浅入浅出 Java 排序算法
Java String 源码的排序算法
一、前言
Q:什么是选择问题?
选择问题,是假设一组 N 个数,要确定其中第 K 个最大值者。比如 A 与 B 对象需要哪个更大?又比如:要考虑从一些数组中找出最大项?
解决选择问题,需要对象有个能力,即比较任意两个对象,并确定哪个大,哪个小或者相等。找出最大项问题的解决方法,只要依次用对象的比较(Comparable)能力,循环对象列表,一次就能解决。
那么 JDK 源码如何实现比较(Comparable)能力的呢?
二、java.lang.Comparable 接口

Comparable 接口,从 JDK 1.2 版本就有了,历史算悠久。Comparable 接口强制了实现类对象列表的排序。其排序称为自然顺序,其 compareTo 方法,称为自然比较法。
该接口只有一个方法 public int compareTo(T o); ,可以看出
- 入参 T o :实现该接口类,传入对应的要被比较的对象
- 返回值 int:正数、负数和 0 ,代表大于、小于和等于
对象的集合列表(Collection List)或者数组(arrays) ,也有对应的工具类可以方便的使用:
- java.util.Collections#sort(List) 列表排序
- java.util.Arrays#sort(Object[]) 数组排序
那 String 对象如何被比较的?
三、String 源码中的算法
String 源码中可以看到 String JDK 1.0 就有了。那么应该是 JDK 1.2 的时候,String 类实现了 Comparable 接口,并且传入需要被比较的对象是 String。对象如图:
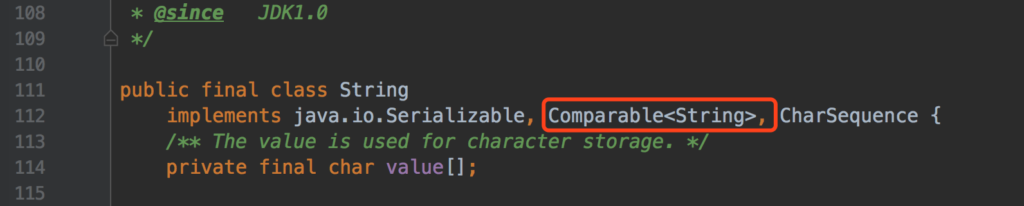
String 是一个 final 类,无法从 String 扩展新的类。从 114 行,可以看出字符串的存储结构是字符(Char)数组。先可以看看一个字符串比较案例,代码如下:
/**
* 字符串比较案例
*
* Created by bysocket on 19/5/10.
*/
public class StringComparisonDemo {
public static void main(String[] args) {
String foo = "ABC";
// 前面和后面每个字符完全一样,返回 0
String bar01 = "ABC";
System.out.println(foo.compareTo(bar01));
// 前面每个字符完全一样,返回:后面就是字符串长度差
String bar02 = "ABCD";
String bar03 = "ABCDE";
System.out.println(foo.compareTo(bar02)); // -1 (前面相等,foo 长度小 1)
System.out.println(foo.compareTo(bar03)); // -2 (前面相等,foo 长度小 2)
// 前面每个字符不完全一样,返回:出现不一样的字符 ASCII 差
String bar04 = "ABD";
String bar05 = "aABCD";
System.out.println(foo.compareTo(bar04)); // -1 (foo 的 'C' 字符 ASCII 码值为 67,bar04 的 'D' 字符 ASCII 码值为 68。返回 67 - 68 = -1)
System.out.println(foo.compareTo(bar05)); // -32 (foo 的 'A' 字符 ASCII 码值为 65,bar04 的 'a' 字符 ASCII 码值为 97。返回 65 - 97 = -32)
String bysocket01 = "泥瓦匠";
String bysocket02 = "瓦匠";
System.out.println(bysocket01.compareTo(bysocket02));// -2049 (泥 和 瓦的 Unicode 差值)
}
}
运行结果如下:
0
-1
-2
-1
-32
-2049
可以看出, compareTo 方法是按字典顺序比较两个字符串。具体比较规则可以看代码注释。比较规则如下:
- 字符串的每个字符完全一样,返回 0
- 字符串前面部分的每个字符完全一样,返回:后面就是两个字符串长度差
- 字符串前面部分的每个字符存在不一样,返回:出现不一样的字符 ASCII 码的差值
- 中文比较返回对应的 Unicode 编码值(Unicode 包含 ASCII)
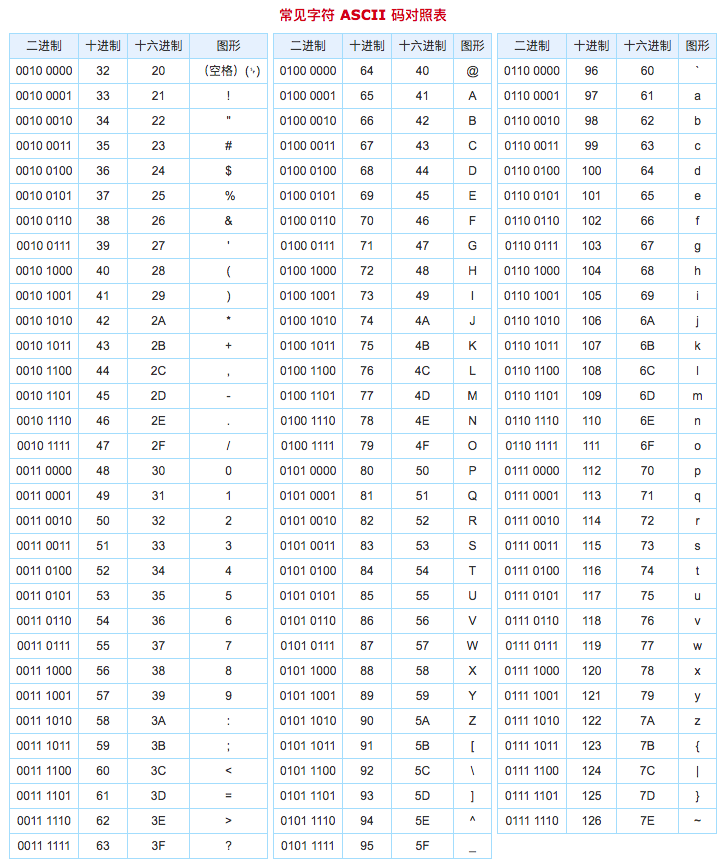
- foo 的 'C' 字符 ASCII 码值为 67
- bar04 的 'D' 字符 ASCII 码值为 68。
- foo.compareTo(bar04),返回 67 - 68 = -1
- 常见字符 ASCII 码,如图所示
再看看 String 的 compareTo 方法如何实现字典顺序的。源码如图:
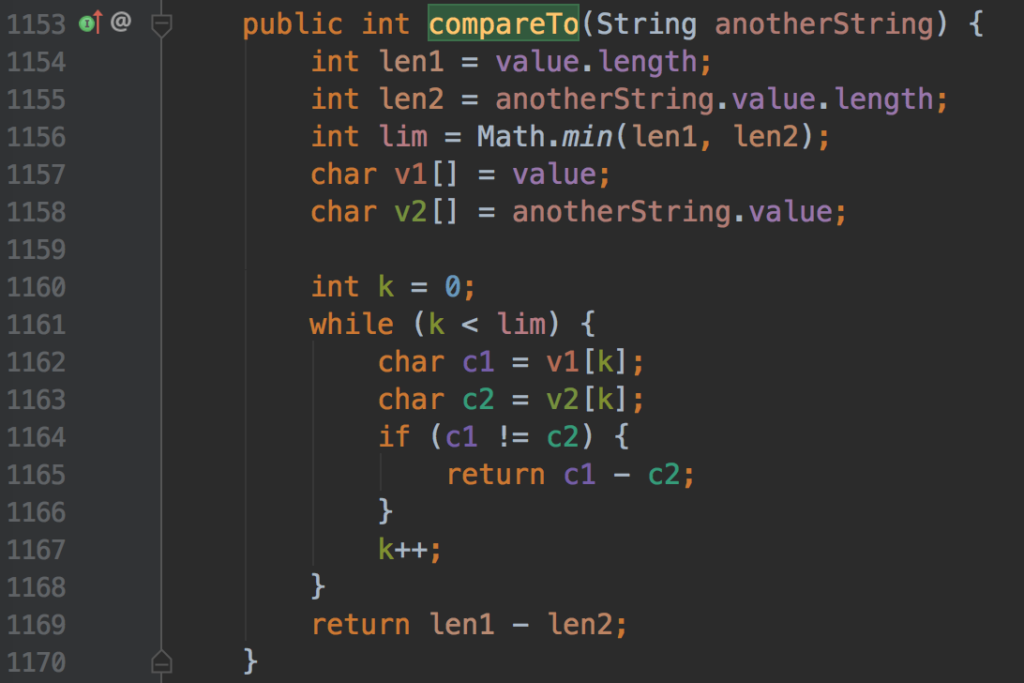
源码解析如下:
- 第 1156 行:获取当前字符串和另一个字符串,长度较小的长度值 lim
- 第 1161 行:如果 lim 大于 0 (较小的字符串非空),则开始比较
- 第 1164 行:当前字符串和另一个字符串,依次字符比较。如果不相等,则返回两字符的 Unicode 编码值的差值
- 第 1169 行:当前字符串和另一个字符串,依次字符比较。如果均相等,则返回两个字符串长度的差值
所以要排序,肯定先有比较能力,即实现 Comparable 接口。然后实现此接口的对象列表(和数组)可以通过 Collections.sort(和 Arrays.sort)进行排序。
还有 TreeSet 使用树结构实现(红黑树),集合中的元素进行排序。其中排序就是实现 Comparable 此接口
另外,如果没有实现 Comparable 接口,使用排序时,会抛出 java.lang.ClassCastException 异常。详细看《Java 集合:三、HashSet,TreeSet 和 LinkedHashSet比较》https://www.bysocket.com/archives/195
四、小结
上面也说到,这种比较其实有一定的弊端:
- 默认 compareTo 不忽略字符大小写。如果需要忽略,则重新自定义 compareTo 方法
- 无法进行二维的比较决策。比如判断 2 * 1 矩形和 3 * 3 矩形,哪个更大?
- 比如有些类无法实现该接口。一个 final 类,也无法扩展新的类。其也有解决方案:函数对象(Function Object)
方法参数:定义一个没有数据只有方法的类,并传递该类的实例。一个函数通过将其放在一个对象内部而被传递。这种对象通常叫做函数对象(Funtion Object)
在接口方法设计中, T execute(Callback callback) 参数中使用 callback 类似。比如在 Spring 源码中,可以看出很多设计是:聚合优先于继承或者实现。这样可以减少很多继承或者实现。类似 SpringJdbcTemplate 场景设计,可以考虑到这种 Callback 设计实现。
那插入排序呢?
文章工程:
- JDK 1.8
- 工程名:algorithm-core-learning
- 工程地址:https://github.com/JeffLi1993/algorithm-core-learning
一、前言
上面 Java String 源码的排序算法,讲了什么是选择问题,什么是比较能力。
选择问题,是假设一组 N 个数,要确定其中第 K 个最大值者。算法是为求解一个问题。
那什么是算法?
算法是某种集合,是简单指令的集合,是被指定的简单指令集合。确定该算法重要的指标:
- 第一是否能解决问题;
- 第二算法运行时间,即解决问题出结果需要多少时间;
- 还有所需的空间资源,比如内存等。
很多时候,写一个工作程序并不够。因为遇到大数据下,运行时间就是一个重要的问题。
算法性能用大 O 标记法表示。大 O 标记法是标记相对增长率,精度是粗糙的。比如 2N 和 3N + 2 ,都是 O(N)。也就是常说的线性增长,还有常说的指数增长等
典型的增长率

典型的提供性能做法是分治法,即分支 divide and conquer 策略:
- 将问题分成两个大致相等的子问题,递归地对它们求解,这是分的部分;
- 治阶段将两个子问题的解修补到一起,并可能再做些少量的附加工作,最后得到整个问题的解。

二、排序

排序问题,是古老,但一直流行的问题。从 ACM 接触到现在工作,每次涉及算法,或品读 JDK 源码中一些算法,经常会有排序的算法出现。
排序算法是为了将一组数组(或序列)重新排列,排列后数据符合从大到小(或从小到大)的次序。这样数据从无序到有序,会有什么好处?
- 应用层面:解决问题。
- 最简单的是可以找到最大值或者最小值
- 解决"一起性"问题,即相同标志元素连在一起
- 匹配在两个或者更多个文件中的项目
- 通过键码值查找信息
- 系统层面:减少系统的熵值,增加系统的有序度
(Donald Knuth 的经典之作《计算机程序设计艺术》(The Art of Computer Programming)的第三卷)
通过维基百科查阅资料得到:
在主内存中完成的排序叫做,内部排序。那需要在磁盘等其他存储完成的排序,叫做外部排序 external sorting。资料地址:https://en.wikipedia.org/wiki/External_sorting
上一篇《Java String 源码的排序算法》,讲到了 java.lang.Comparable 接口。那么接口是一个抽象类型,是抽象方法(compareTo)的集合,用 interface 来声明。因此被排序的对象属于 Comparable 类型,即实现 Comparable 接口,然后调用对象实现的 compareTo 方法进行比较后排序。
在这些条件下的排序,叫作基于比较的排序(comparison-based sorting)
三、插入排序
白话文:熊大(一)、熊二、熊三... 按照身高从低到高排队(排序)。这时候熊 N 加入队伍,它从队伍尾巴开始比较。如果它比前面的熊身高低,则与被比较的交换位置,依次从尾巴到头部进行比较 & 交换位置。最终换到了应该熊 N 所在的位置。这就是插入排序的原理。
插入排序(insertion sort)
- 最简单的排序之一。ps: 冒泡排序看看就好,不推荐学习
- 由 N - 1 次排序过程组成。
- 如果被排序的这样一个元素,就不需要排序。即 N =1 (1 - 1 = 0)
- 每一次排序保证,从第一个位置到当前位置的元素为已排序状态。
- 如图:每个元素往前进行比较,并终止于自己所在的位置

/**
* 插入排序案例
* <p>
* Created by 泥瓦匠@bysocket.com on 19/5/15.
*/
public class InsertionSortingDemo {
/**
* 插入排序
*
* @param arr 能比较的对象数组
* @param <T> 已排序的对象数组
*/
public static <T extends Comparable> void insertionSort(T[] arr) {
int j;
// 从数组第二个元素开始,向前比较
for (int p = 1; p < arr.length; p++) {
T tmp = arr[p];
// 循环,向前依次比较
// 如果比前面元素小,交换位置
for (j = p; (j > 0) && (tmp.compareTo(arr[j - 1]) < 0); j--) {
arr[j] = arr[j - 1];
}
// 如果比前面元素大或者相等,那么这就是元素的位置,交换
arr[j] = tmp;
}
}
public static void main(String[] args) {
Integer[] intArr = new Integer[] {2, 3, 1, 4, 3};
System.out.println(Arrays.toString(intArr));
insertionSort(intArr);
System.out.println(Arrays.toString(intArr));
}
}
代码解析如下:
- 从数组的第二个元素,向前开始比较。比第一个元素小,则交换位置
- 如果第二个元素比较完毕,那就第三个,第四个... 以此类推
- 比较到最后一个元素时,完成排序
时间复杂度是 O(N^2),最好情景的是排序已经排好的,那就是 O(N),因为满足不了循环的判断条件;最极端的是反序的数组,那就是 O(N^2)。所以该算法的时间复杂度为 O(N^2)
运行 main 方法,结果如下:
[2, 3, 1, 4, 3]
[1, 2, 3, 3, 4]
再考虑考虑优化,会怎么优化呢?
插入排序优化版 不是往前比较 。往前的一半比较,二分比较会更好。具体代码,可以自行试试
四、Array.sort 源码中的插入排序
上面用自己实现的插入算法进行排序,其实 JDK 提供了 Array.sort 方法,方便排序。案例代码如下:
/**
* Arrays.sort 排序案例
* <p>
* Created by 泥瓦匠@bysocket.com on 19/5/28.
*/
public class ArraysSortDemo {
public static void main(String[] args) {
Integer[] intArr = new Integer[] {2, 3, 1, 4, 3};
System.out.println(Arrays.toString(intArr));
Arrays.sort(intArr);
System.out.println(Arrays.toString(intArr));
}
}
运行 main 方法,结果如下:
[2, 3, 1, 4, 3]
[1, 2, 3, 3, 4]
那 Arrays.sort 是如何实现的呢?JDK 1.2 的时候有了 Arrays ,JDK 1.8 时优化了一版 sort 算法。大致如下:
- 如果元素数量小于 47,使用插入排序
- 如果元素数量小于 286,使用快速排序
- Timsort 算法整合了归并排序和插入排序
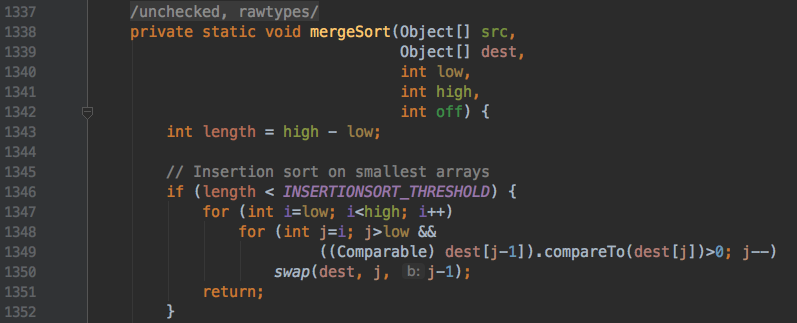
源码中我们看到了 mergeSort 里面整合了插入排序算法,跟上面实现的异曲同工。这边就不一行一行解释了。
五、小结
算法是解决问题的。所以不一定一个算法解决一个问题,可能多个算法一起解决一个问题。达到问题的最优解。插入排序,这样就这么简单
代码示例
本文示例读者可以通过查看下面仓库的中: StringComparisonDemo 字符串比较案例案例:
- Github:https://github.com/JeffLi1993/algorithm-core-learning
- Gitee:https://gitee.com/jeff1993/algorithm-core-learning
参考资料
- 《数据结构与算法分析:Java语言描述(原书第3版)》
- https://en.wikipedia.org/wiki/Unicode
- https://www.cnblogs.com/vamei/tag/算法/
- https://www.bysocket.com/archives/2314/algorithm
浅入浅出 Java 排序算法的更多相关文章
- 浅入深出Java输入输出流主线知识梳理
Java把不同类型的输入.输出,这些输入输出有些是在屏幕上.有些是在电脑文件上, 都抽象为流(Stream) 按流的方向,分为输入流与输出流,注意这里的输出输出是相对于程序而言的,如:如对于一个J ...
- 浅入深出之Java集合框架(中)
Java中的集合框架(中) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,如果已经有java基础的小伙伴可以直接跳到<浅入深出之Java集合框架 ...
- 浅入深出之Java集合框架(下)
Java中的集合框架(下) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,哈哈这篇其实也还是基础,惊不惊喜意不意外 ̄▽ ̄ 写文真的好累,懒得写了.. ...
- 浅入深出之Java集合框架(上)
Java中的集合框架(上) 由于Java中的集合框架的内容比较多,在这里分为三个部分介绍Java的集合框架,内容是从浅到深,如果已经有java基础的小伙伴可以直接跳到<浅入深出之Java集合框架 ...
- 重新学习MySQL数据库2:『浅入浅出』MySQL 和 InnoDB
重新学习Mysql数据库2:『浅入浅出』MySQL 和 InnoDB 作为一名开发人员,在日常的工作中会难以避免地接触到数据库,无论是基于文件的 sqlite 还是工程上使用非常广泛的 MySQL.P ...
- 『浅入浅出』MySQL 和 InnoDB
作为一名开发人员,在日常的工作中会难以避免地接触到数据库,无论是基于文件的 sqlite 还是工程上使用非常广泛的 MySQL.PostgreSQL,但是一直以来也没有对数据库有一个非常清晰并且成体系 ...
- 浅入浅出 1.7和1.8的 HashMap
前言 HashMap 是我们最最最常用的东西了,它就是我们在大学中学习数据结构的时候,学到的哈希表这种数据结构.面试中,HashMap 的问题也是常客,现在卷到必须答出来了,是必须会的知识. 我在学习 ...
- Spring浅入浅出——不吹牛逼不装逼
Spring浅入浅出——不吹牛逼不装逼 前言: 今天决定要开始总结框架了,虽然以前总结过两篇,但是思维是变化的,而且也没有什么规定说总结过的东西就不能再总结了,是吧.这次总结我命名为浅入浅出,主要在于 ...
- Spring的数据库编程浅入浅出——不吹牛逼不装逼
Spring的数据库编程浅入浅出——不吹牛逼不装逼 前言 上文书我写了Spring的核心部分控制反转和依赖注入,后来又衔接了注解,在这后面本来是应该写Spring AOP的,但我觉得对于初学者来说,这 ...
随机推荐
- springboot集成redis实现消息发布订阅模式-双通道(跨多服务器)
基础配置参考https://blog.csdn.net/llll234/article/details/80966952 查看了基础配置那么会遇到一下几个问题: 1.实际应用中可能会订阅多个通道,而一 ...
- 以股票案例入门基于SVM的机器学习
SVM是Support Vector Machine的缩写,中文叫支持向量机,通过它可以对样本数据进行分类.以股票为例,SVM能根据若干特征样本数据,把待预测的目标结果划分成“涨”和”跌”两种,从而实 ...
- 100天搞定机器学习|Day19-20 加州理工学院公开课:机器学习与数据挖掘
前情回顾 机器学习100天|Day1数据预处理 100天搞定机器学习|Day2简单线性回归分析 100天搞定机器学习|Day3多元线性回归 100天搞定机器学习|Day4-6 逻辑回归 100天搞定机 ...
- 《机器学习技法》---线性SVM
(本文内容和图片来自林轩田老师<机器学习技法>) 1. 线性SVM的推导 1.1 形象理解为什么要使用间隔最大化 容忍更多的测量误差,更加的robust.间隔越大,噪声容忍度越大: 1.2 ...
- npm install 安装很慢
npm install 安装很慢 设置国内镜像 npm config set registry https://registry.npm.taobao.org npm install
- PIXIJS的一些使用
我发现pixijs在国内简直就是一片静土啊,只有那么一点点的微弱的不能再微弱的声音. 我在这里整理了下我使用过程中解决和可能理解的一些问题吧,都是一个个点,而不是完整的示例. 先放官网示例: http ...
- Spring自定义属性编辑器及原理解释.md
bean的自动装配解释 手动解决方式 自动注入解决方式 bean的自动装配解释 之前有构造注入和设值注入,但是也是手动的 autowire ="byname" 这里要注意自动装配的 ...
- 跨库数据迁移利器 —— Sqoop
一.Sqoop 基本命令 1. 查看所有命令 # sqoop help 2. 查看某条命令的具体使用方法 # sqoop help 命令名 二.Sqoop 与 MySQL 1. 查询MySQL所有数据 ...
- C#数据结构_图
顶点的度=顶点的入度+顶点的出度. 顶点 v 的入度是指以该顶点 v 为弧头的弧的数目:顶点 v 的出度是指以该顶点 v 为弧尾的弧的数目. 简单路径:一条路径上顶点不重复出现. 回路:第一个顶点和最 ...
- 从0到1体验Jenkins+Docker+Git+Registry实现CI自动化发布
一.前言 Jenkins是一款开源 CI&CD 软件,用于自动化各种任务,包括构建.测试和部署软件.Jenkins 支持各种运行方式,可通过系统包.Docker 或者通过一个独立的 Java ...