React Diff算法一览
前言
diff算法一直是React系统最核心的部分,并且由于演化自传统diff,使得比较方式从O(n^3)降级到O(n),然后又改成了链表方式,可谓是变化万千。
传统Diff算法
传统diff算法需要循环比较两棵树,所有节点的循环,那么单纯比较次数就是O(n^2),n*n
P L
A A
/ \ / \
/ \ / \
B D ====> D B
/ \
C C
刷刷刷,每次都需要循环遍历,于是有以下的查找过程:
PA->LA
PA->LB
PA->LC
PA->LD
PB->LA
...除了查找过程消耗了O(n^2)之外,找到差异后还要计算最小转换方式,最终结果为O(n^3)。
所以,传统的diff算法的时间复杂度为O(n^3)。
如果React运用这种算法,那么节点过多,将会有大量的开销,虽然CPU的秒速达到30亿次计算,但依旧是非常耗费性能的。
有没有什么方式可以降低时间复杂度呢?
于是,React15对传统的diff做了一些限制,使得时间复杂度变为了O(n)。
React 15的Diff算法
《深入React技术栈》这本书,给出了三种Diff策略分析,文字描述太过抽象,直接表述如下:
Tree diff、Component diff、Element diff
Tree diff
什么是Tree diff?先上图:
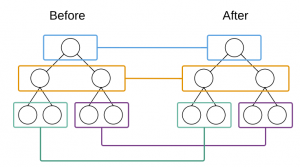
首先,进行同级比较,并非循环比较。这样比较次数就降为一层一次,时间复杂度直接降为O(n)
如果同级相同位置节点不一样,则直接删除替换,简单粗暴。
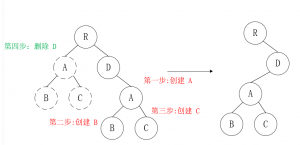
而对于节点移动,同样道理,也是简单粗暴的删除重建。如下图所示(图中第四步应该是删除左侧的整棵A树):
Component diff
不多说,先上图:
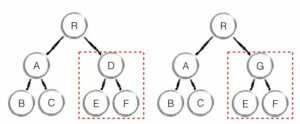
其实component diff相当于是子树的diff,基本方案和tree diff是一致的,如果如上图D变为G,那么直接删除D这一整棵树,然后重新渲染G树。
依旧是简单粗暴。
Element diff
对于同一节点的元素,diff算法提供了三种操作:插入、移动、删除。还是先上图:
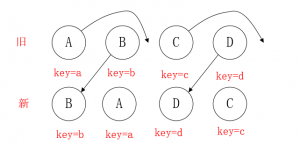
此时的操作,是B、D不做任何操作,AC移动到相应位置【前提是都有相同的key】
如果,此时的key不相同,全都发生了变化,那么节点全都是要删除重新构建,将会消耗大量性能。
React 16的Diff算法
React16相比React15的Diff算法发生了很大的变化,其中最主要就是引入了Fiber循环任务调度算法。
Fiber
Fiber是什么?干了什么?
Fiber在diff阶段,做了如下的操作:
1、可以随时将diff操作进行任务拆分。
2、diff阶段的每个任务可以随时执行或者中止。
3、diff阶段任务调度优先级控制。
所以,Fiber相当于是,在15的diff算法阶段,做了优先级的任务调度控制,
所以,Fiber是根据一个fiber节点(VDOM节点)来拆分,以fiber node为一个任务单元,一 个组件实例都是一个任务单元。任务循环中,每处理完一个fiber node,可以中断/挂起/恢复。
它又是如何能够进行这样的异步操作的呢?这就不得不说一个方法:requestIdleCallback
浏览器提供的requestIdleCallback API中的Cooperative Scheduling可以让浏览器在空闲时间执行回调(开发者传入的方法),在回调参数中可以获取到当前帧(16ms)剩余的时间。利用这个信息可以合理的安排当前帧需要做的事情,如果时间足够,那继续做下一个任务,如果时间不够就歇一歇,调用requestIdleCallback来获知主线程不忙的时候,再继续做任务
Fiber Node是什么?
链表!
将要处理的节点,存在链表结构,那么就能够做到节点复用。【这大概是Fiber的核心吧】
大体上的Diff引入了Fiber之后,我们就增加了更多的链表复用功能,通过这一点,我们可以使得React Diff的性能得到提升。
总结
其实,这篇文章着重讲的还是React15的diff,React 16的diff并未详细探讨,接下来会出一篇文章,单独讲解React 16的Diff策略。不过React 16Diff策略的核心Fiber是不可错过的点。
参考资料
《深入React技术栈》
https://segmentfault.com/a/1190000016723305
https://www.jianshu.com/p/3ba0822018cf
https://www.jianshu.com/p/21a445066d51?from=timeline
https://www.zhihu.com/question/66851503/answer/246766239
https://blog.csdn.net/P6P7qsW6ua47A2Sb/article/details/82322033
https://blog.csdn.net/VhWfR2u02Q/article/details/100011830
我的博客:http://www.gaoyunjiao.fun/?p=170
React Diff算法一览的更多相关文章
- React Diff 算法
React介绍 React是Facebook开发的一款JS库,用于构建用户界面的类库. 它采用声明式范例,可以传递声明代码,最大限度地减少与DOM的交互. 特点: 声明式设计:React采用声明范式, ...
- react diff算法浅析
diff算法作为Virtual DOM的加速器,其算法的改进优化是React整个界面渲染的基础和性能的保障,同时也是React源码中最神秘的,最不可思议的部分 1.传统diff算法计算一棵树形结构转换 ...
- React Diff算法
Web界面由DOM树来构成,当其中某一部分发生变化时,其实就是对应的某个DOM节点发生了变化.在React中,构建UI界面的思路是由当前状态决定界面.前后两个状态就对应两套界面,然后由React来比较 ...
- React——diff算法
react的diff算法基于两个假设: 1.不同类型的元素会产生不同的树 2.通过设置key,开发者能够提示那些子组件是稳定的 diff算法 当比较两个树时,react首先会比较两个根节点,接下来具体 ...
- React基础(Diff算法,属性和状态)
1.React的背景原理 (1)React Diff算法流程 (2)React虚拟DOM机制 React引入了虚拟DOM(Virtual DOM)的机制:在浏览器端用Javascript实现了一套DO ...
- ReactiveNative学习之Diff算法
React 源码剖析系列 - 不可思议的 react diff深入浅出React(四):虚拟DOM Diff算法解析React diff 算法总结链接引用的文章React出于性能的考虑,为了避免频繁操 ...
- React 源码剖析系列 - 不可思议的 react diff
简单点的重复利用已有的dom和其他REACT性能快的原理. key的作用和虚拟节点 目前,前端领域中 React 势头正盛,使用者众多却少有能够深入剖析内部实现机制和原理. 本系列文章希望通过剖析 ...
- 直接操作DOM一定比虚拟DOM操作耗时,diff算法,key值,虚拟 DOM的定义
直接操作DOM一定比虚拟DOM操作耗时吗? 或者一次直接DOM操作一定比一次虚拟DOM操作耗时吗? 1)虚拟DOM的本质就是一个JS对象,虚拟DOM减少了真实DOM的操作,当修改数据的时候,就是修改虚 ...
- diff算法深入一下?
文章转自豆皮范儿-diff算法深入一下 一.前言 有同学问:能否详细说一下 diff 算法. 简单说:diff 算法是一种优化手段,将前后两个模块进行差异化比较,修补(更新)差异的过程叫做 patch ...
随机推荐
- sql server 2014 的安装
1.双击打开sql_server2014的安装包 2.点击弹出来的对话框的确定按钮 3.等待一会,安装包在准备中 4.弹出SQL server 安装中心,点击全新 SQL Server 独立安装 5. ...
- Cabloy全栈JS框架微创新之一:不一样的“移动优先 PC适配”
前言 目前流行的前端UI组件库都支持移动设备优先的响应式布局特性.但基于Mobile和PC两个场景的不同用户体验,也往往会实现Mobile和PC两个版本. PC场景下的Web工程,如大量的后台前端管理 ...
- 解决ie6上碰到的css兼容问题
ie6上css碰到的坑 前两天在给一个项目做东西的时候,碰到一个有意思的项目,是需要兼容ie6,有一些碰到并且解决的问题,给大家写下来,方便大家以后碰到类似的问题哈- 喜欢的话还请点赞! 1.impo ...
- CentOS升级内核方法
查询现在系统的kernel安装包:rpm -qa |grep kernel 删除不用的内核安装包:rpm -e xxx centos 6升级:https://blog.csdn.net/wh21121 ...
- H5当弹出弹窗遮罩时如何阻止滚动穿透(使用css方式)
最近的一个H5活动中有一个是点击[分享]弹窗指引遮罩弹窗引导用户进行分享,但突然发现弹出弹窗的时候下层仍然可以进行滑动,这个问题是个H5经久不衰讨论的问题,重点是我这个页面在安卓系统上有明显的滑动闪烁 ...
- eclipse导入别的项目后发现jdk版本不一样,该如何解决呢?
当我们导入其他人的项目的时候,发现导入的项目的jdk版本与我们使用电脑上的版本不同,该如何解决呢? 选中项目右键 --> Properties --> Build Path --> ...
- Elastic Static初识(01)
写在前面 Elastic Static 是指由Elasticsearch,Logstash,Kibana,Beats等组件结合起来而构成的一个数据收集,分析,可视化的一个架构.我们经常听说过的ELK就 ...
- sql server编写archive通用模板脚本实现自动分批删除数据
博主做过比较多项目的archive脚本编写,对于这种删除数据的脚本开发,肯定是一开始的话用最简单的一个delete语句,然后由于部分表数据量比较大啊,索引比较多啊,会发现删除数据很慢而且影响系统的正常 ...
- Hadoop点滴-HDFS文件系统
1.HDFS中,目录作为元数据,保存在namenode中,而非datanode中 2.HDFS的文件权限模型与POSIX的权限模式非常相似,使用 r w x 3.HDFS的文件执行权限(X)可以 ...
- Spring Environment的加载
这节介绍environment,默认环境变量的加载以及初始化. 之前在介绍spring启动过程讲到,第一步进行环境准备时就会初始化一个StandardEnvironment.下图为Environm ...