python爬取豆瓣视频信息代码
这里是爬取豆瓣视频信息,用pyquery库(jquery的python库)。
一:代码
from urllib.request import quote
from pyquery import PyQuery as pq
import requests
import pandas as pd
def get_text_page(movie_name):
'''
函数功能:获得指定电影名的源代码
参数:电影名
返回值:电影名结果的源代码
'''
url = 'https://www.douban.com/search?q=' + movie_name
headers = {
'Host' : 'www.douban.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
}
r = requests.get(url,headers = headers,timeout=5)
return r.text
def get_last_url(this_text):
'''
函数功能:根据指定的源代码得到最终的网页地址
参数:搜索结果源代码
返回值:最终的网页地址
'''
doc = pq(this_text)
lis = doc('.title a').items()
k = 0
this_str = ''
for i in lis:
# print('豆瓣搜索结果为:{0}'.format(i.text()))
# print('地址为:{0}'.format(i.attr.href))
# print('\n')
if k == 0:
this_str = i.attr.href
k += 1
return this_str
def the_last_page(this_url):
'''
函数功能:获得最终电影网页的源代码
参数:最终的地址
返回值:最终电影网页的源代码
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.90 Safari/537.36',
}
r = requests.get(this_url,headers = headers,timeout=20)
return r.text
def the_last_text(this_text,movie_name):
'''
函数功能:获得每一项的数据
参数:爬取页面的源代码
返回值:返回空
'''
doc = pq(this_text)
# 获取标题
title = doc('#content h1').text()
# 获取海报
photo = doc('.nbgnbg img')
photo_url = photo.attr.src
r = requests.get(photo_url)
with open('{m}.jpg'.format(m = movie_name),'wb') as f:
f.write(r.content)
# 电影信息
message = doc('#info').text()
# 豆瓣评分
grade = doc('#interest_sectl').text()
# 剧情
things = doc('.related-info').text()
with open('{0}.txt'.format(movie_name),'w+') as f:
try:
f.writelines([title,'\n','\n\n',message,'\n\n',grade,'\n\n',things])
except:
f.writelines([title,'\n','\n\n',message,'\n\n',grade])
# 演员
# 演员名
name = []
person_name = doc('.info').items()
for i in person_name:
name.append(i.text())
# 演员图片地址
person_photo = doc('#celebrities')
j = 0
for i in person_photo .find('.avatar').items():
m = i.attr('style')
person_download_url = m[m.find('(') + 1:m.find(')')]
# 下载演员地址
r = requests.get(person_download_url)
try:
with open('{name}.jpg'.format(name = name[j]),'wb') as f:
f.write(r.content)
except:
continue
j += 1
def lookUrl(this_text,my_str):
'''
函数功能:获得观看链接
参数:爬取页面的源代码
返回值:返回空
'''
doc = pq(this_text)
all_url = doc('.bs li a').items()
movie_f = []
movie_url = []
for i in all_url:
movie_f.append(i.text())
movie_url.append(i.attr.href)
dataframe = pd.DataFrame({'观看平台':movie_f,'观看地址':movie_url})
dataframe.to_csv("{movie_name}的观看地址.csv".format(movie_name = my_str),index=False,encoding = 'utf_8_sig',sep=',')
def main():
name = input('')
my_str = name
movie_name = quote(my_str)
page_text = get_text_page(movie_name) # 得指定电影名的源代码
last_url = get_last_url(page_text) # 根据指定的源代码得到最终的网页地址
page_text2 = the_last_page(last_url) # 获得最终电影网页的源代码
the_last_text(page_text2,my_str) # 获得每一项的数据
lookUrl(page_text2,my_str) # 得到并处理观看链接
main()
二:结果如下(部分例子)
1.输入天气之子
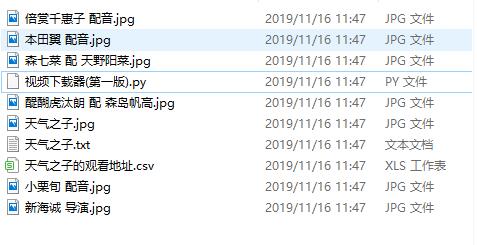
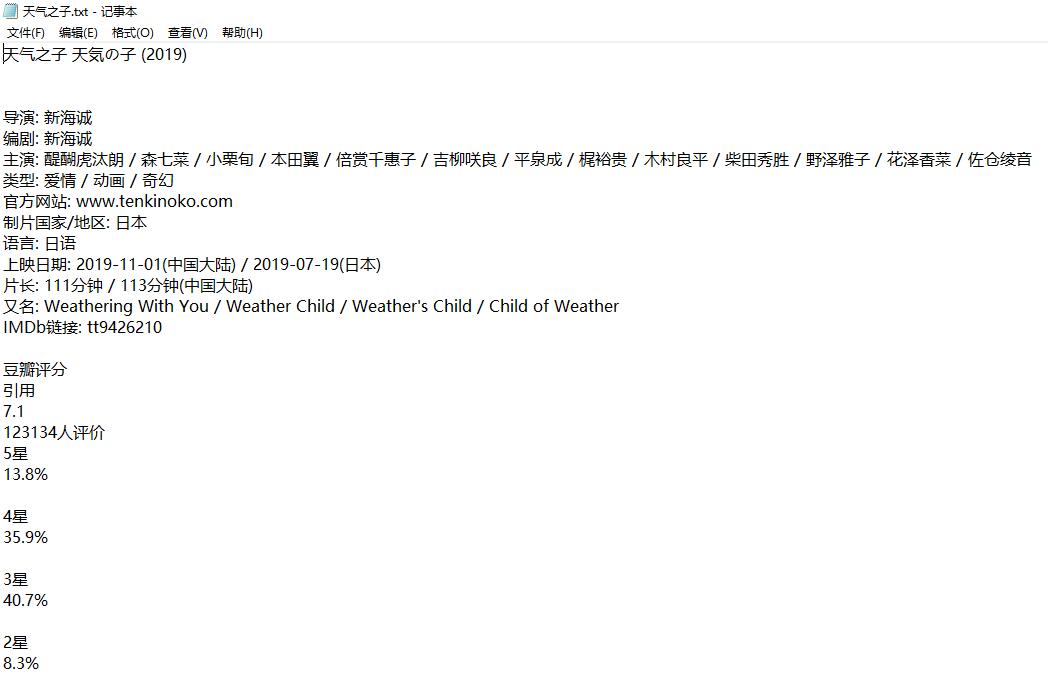

2.输入百变小樱魔法卡
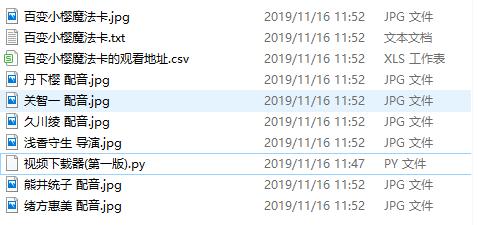
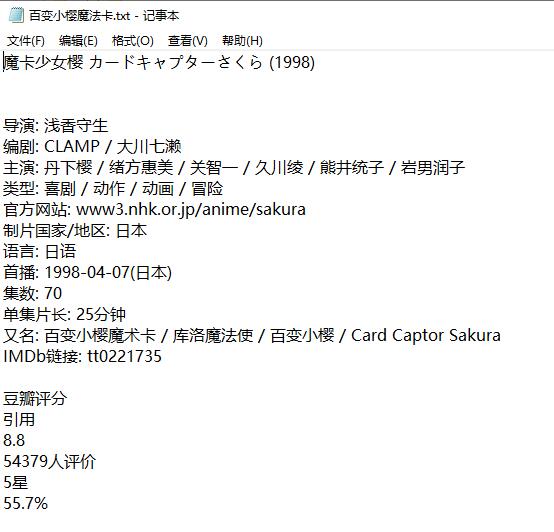

必须是已经上映的电影才有观看地址
3.独立日
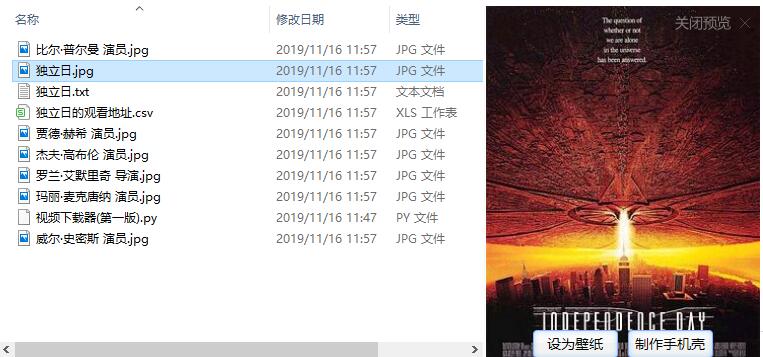
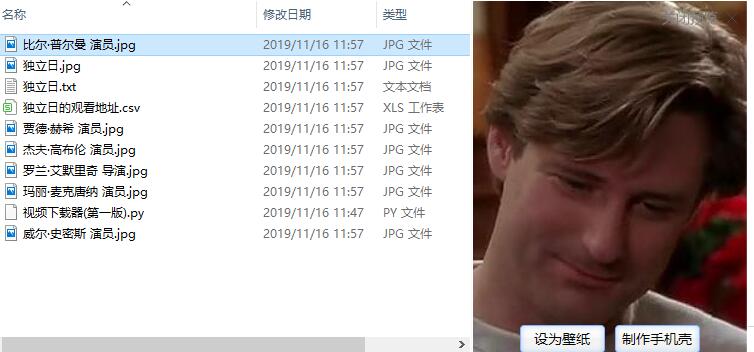



python爬取豆瓣视频信息代码的更多相关文章
- python 爬取豆瓣书籍信息
继爬取 猫眼电影TOP100榜单 之后,再来爬一下豆瓣的书籍信息(主要是书的信息,评分及占比,评论并未爬取).原创,转载请联系我. 需求:爬取豆瓣某类型标签下的所有书籍的详细信息及评分 语言:pyth ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- python 爬取bilibili 视频信息
抓包时发现子菜单请求数据时一般需要rid,但的确存在一些如游戏->游戏赛事不使用rid,对于这种未进行处理,此外rid一般在主菜单的响应中,但有的如番剧这种,rid在子菜单的url中,此外返回的 ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- python爬取网页的通用代码框架
python爬取网页的通用代码框架: def getHTMLText(url):#参数code缺省值为‘utf-8’(编码方式) try: r=requests.get(url,timeout=30) ...
- Python爬取豆瓣《复仇者联盟3》评论并生成乖萌的格鲁特
代码地址如下:http://www.demodashi.com/demo/13257.html 1. 需求说明 本项目基于Python爬虫,爬取豆瓣电影上关于复仇者联盟3的所有影评,并保存至本地文件. ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
随机推荐
- vscode 设置代码格式化缩进为2个空格
打开文件——>首选——>设置 输入搜索 tabsize 按照下图设置即可,然后打开 注意:如果不将Detect Indentation 勾选取消 以前用tab创建的忘记依然为4个空格
- Android 安全攻防(三): SEAndroid Zygote
转自:http://blog.csdn.net/yiyaaixuexi/article/details/8495695 在Android系统中,所有的应用程序进程,以及系统服务进程SystemServ ...
- JDK8日常开发系列:Consumer详解
java.util.function中 Function, Supplier, Consumer, Predicate和其他函数式接口广泛用在支持lambda表达式的API中.这些接口有一个抽象方法, ...
- 《Python自动化测试九章经》
Python是当前非常流行的一门编程语言,它除了在人工智能.数据处理.Web开发.网络爬虫等领域得到广泛使用之外,他也非常适合软件测试人员使用,但是,对于刚入行的测试小白来说,并不知道学习Python ...
- [Go] 利用channel形成管道沟通循环内外
这个要解决的问题是,比如如果有一个大循环,取自一个大的文件,要进行逻辑处理,那么这个逻辑的代码要放在循环每一行的循环体里面,这样有可能会出现一个for循环的逻辑嵌套,一层又一层,类似俄罗斯套娃.如果放 ...
- Shell命令-搜索文件或目录之which、find
文件及内容处理 - which.find 1. which:查找二进制命令,按环境变量PATH路径查找 which命令的功能说明 which 命令用于查找文件.which 指令会在环境变量 $PATH ...
- Ubuntu 18.04安装Conda、Jupyter Notebook、Anaconda
1.Conda是一个开源的软件包管理系统和环境管理系统,它可以作为单独的纯净工具安装在系统环境中,有的python库无法用conda获得时,conda允许在conda环境中利用Pip获取包文件.可以将 ...
- Java实现记事本|IO流/GUI
Java实现记事本 题目 利用GUI实现一个简单的记事本(notepad),即打开文件,文字内容显示在界面上: 允许对文字内容进行编辑,并可以保存到文件. 代码 package notePadExp; ...
- 2016年蓝桥杯B组C/C++决赛题解
2016年第七届蓝桥杯B组C/C++决赛题解 2016年蓝桥杯B组C/C++决赛题目(不含答案) 1.一步之遥 枚举解方程,或者套模板解线性方程 #include<bits/stdc++.h&g ...
- 201271050130-滕江南-《面向对象程序设计(java)》第十三周学习总结
201271050130-滕江南-<面向对象程序设计(java)>第十三周学习总结 项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daiz ...