05-pandas索引切片读取数据缺失数据处理
引入
numpy已经能够帮助我们处理数据,能够结合matplotlib解决我们数据分析的问题,那么pandas学习的目的在什么地方呢? numpy能够帮我们处理处理数值型数据,但是这还不够 很多时候,我们的数据除了数值之外,还有字符串,还有时间序列等 比如:我们通过爬虫获取到了存储在数据库中的数据 比如:之前youtube的例子中除了数值之外还有国家的信息,视频的分类(tag)信息,标题信息等 所以,numpy能够帮助我们处理数值,但是pandas除了处理数值之外(基于numpy),还能够帮助我们处理其他类型的数据。
什么是pandas?
pandas是一个Python软件包,提供快速,灵活和富于表现力的数据结构,旨在使使用“关系”或“标记”数据既简单又直观。它旨在成为在Python中进行实际,真实世界数据分析的基本高级构建块。此外,其更广泛的目标是成为任何语言中可用的最强大,最灵活的开源数据分析/操作工具。它已经朝着这个目标迈进了。
pandas的常用数据类型
1、Series 一维,带标签数组
2、DataFrame 二维,Series容器
(1)Series创建
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
data :类 数组,可迭代,字典或标量值,包含存储在系列中的数据。在0.23.0版中进行了更改:如果data是dict,则将为Python 3.6及更高版本维护参数顺序。
index :类 数组或索引(1d)值必须是可散列的,并且与data的长度相同。允许使用非唯一索引值。如果未提供,则默认为RangeIndex(0,1,2,…,n)。如果同时使用了字典和索引序列,则索引将覆盖在字典中找到的键。
dtype : STR,numpy.dtype,或ExtensionDtype,可选
输出系列的数据类型。如果未指定,则将从data推断出来。
copy: bool,默认为False,copy输入数据。
import pandas as pd
import numpy as np
t = pd.Series(np.arange(12),index= list("asdfghjklpoi"))
print(t)
print(type(t))

注意几个问题:pd.Series能干什么,能够传入什么数据类型让其变为series结构。index是什么,在什么位置,对于我们常见的数据库数据或者ndarray来说,index到底是什么如何给一组数据指定index。
c = {"name":"lishuntao","age":18,"gender":"boy"}
t1 = pd.Series(c)
print(t1)
print(type(t1))
print(t1["name"])
print(t1["gender"])
从上面可以看出,通过字典创建一个Series,字典的键就是索引。
重新给其绑定其他的索引之后,如果能够对应的上,就取其值,如果不能,就为Nan。如图所示:
import numpy as np
import pandas as pd a = {"a":12,"name":"lishuntao","c":"xiaoc","age":18,"gender":"man"} t1 = pd.Series(a)
print(t1)
print(type(t1))
t2 = pd.Series(a,index=list("abcdf"))
print(t2)
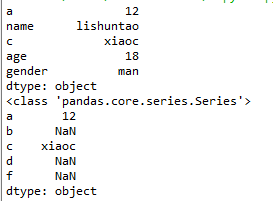
numpy中的nan为float,pandas会自动根据数据类型更改series的dtype类型。
Series切片和索引
import numpy as np
import pandas as pd a = {"a":12,"name":"lishuntao","c":"xiaoc","age":18,"gender":"man"} t1 = pd.Series(a)
print(t1)
print(t1[:2])
print(t1[1])
print(t1[["a","c","gender"]])
print(t1[0:5:2])
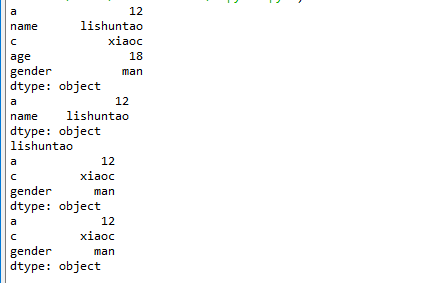
import numpy as np
import pandas as pd a = np.arange(12)
t1 = pd.Series(a)
print(t1)
print(t1[t1>9])

Series的索引和值
import numpy as np
import pandas as pd a = np.arange(12)
t1 = pd.Series(a)
#print(t1)
print(t1.index)
print(t1.values)

import numpy as np
import pandas as pd a = np.arange(12)
t1 = pd.Series(a)
print(t1)
print(type(t1.index))
print(type(t1.values))
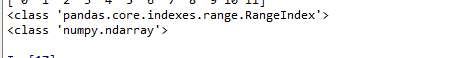
Series对象本质上有两个数组构成,一个数组构成对象的键(index,索引),一个数组构成对象的值(values),键--->值。
ndarray的很多方法都可以运用与series类型,比如argmax,clip
series具有where方法,但是结果却不同(下面是官方文档给出)
Series.where(self, cond[, other, inplace, …]) |
Replace values where the condition is False. |
a = np.arange(12)
t1 = pd.Series(a)
print(t1)
#替换条件是False的情况 下面两个结果一样
print(t1.where((t1>8),1))
print(pd.Series.where(t1,(t1>4),1))
pandas之读取外部数据
现在假设我们有一个组关于狗的名字的统计数据,那么为了观察这组数据的情况,我们应该怎么做呢?
数据来源:https://www.kaggle.com/new-york-city/nyc-dog-names/data
我们的这组数据存在csv中,我们直接使用pd. read_csv即可
import numpy as np
import pandas as pd
t2 = pd.read_csv("F:\BaiduNetdiskDownload\youtube_video_data\dogNames2.csv")
print(t2)
print(type(t2))
和我们想象的有些差别,他是一个DataFrame,那么接下来我们就来了解这种数据类型
但是,还有一个问题:
对于数据库比如mysql或者mongodb中数据我们如何使用呢?
pd.read_sql(sql_sentence,connection)
那么,mongodb呢?(先用mongodb自己读出来,然后将它传入到DataFrame中,就可以实现读取)
(2)DataFrame的创建
pd.DataFrame(data,index,columns,dtype,copy)
参数比Series多了columns,从中可以看出这是列索引(Index or array-like Column labels to use for resulting frame. Will default to RangeIndex (0, 1, 2, ..., n) if no column labels are provided)
import numpy as np
import pandas as pd
t2 = pd.DataFrame(np.arange(12).reshape(3,4))
print(t2)

从上面我们可以看出DataFrame对象既有行索引,又有列索引
行索引:表明不同行,横向索引,叫index,0轴,axis=0
列索引:表明不同列,纵向索引,叫columns,1轴,axis=1
自定义索引标签:
t2 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ"))
print(t2)
DataFrame的基础属性
t2 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ"))
print(t2)
print(t2.shape)#显示行数,列数
print(t2.dtypes)#显示的是列数据类型
print(t2.ndim)#数据维度2(0,1)
print(t2.index)#行索引
print(t2.columns)#列索引 Index(['W', 'X', 'Y', 'Z'], dtype='object')
print(t2.values)#对象值,二维ndarray的数组

DataFrame整体情况查询
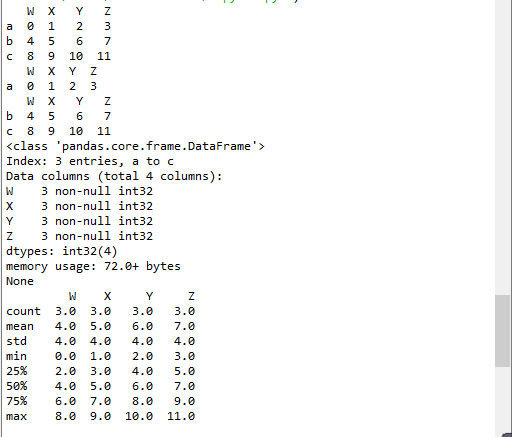
t2 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ"))
print(t2)
#print(t2.head())
print(t2.head(1))#显示头几行,默认5行
print(t2.tail(2))#显示末尾几行,默认5行
print(t2.info())#相关信息浏览:行数,列数,列索引,列非空值个数,列类型,列类型,内存占用
print(t2.describe())#快速综合统计结果:计数,均值,标准差,最大值,四分位数,最小值
动手:那么回到之前我们读取的狗名字统计的数据上,我们尝试一下刚刚的方法
那么问题来了:
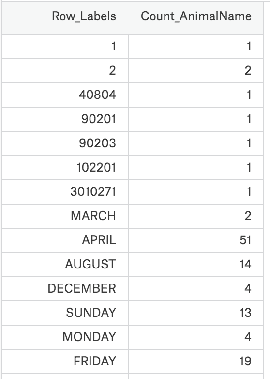
肯定想知道使用次数最高的前几个名字是什么呢?
pd.DataFrame.sort_values(by="Count_AnimalName",ascending=False)#ascending=True升序排序 by是对那一列排序 输入列索引键
t2 = pd.read_csv("F:\BaiduNetdiskDownload\youtube_video_data\dogNames2.csv")
print(t2)
t3 = t2.sort_values(by="Count_AnimalName",ascending=False)
print(t3)
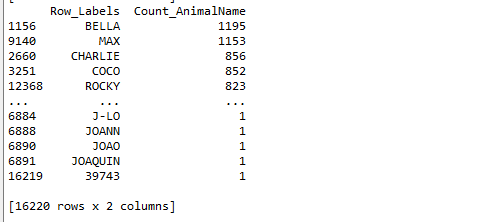
那么问题又来了:
如果我的数据有10列,我想按照其中的第1,第3,第8列排序,怎么办?
pandas之取行或者列
刚刚我们知道了如何给数据按照某一行或者列排序,那么现在我们想单独研究使用次数前100的数据,应该如何做?
t2 = pd.read_csv("F:\BaiduNetdiskDownload\youtube_video_data\dogNames2.csv")
print(t2)
t3 = t2.sort_values(by="Count_AnimalName",ascending=False)
print(t3[:100])
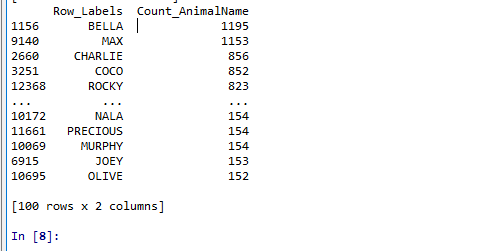
我们具体要选择某一列该怎么选择呢?t2[" Count_AnimalName "]
我们要同时选择行和不同列该怎么办?(和numpy类似)
pandas之loc取行数据
1、t2.loc 通过标签索引行数据(标签)
print(t2.loc["a","W"])
print(t2.loc["a",["W","Y"]])
print(type(t2.loc["a",["W","Y"]]))
print(t2.loc[["a","b"],["Z","Y"]])
print(t2.loc[:"c",:"Y"])
print(t2.loc["a":"b",["W","Z"]])
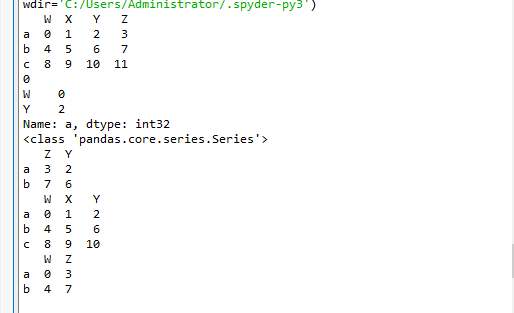
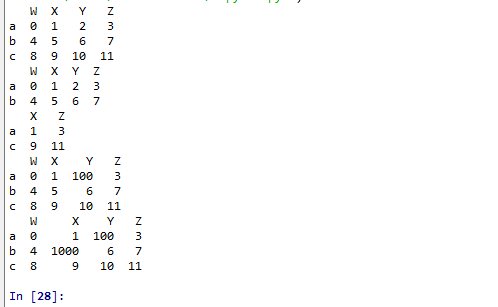
2、t2.iloc 通过位置获取行数据(位置)
import numpy as np
import pandas as pd t2 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ"))
print(t2)
print(t2.iloc[0:2,0:4])
print(t2.iloc[[0,2],[1,3]])
t2.loc["a","Y"] = 100 #复制操作
print(t2)
t2.iloc[1:2,[1]] = 1000 #复制操作
print(t2)
pandas之布尔索引(且,或,&,|,)
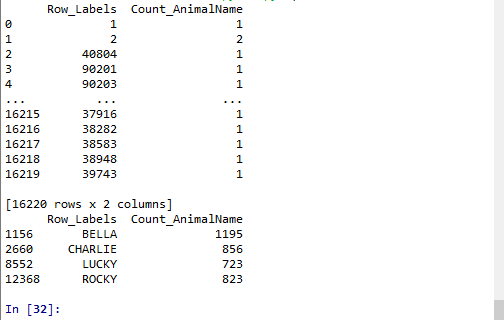
回到之前狗的名字的问题上,假如我们想找到所有的使用次数超过800的狗的名字,应该怎么选择?
print(t2[t2["Count_AnimalName"]>800])
回到之前狗的名字的问题上,假如我们想找到所有的使用次数超过700并且名字的字符串的长度大于4的狗的名字,应该怎么选择?
print(t2[(t2["Row_Labels"].str.len()>4)&(t2["Count_AnimalName"]>700)])
pandas之字符串方法

缺失数据的处理:
观察这组数据
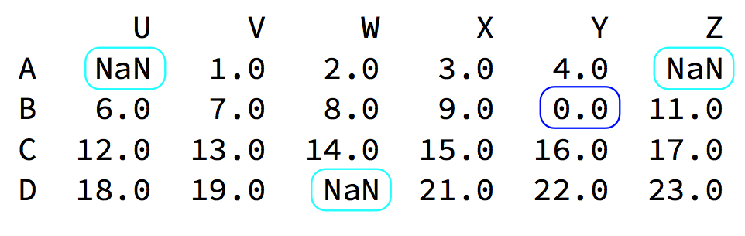
我们的数据缺失通常有两种情况: 一种就是空,None等,在pandas是NaN(和np.nan一样) 另一种是我们让其为0(蓝色框中)
对于NaN的数据,在numpy中我们是如何处理的?
在pandas中我们处理起来非常容易 判断数据是否为NaN:pd.isnull(df),pd.notnull(df)
处理方式1:删除NaN所在的行列
dropna (axis=0, how='any', inplace=False)
处理方式2:填充数据,
t.fillna(t.mean()),t.fiallna(t.median()),t.fillna(0)
处理为0的数据:t[t==0]=np.nan 当然并不是每次为0的数据都需要处理 计算平均值等情况,nan是不参与计算的,但是0会
import numpy as np
import pandas as pd t2 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ"))
#print(t2)
t2.loc[:"b",["W","Y"]] = np.nan
print(t2)
print(pd.isnull(t2))
print(pd.notnull(t2))
#print(t2.dropna(axis=0,how="all",inplace=False))
#any只要含NaN就删除前面规定的行列,all需要的是行列全部为NAN才能删除
#填充数据
#print(t2.fillna(t2.mean()))
print(t2)
print(t2.fillna(t2.median()))
print(t2.fillna(0))
05-pandas索引切片读取数据缺失数据处理的更多相关文章
- Pandas索引和选择数据
在本章中,我们将讨论如何切割和丢弃日期,并获取Pandas中大对象的子集. Python和NumPy索引运算符"[]"和属性运算符".". 可以在广泛的用例中快 ...
- pandas.read_csv()函数读取文件时,关于“header=None”影响读取列数区间的右闭合总结
对于一个没有字段名标题的数据,如data.csv 1.获取数据内容.pandas.read_csv("data.csv")默认情况下,会把数据内容的第一行默认为字段名标题. imp ...
- Pandas缺失数据处理
Pandas缺失数据处理 Pandas用np.nan代表缺失数据 reindex() 可以修改 索引,会返回一个数据的副本: df1 = df.reindex(index=dates[0:4], co ...
- Pandas 索引和切片
Series和Datafram索引的原理一样,我们以Dataframe的索引为主来学习 列索引:df['列名'] (Series不存在列索引) 行索引:df.loc[].df.iloc[] 选择列 / ...
- Pandas | 17 缺失数据处理
数据丢失(缺失)在现实生活中总是一个问题. 机器学习和数据挖掘等领域由于数据缺失导致的数据质量差,在模型预测的准确性上面临着严重的问题. 在这些领域,缺失值处理是使模型更加准确和有效的重点. 使用重构 ...
- 浅谈python之利用pandas和openpyxl读取excel数据
在自学到接口自动化测试时, 发现要从excel中读取测试用例的数据, 假如我的数据是这样的: 最好是每行数据对应着一条测试用例, 为方便取值, 我选择使用pandas库, 先安装 pip instal ...
- 其它课程中的python---5、Pandas处理数据和读取数据
其它课程中的python---5.Pandas处理数据和读取数据 一.总结 一句话总结: 记常用和特例:慢慢慢慢的就熟了,不用太着急,慢慢来 库的使用都很简单:就是库的常用函数就这几个,后面用的时候学 ...
- numpy和pandas的基础索引切片
Numpy的索引切片 索引 In [72]: arr = np.array([[[1,1,1],[2,2,2]],[[3,3,3],[4,4,4]]]) In [73]: arr Out[73]: a ...
- 三、Python系列——Pandas数据库读取数据
Pandas主要先读取表格类型的数据,然后进行分析. import pandas as pd# 由于是用pandas模块操作数据,因此不用在路径前加open,否则就是python直接打开文件,可能还会 ...
随机推荐
- Oralce 触发器
今天做了一个需要用到触发器实现的功能中间去到了各种问题,还好最后都解决了: 整个过程中真是遇到了不少错误: ORA-04091: 表 KPGO.T_ISSUER 发生了变化, 触发器/函数不能读它 O ...
- poj 1661 Help Jimmy(记忆化搜索)
题目链接:http://poj.org/problem?id=1661 一道还可以的记忆化搜索题,主要是要想到如何设dp,记忆化搜索是避免递归过程中的重复求值,所以要得到dp必须知道如何递归 由于这是 ...
- [NOI2001]炮兵阵地 题解
题意 我们先来了解一下基本的位运算 于( \(\bigwedge\) ),或 (\(\bigvee\) ) 异或(\(\bigoplus\)) 在下面我们用(&)代表于,(|)代表或 一道状压 ...
- Swift从入门到精通第八篇 - 方法 初识
方法(学习笔记) 环境Xcode 11.0 beta4 swift 5.1 方法 结构体.枚举.类都可以定义方法(实例方法.类型方法) 实例方法(Instance Methods) 实例方法只能用实例 ...
- 下一个排列(Leetcode31)解读
本题代码来自Leetcode官方,个人对其理解后,生成自己的注解,以便更好的让读者理解.如有侵权,立即删除! public class Main31 { public static void main ...
- 【深入浅出-JVM】(75):class 装载
过程 装载 条件 主动使用 class时 创建一个类的实例 (new .反射.克隆.反序列化) 调用类的静态方法(invokestatic) 使用类或接口的静态字段(getstatic.putstat ...
- hadoop2.7.3启动报错问题
在日志里面可以看出是没有对应的权限,因此在hdfs_site.xml中添加 <property> <name>dfs.permissions</name> < ...
- tomcat启动抛出异常
2018-5-26 15:55:47 org.apache.catalina.startup.VersionLoggerListener log信息: Server version: Apache T ...
- Metasploit工具----漏洞利用模块
漏洞利用是指由渗透测试者利用一个系统.应用或者服务中的安全漏洞进行的攻击行为.流行的渗透攻击技术包括缓冲区溢出.Web应用程序攻击,以及利用配置错误等,其中包含攻击者或测试人员针对系统中的漏洞而设计的 ...
- Spring Boot 入门之单元测试篇(五)
博客地址:http://www.moonxy.com 一.前言 JUnit 是一个由 Java 语言编写的开源的回归测试(回归测试是指重复以前全部或部分的相同测试)框架,由Erich Gamma 和 ...