'].map(str.strip)
3.大小写转换
在英文字段中,字母的大小写不统一也是一个常见的问题。
Excel中有UPPER,LOWER等函数,Python中也有同名函数用来解决
大小写的问题。
#city列大小写转换
df['city']=df['city'].str.lower()

4.更改数据格式
Excel中通过“设置单元格格式”功能可以修改数据格式。
Python中通过astype函数用来修改数据格式。
#更改数据格式
df['price'].astype('int')
0 1200
1 3299
2 2133
3 5433
4 3299
5 4432
Name: price, dtype: int32
5.更改列名称
Rename是更改列名称的函数,我们将来数据表中的category列更改为category-size。
#更改列名称
df.rename(columns={'category': 'category-size'})

6.删除重复值
Excel的数据目录下有“删除重复项”的功能
Python中使用drop_duplicates函数删除重复值
df['city']
0 beijing
1 sh
2 guangzhou
3 shenzhen
4 shanghai
5 beijing
Name: city, dtype: object
city列中beijing存在重复,分别在第一位和最后一位
drop_duplicates()函数删除重复值
#删除后出现的重复值
df['city'].drop_duplicates()
0 beijing
1 sh
2 guangzhou
3 shenzhen
4 shanghai
Name: city, dtype: object
设置keep='last‘’参数后,与之前删除重复值的结果相反,第一位
出现的beijing被删除
#删除先出现的重复值
df['city'].drop_duplicates(keep='last')
1 sh
2 guangzhou
3 shenzhen
4 shanghai
5 beijing
Name: city, dtype: objec
7.数值修改及替换
Excel中使用“查找和替换”功能就可以实现数值的替换
Python中使用replace函数实现数据替换
#数据替换
df['city'].replace('sh', 'shanghai')
0 beijing
1 shanghai
2 guangzhou
3 shenzhen
4 shanghai
5 beijing
Name: city, dtype: object
数据预处理
本章主要讲的是数据的预处理,对清洗完的数据进行整理以便后期的统计和分析工作。主要包括数据表的合并,排序,数值分列,数据分组及标记等工作。
1.数据表合并
在Excel中没有直接完成数据表合并的功能,可以通过VLOOKUP函数分步实现。
在Python中可以通过merge函数一次性实现。
#建立df1数据表
df1=pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006,1007,1008],
"gender":['male','female','male','female','male
','female','male','female'],
"pay":['Y','N','Y','Y','N','Y','N','Y',],
"m-point":[10,12,20,40,40,40,30,20]})

使用merge函数对两个数据表进行合并,合并的方式为inner,将
两个数据表中共有的数据匹配到一起生成新的数据表。并命名为
df_inner。
#数据表匹配合并
df_inner=pd.merge(df,df1,how='inner')

合并的方式还有left,right和outer方式
df_left=pd.merge(df,df1,how='left')
df_right=pd.merge(df,df1,how='right')
df_outer=pd.merge(df,df1,how='outer')
2.设置索引列
索引列可以进行数据提取,汇总,数据筛选
#设置索引列
df_inner.set_index('id')

3.排序(按索引,按数值)
Excel中可以通过数据目录下的排序按钮直接对数据表进行排
序

Python中需要使用ort_values函数和sort_index函数完成排序
#按特定列的值排序
df_inner.sort_values(by=['age'])

Sort_index函数用来将数据表按索引列的值进行排序。
#按索引列排序
df_inner.sort_index()

4.数据分组
Excel中可以通过VLOOKUP函数进行近似匹配来完成对数值的分组,或者使用“数据透视表”来完成分组
Python中使用Where函数用来对数据进行判断和分组
#如果price列的值>3000,group列显示high,否则显示low
df_inner['group'] = np.where(df_inner['price'] > 3000,'high','low
')

还可以对多个字段的值进行判断后对数据进行分组,下面的代码中对city列等于beijing并且price列大于等于4000的数据标记为1。
#对复合多个条件的数据进行分组标记
df_inner.loc[(df_inner['city'] == 'beijing') & (df_inner['price']
>= 4000), 'sign']=1

5.数据分列
Excel中的数据目录下提供“分列”功能。

在Python中使用split函数实现分列在数据表中category列中的数据包含有两个信息,前面的数字为类别id,后面的字母为size值。中间以连字符进行连接。我们使用split函数对这个字段进行拆分,并将拆分后的数据表匹配回原数据表中。
#对category字段的值依次进行分列,并创建数据表,索引值为df_inner的索引列,列名称为category和size
pd.DataFrame((x.split('-') for x in df_inner['category']),index=d
f_inner.index,columns=['category','size'])
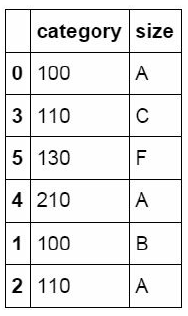
#将完成分列后的数据表与原df_inner数据表进行匹配
df_inner=pd.merge(df_inner,split,right_index=True, left_index=Tru
e)

数据提取
1.按标签提取(loc)
#按索引提取单行的数值
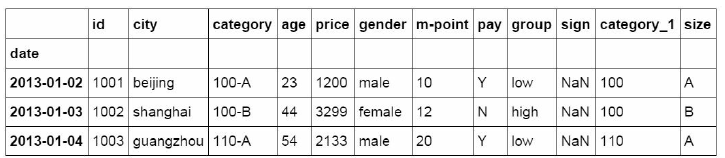
df_inner.loc[3]
id 1004
date 2013-01-05 00:00:00
city shenzhen
category 110-C
age 32
price 5433
gender female
m-point 40
pay Y
group high
sign NaN
category_1 110
size C
Name: 3, dtype: object
使用冒号可以限定提取数据的范围,冒号前面为开始的标签值后面为结束的标签值。
#按索引提取区域行数值
df_inner.loc[0:5]

Reset_index函数用于恢复索引,这里我们重新将date字段的日期
设置为数据表的索引,并按日期进行数据提取。
#重设索引
df_inner.reset_index()

#设置日期为索引
df_inner=df_inner.set_index('date')

#提取4日之前的所有数据
df_inner[:'2013-01-04']
2.按位置提取(iloc)
使用iloc函数按位置对数据表中的数据进行提取,这里冒号前后
的数字不再是索引的标签名称,而是数据所在的位置,从0开始。
#使用iloc按位置区域提取数据
df_inner.iloc[:3,:2]
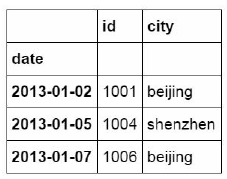
iloc函数除了可以按区域提取数据,还可以按位置逐条提取
#使用iloc按位置单独提取数据
df_inner.iloc[[0,2,5],[4,5]]
前面方括号中的0,2,5表示数据所在行的位置,后面方括号中的数表示所在列的位置。
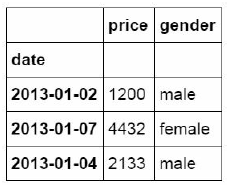
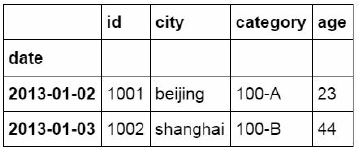
3.按标签和位置提取(ix)
ix是loc和iloc的混合,既能按索引标签提取,也能按位置进行数
据提取.
#使用ix按索引标签和位置混合提取数据
df_inner.ix[:'2013-01-03',:4]
4.按条件提取(区域和条件值)
使用loc和isin两个函数配合使用,按指定条件对数据进行提取
#判断city列的值是否为beijing
df_inner['city'].isin(['beijing'])
date
2013-01-02 True
2013-01-05 False
2013-01-07 True
2013-01-06 False
2013-01-03 False
2013-01-04 False
Name: city, dtype: bool
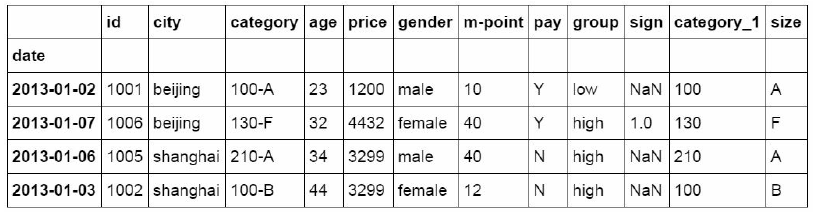
将isin函数嵌套到loc的数据提取函数中,将判断结果为Ture数据
提取出来。这里我们把判断条件改为city值是否为beijing和shanghai。如果是就把这条数据提取出来。
#先判断city列里是否包含beijing和shanghai,然后将复合条件的数据提取出来。
df_inner.loc[df_inner['city'].isin(['beijing','shanghai'])]
数据筛选
按条件筛选(与、或、非)
Excel数据目录下提供了“筛选”功能,用于对数据表按不同的条
件进行筛选。
Python中使用loc函数配合筛选条件来完成筛选功能。配合sum和count函数还能实现Excel中sumif和countif函数的功能。
使用“与”条件进行筛选,条件是年龄大于25岁,并且城市为
beijing。
#使用“与”条件进行筛选
df_inner.loc[(df_inner['age'] > 25) & (df_inner['city'] == 'beiji
ng'), ['id','city','age','category','gender']]/

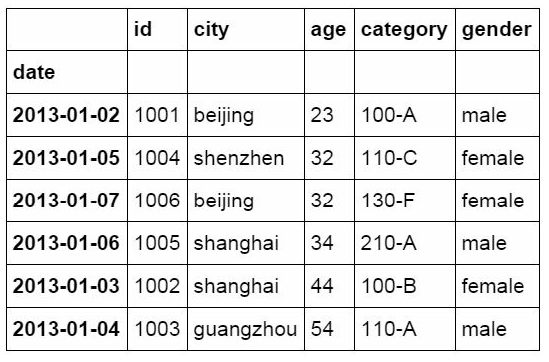
#使用“或”条件筛选
df_inner.loc[(df_inner['age'] > 25) | (df_inner['city'] == 'beiji
ng'), ['id','city','age','category','gender']].sort(['age'])
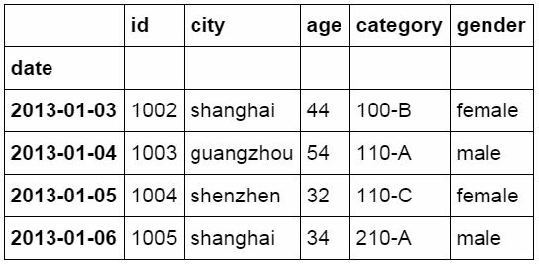
#使用“非”条件进行筛选
df_inner.loc[(df_inner['city'] != 'beijing'), ['id','city','age',
'category','gender']].sort(['id'])
在前面的代码后面增加city列,并使用count函数进行计数。相当于Excel中的countifs函数的功能
#对筛选后的数据按city列进行计数
df_inner.loc[(df_inner['city'] != 'beijing'), ['id','city','age',
'category','gender']].sort(['id']).city.count()
还有一种筛选的方式是用query函数
#使用query函数进行筛选
df_inner.query('city == ["beijing", "shanghai"]')

在前面的代码后增加price字段和sum函数。对筛选后的price字段
进行求和,相当于Excel中的sumifs函数的功能。
#对筛选后的结果按price进行求和
df_inner.query('city == ["beijing", "shanghai"]').price.sum()
12230
数据汇总
Excel中使用分类汇总和数据透视可以按特定维度对数据进行汇总,Python中使用的主要函数是groupby和pivot_table。
1.分类汇总
#对所有列进行计数汇总
df_inner.groupby('city').count()/

#对特定的ID列进行计数汇总
df_inner.groupby('city')['id'].count()
city
beijing 2
guangzhou 1
shanghai 2
shenzhen 1
Name: id, dtype: int64
#对两个字段进行汇总计数
df_inner.groupby(['city','size'])['id'].count()
city size
beijing A 1
F 1
guangzhou A 1
shanghai A 1
B 1
shenzhen C 1
Name: id, dtype: int64
还可以对汇总后的数据同时按多个维度进行计算
#对city字段进行汇总并计算price的合计和均值。
df_inner.groupby('city')['price'].agg([len,np.sum, np.mean])

2.数据透视

Python中通过pivot_table函数实现同样的效果
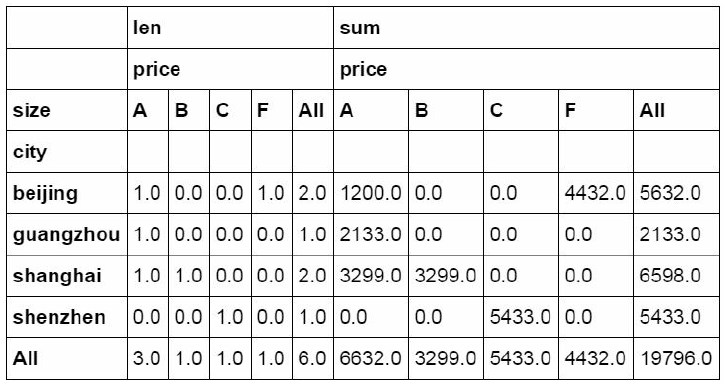
#设定city为行字段,size为列字段,price为值字段。
分别计算price的数量和金额并且按行与列进行汇总。
pd.pivot_table(df_inner,index=["city"],values=["price"],columns=[
"size"],aggfunc=[len,np.sum],fill_value=0,margins=True)
数据统计
1.数据采样
Excel的数据分析功能中提供了数据抽样的功能
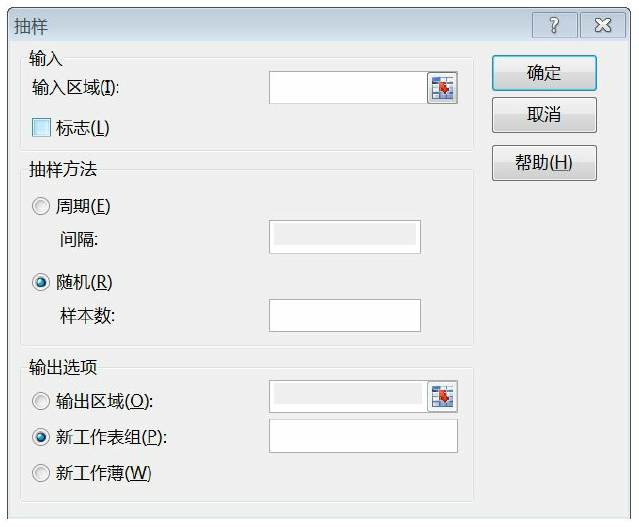
Python通过sample函数完成数据采样
#简单的数据采样
df_inner.sample(n=3)
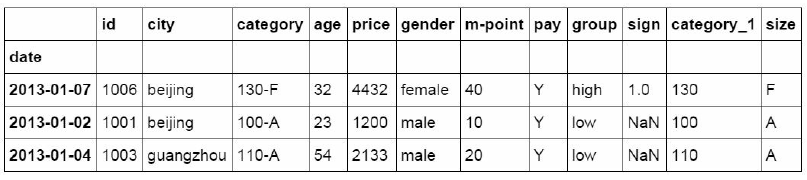
Weights参数是采样的权重,通过设置不同的权重可以更改采样的结果
#手动设置采样权重
weights = [0, 0, 0, 0, 0.5, 0.5]
df_inner.sample(n=2, weights=weights)
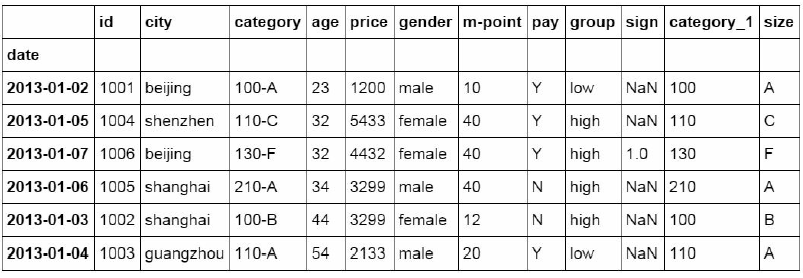
Sample函数中参数replace,用来设置采样后是否放回
#采样后不放回
df_inner.sample(n=6, replace=False)
#采样后放回
df_inner.sample(n=6, replace=True)
2.描述统计
Python中可以通过Describe对数据进行描述统计
#数据表描述性统计
df_inner.describe().round(2).T

3.相关分析
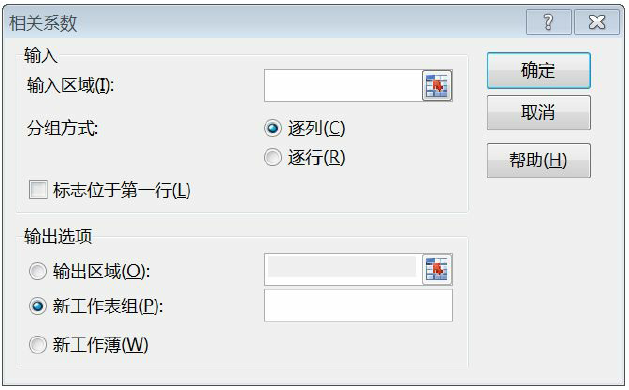
Python中则通过corr函数完成相关分析的操作,并返回相关系数。
#相关性分析
df_inner['price'].corr(df_inner['m-point'])
0.77466555617085264
#数据表相关性分析
df_inner.corr()

数据输出
1.写入Excel
#输出到Excel格式
df_inner.to_Excel('Excel_to_Python.xlsx', sheet_name='bluewhale_c
c')

2.写入csv
#输出到CSV格式
df_inner.to_csv('Excel_to_Python.csv')
参考
王彦平《从Excel到Python:数据分析进阶指南》

从Excel到Python:最常用的36个Pandas函数的更多相关文章
- python中常用得字符串,列表函数汇总
字符串函数: 1,replace函数,替换函数.s = s.replace(old,new),老得元素被新的元素替换.注意不能直接写s.replace(old,new).要写s=s.replace(o ...
- 【python】常用的一些内置函数
1.cmp cmp(A,B)函数,比较A,B的大小,如果A大于B,返回1,A小于B返回-1,A等于B返回0 print cmp(12,33) >>>-1 print cmp(&quo ...
- python基础12_匿名_内置函数
一个二分查找的示例: # 二分查找 示例 data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35, 36, ...
- 学习推荐《从Excel到Python数据分析进阶指南》高清中文版PDF
Excel是数据分析中最常用的工具,本书通过Python与Excel的功能对比介绍如何使用Python通过函数式编程完成Excel中的数据处理及分析工作.在Python中pandas库用于数据处理,我 ...
- python字符串常用内置方法
python字符串常用内置方法 定义: 字符串是一个有序的字符的集合,用与存储和表示基本的文本信息. python中引号中间包含的就是字符串. # s1='hello world' # s2=&quo ...
- Python的常用库
读者您好.今天我将介绍20个属于我常用工具的Python库,我相信你看完之后也会觉得离不开它们.他们是: Requests.Kenneth Reitz写的最富盛名的http库.每个Python程序员都 ...
- Python学习常用的好网站
以下总结出自己在学习python期间常用的网址或者资源,其中包括很多人的博客,方便自己从这个入口查找资源. 1.https://www.liaoxuefeng.com/wiki/00143160895 ...
- 《Python数据分析常用手册》一、NumPy和Pandas篇
一.常用链接: 1.Python官网:https://www.python.org/ 2.各种库的whl离线安装包:http://www.lfd.uci.edu/~gohlke/pythonlibs/ ...
- Python实现常用排序算法
Python实现常用排序算法 冒泡排序 思路: 它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完 ...
随机推荐
- django-URL之path标准语法(三)
path(route,vie,nane=None,**kwargs) route:表示路径,从端口以后URL的地址,到/结束.(必选) view:表示匹配成功后,需要调用的视图,view必须是个函数, ...
- ApplicationContextAware使用理解
接口的作用 当一个类实现了这个接口(ApplicationContextAware)之后,Aware接口的Bean在被初始之后,可以取得一些相对应的资源,这个类可以直接获取spring 配置文件中 所 ...
- Java对象"后事处理"那点事儿——垃圾回收(一)
1.Dead Or Alive 我们都知道对象死亡的时候需要进行垃圾回收来回收这些对象从而释放空间,那么什么样的对象算是死亡呢,有哪些方法可以找出内存中的死亡对象呢?一般来说,我们可以这样认为:如果内 ...
- Java自动化测试框架-08 - TestNG之并行性和超时篇 (详细教程)
一.并行性和超时 您可以指示TestNG以各种方式在单独的线程中运行测试. 可以通过在suite标签中使用 parallel 属性来让测试方法运行在不同的线程中.这个属性可以带有如下这样的值: 二.并 ...
- NOIP模拟 24
连续爆炸的开端. 从这一场开始我没状态了 T1 star way to heaven 受强降雨boboQQQ影响,我一直认为这是一道和凸包有关的计算几何题 很快就弃了,除了期望没做过带实数的题,所以吓 ...
- python私有变量的分类
- ElasticSearch(四):基本搜索
ElasticSearch(四):基本搜索 学习课程链接<Elasticsearch核心技术与实战> URI Search 使用HTTP的GET方法,在URL中使用查询参数进行查询. GE ...
- Project Euler 55: Lychrel numbers
五十五.吕克雷尔数(Lychrel numbers) 如果我们把\(47\)翻转过来并和其自身相加,结果是\(47+74=121\)是一个回文数.并不是所有的数都可以这么快的变成回文数,比如说: \[ ...
- python_day1(初始Python)
1.编码 ASCII (英文1字节,没中文)=> GB => GBK =>uncoode (中英文都2字节) => utf-8 (可变长字节储存,中文3字节,英文1字节) 2. ...
- c#数据结构之Array、ArrayList、List、LinkedList对比分析
一.前言: 在c#数据结构中,集合的应用非常广泛,无论是做BS架构还是CS架构开发,都离不开集合的使用,比如我们常见的集合包括:Array.ArrayList.List.LinkedList等.这一些 ...