转载python并行运算实例
|
Python的并发处理能力臭名昭著。先撇开线程以及GIL方面的问题不说,我觉得多线程问题的根源不在技术上而在于理念。大部分关于Pyhon线程和多进程的资料虽然都很不错,但却过于细节。这些资料讲的都是虎头蛇尾,到了真正实际使用的部分却草草结束了。 传统例子在DDG https://duckduckgo.com/搜索“Python threading 标准线程多进程,生产者/消费者示例:
Mmm.. 感觉像是java代码 在此我不想印证采用生产者/消费者模式来处理线程/多进程是错误的— 确实没问题。实际上这也是解决很多问题的最佳选择。但是,我却不认为这是日常工作中常用的方式。 |
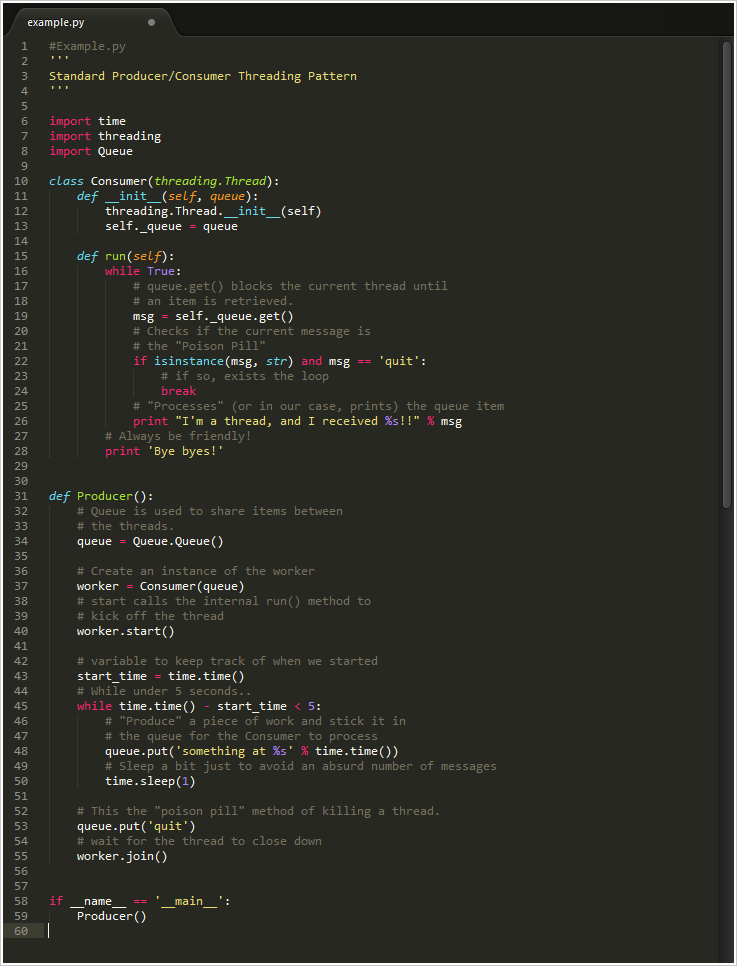 这里是代码截图,如果用其他模式贴出大段代码会很不美观。文本模式点这里
这里是代码截图,如果用其他模式贴出大段代码会很不美观。文本模式点这里
问题所在一开始,你需要一个执行下面操作的铺垫类。接着,你需要创建一个传递对象的队列,并在队列两端实时监听以完成任务。(很有可能需要两个队列互相通信或者存储数据) Worker越多,问题越大. 下一步,你可能会考虑把这些worker放入一个线程池一边提高Python的处理速度。下面是
|
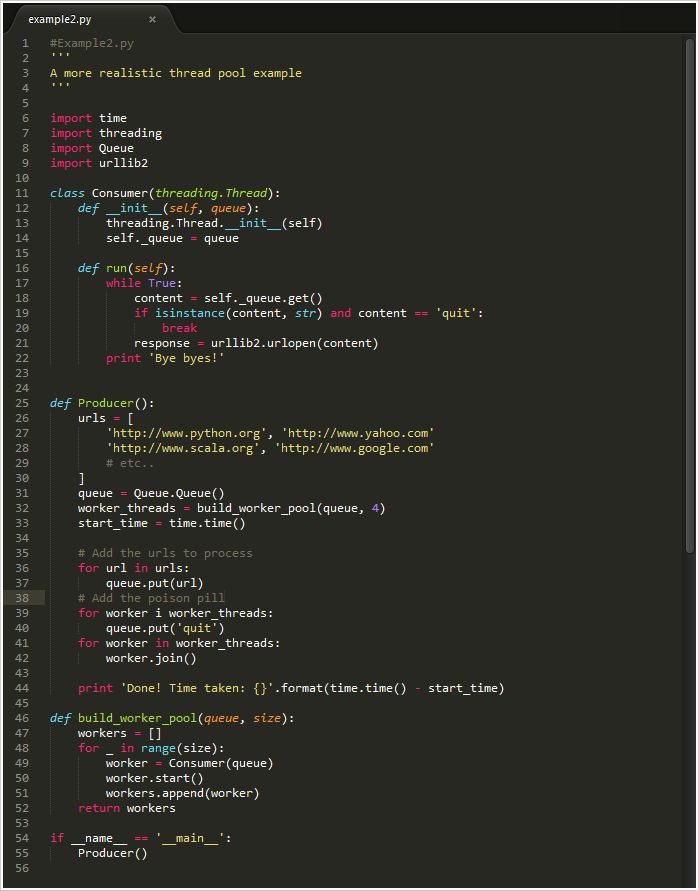 Seriously, Medium. Fix your code support.
Seriously, Medium. Fix your code support. |
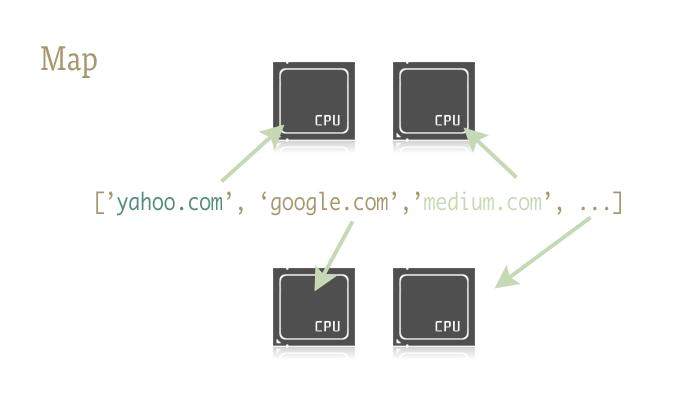
感觉效果应该很好,但是看看这些代码!初始化方法、线程跟踪,最糟的是,如果你也和我一样是个容易犯死锁问题的人,这里的join语句就要出错了。这样就开始变得更加复杂了! 到现在为止都做了些什么?基本上没什么。上面的代码都是些基础功能,而且很容易出错。(天啊,我忘了写上在队列对象上调用task_done()方法(我懒得修复这个问题在重新截图)),这真是性价比太低。所幸的是,我们有更好的办法. 引入:Map Map是个很酷的小功能,也是简化Python并发代码的关键。对那些不太熟悉Map的来说,它有点类似Lisp.它就是序列化的功能映射功能. e.g. urls = [', '] 这里调用urlopen方法,并把之前的调用结果全都返回并按顺序存储到一个集合中。这有点类似 results = [] Map能够处理集合按顺序遍历,最终将调用产生的结果保存在一个简单的集合当中。 为什么要提到它?因为在引入需要的包文件后,Map能大大简化并发的复杂度!
支持Map并发的包文件有两个: Multiprocessing,还有少为人知的但却功能强大的子文件 multiprocessing.dummy. . |
|
Digression这是啥东西?没听说过线程引用叫dummy的多进程包文件。我也是直到最近才知道。它在多进程的说明文档中也只被提到了一句。它的效果也只是让大家直到有这么个东西而已。这可真是营销的失误! Dummy是一个多进程包的完整拷贝。唯一不同的是,多进程包使用进程,而dummy使用线程(自然也有Python本身的一些限制)。所以一个有的另一个也有。这样在两种模式间切换就十分简单,并且在判断框架调用时使用的是IO还是CPU模式非常有帮助. |
准备开始准备使用带有并发的map功能首先要导入相关包文件: from multiprocessing import Pool 然后初始化: pool = ThreadPool() 就这么简单一句解决了example2.py中build_worker_pool的功能. 具体来讲,它首先创建一些有效的worker启动它并将其保存在一些变量中以便随时访问。 pool对象需要一些参数,但现在最紧要的就是:进程。它可以限定线程池中worker的数量。如果不填,它将采用系统的内核数作为初值. |
! |
|
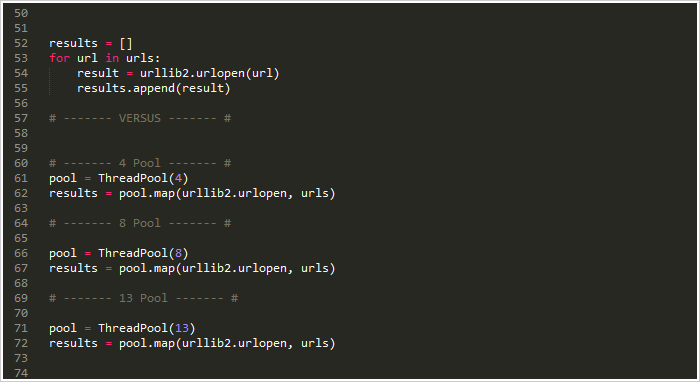
一般情况下,如果你进行的是计算密集型多进程任务,内核越多意味着速度越快(当然这是有前提的)。但如果是涉及到网络计算方面,影响的因素就千差万别。所以最好还是能给出合适的线程池大小数。 pool = ThreadPool(4) # Sets the pool size to 4 如果运行的线程很多,频繁的切换线程会十分影响工作效率。所以最好还是能通过调试找出任务调度的时间平衡点。 好的,既然已经建好了线程池对象还有那些简单的并发内容。咱们就来重写一些example2.py中的url opener吧!
|

|
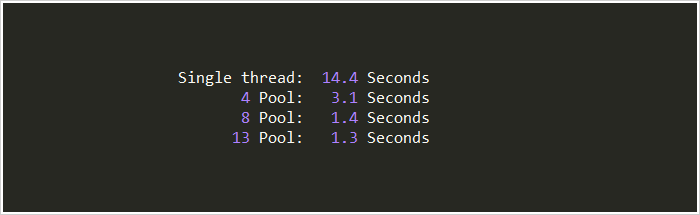
看吧!只用4行代码就搞定了!其中三行还是固定写法。使用map方法简单的搞定了之前需要40行代码做的事!为了增加趣味性,我分别统计了不同线程池大小的运行时间。
结果:
效果惊人!看来调试一下确实很有用。当线程池大小超过9以后,在我本机上的运行效果已相差无几。 |
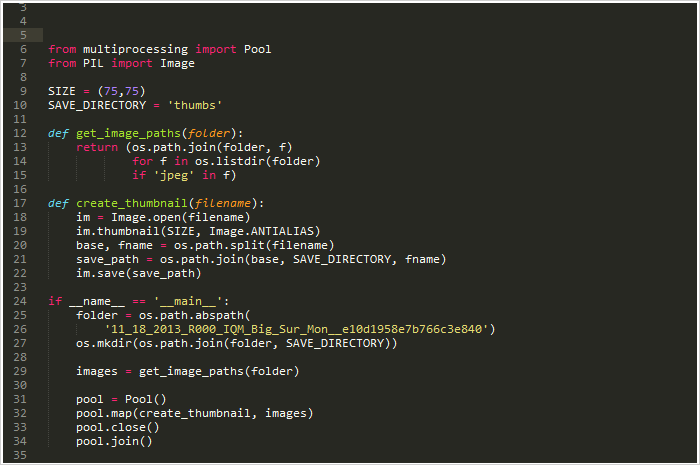
示例 2:生成上千张图像的缩略图: 现在咱们看一年计算密集型的任务!我最常遇到的这类问题之一就是大量图像文件夹的处理。 其中一项任务就是创建缩略图。这也是并发中比较成熟的一项功能了。 基础单线程创建过程
作为示例来说稍微有点复杂。但其实就是传一个文件夹目录进来,获取到里面所有的图片,分别创建好缩略图然后保存到各自的目录当中。 在我的电脑上,处理大约6000张图片大约耗时27.9秒. 如果使用并发map处理替代其中的for循环:
|

只用了5.6 秒!
就改了几行代码速度却能得到如此巨大的提升。最终版本的处理速度还要更快。因为我们将计算密集型与IO密集型任务分派到各自独立的线程和进程当中, 这也许会容易造成死锁,但相对于map强劲的功能,通过简单的调试我们最终总能设计出优美、高可靠性的程序。就现在而言,也别无它法。
好了。来感受一下一行代码的并发程序吧。
转载python并行运算实例的更多相关文章
- python基础——实例属性和类属性
python基础——实例属性和类属性 由于Python是动态语言,根据类创建的实例可以任意绑定属性. 给实例绑定属性的方法是通过实例变量,或者通过self变量: class Student(objec ...
- python 发送邮件实例
留言板回复作者邮件提醒 -----------2016-5-11 15:03:58-- source:python发送邮件实例
- python Cmd实例之网络爬虫应用
python Cmd实例之网络爬虫应用 标签(空格分隔): python Cmd 爬虫 废话少说,直接上代码 # encoding=utf-8 import os import multiproces ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- python 创建实例--待完善
今天好好琢磨一下 python 创建实例的先后顺序 一. 就定义一个普通类 Util (默认)继承自 object,覆写 new ,init 方法 class Util(object): def __ ...
- pcapng文件的python解析实例以及抓包补遗
为了弥补pcap文件的缺陷,让抓包文件可以容纳更多的信息,pcapng格式应运而生.关于它的介绍详见<PCAP Next Generation Dump File Format> 当前的w ...
- 生产消费者模式与python+redis实例运用(中级篇)
上一篇文章介绍了生产消费者模式与python+redis实例运用(基础篇),但是依旧遗留了一个问题,就是如果消费者消费的速度跟不上生产者,依旧会浪费我们大量的时间去等待,这时候我们就可以考虑使用多进程 ...
随机推荐
- mysql 假设存在id则设数据自添加1 ,不存在则加入。java月份计算比較
</pre><pre name="code" class="sql">INSERT INTO invite_rejectlog_num ...
- xampp中mysql设置密码
发现网上的解决办法都比较过时.嗯,解决办法很简单. 打开浏览器localhost:[port]/phpmyadmin/ 点击用户账户选项 选择用户名为root,Host name为localhost也 ...
- C函数调用与栈
这篇blog试图说明这么一个问题,当一个c函数被调用时,一个栈帧(stack frame)是如何被建立,又如何被消除的.这些细节跟操作系统平台及编译器的实现有关,下面的描述是针对运行在Linux的gc ...
- js中判断按键的方法
// 通过证件号码查询人员基本信息,响应回车事件的js函数, $('#sfwwsss [name="AAC002"]').keydown(function(event) { var ...
- HTML5 总结-地理定位-6
HTML5 地理定位 定位用户的位置 HTML5 Geolocation API 用于获得用户的地理位置. 鉴于该特性可能侵犯用户的隐私,除非用户同意,否则用户位置信息是不可用的. 浏览器支持 Int ...
- mysql支持emoji解决办法
mysql显示不了emoji表情或者显示??,原因这里不解释,直接说解决办法.(主要就是修改utf8mb4) 1.修改表 ALTER TABLE `TABLE_NAME` CHARACTER SET ...
- YII框架实现排序
YII框架实现排序 用YII2实现批量修改排序功能,如下图 控制器: /** * Lists all CollectionAlbum models. * @return mixed */ public ...
- PowerShell入门(序):为什么需要PowerShell?
原文:http://www.cnblogs.com/ceachy/archive/2013/01/23/PowerShellPreface.html 曾几何时,微软的服务器操作系统因为缺乏一个强大的S ...
- FPGA知识大梳理(三)verilogHDL语法入门(2)知识汇总
1,时序逻辑.将上次的练习修改成时序逻辑会如何设计. always @ (posedge clock) 2,block 与unblocking A,有clock的always中通常使用nonbloc ...
- 3,C语言文件读写
这两天看到一个关于文件读写的题目,索性就把相关内容总结下. C语言文件读写,无非是几个读写函数的应用,fopen(),fread(),fwrite()等,下面简单介绍下. 一.fopen() 函数原型 ...