python 爬虫时遇到问题及解决
源代码:
#unicoding=utf-8
import re
import urllib
def gethtml(url):
html=urllib.urlopen(url)
page=html.read()
return page
def img(page):
reg=r'src="(.+?\jpg)" alt'
imgre=re.compile(reg)
imglist=re.findall(imgre,page)
x=0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
#page=gethtml("http://www.51tietu.net/tp/")
page=gethtml("http://mm.51tietu.net/qingchun/90/")
img(page)
这样执行的话,会出现IOError 大致意思时文件操作时,出现错误
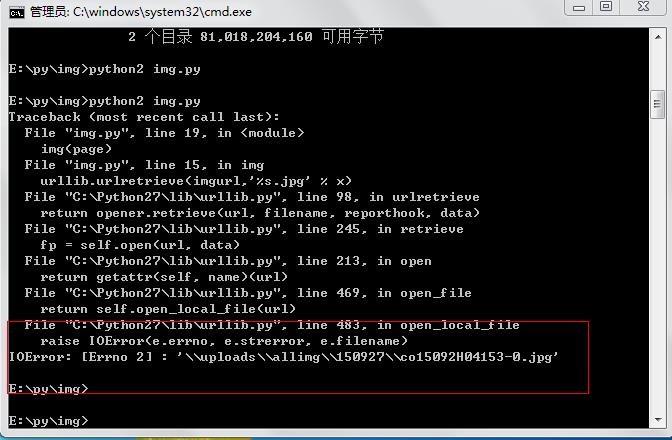
在这里可以看到IOError后跟着你抓取到的jip文件的路径,但是这个路径不是整个url的路径,所以才会在urlretrieve调用imgurl的时候报错。
去网站查看整个URL

因此可以根据图中的url进行修改代码, 想法:可以在urlretrieve中把url补完整,之后代码如下
#unicoding=utf-8
import re
import urllib
def gethtml(url):
html=urllib.urlopen(url)
page=html.read()
return page
def img(page):
reg=r'src="(.+?\jpg)" alt'
imgre=re.compile(reg)
imglist=re.findall(imgre,page)
x=0
for imgurl in imglist:
urllib.urlretrieve('http://mm.51tietu.net'+imgurl,'%s.jpg' % x)
x+=1
#page=gethtml("http://www.51tietu.net/tp/")
page=gethtml("http://mm.51tietu.net/qingchun/90/")
img(page)
之后再进行运行的话,就可以将图片爬取到本地了。
效果如下:

python 爬虫时遇到问题及解决的更多相关文章
- Python爬虫老是被封的解决方法【面试必问】
在爬取的过程中难免发生 ip 被封和 403 错误等等,这都是网站检测出你是爬虫而进行反爬措施,在这里为大家总结一下 Python 爬虫动态 ip 代理防止被封的方法. PS:另外很多人在学习Pyth ...
- python爬虫时,解决编码方式问题的万能钥匙(uicode,utf8,gbk......)
转载 原文:https://blog.csdn.net/xiongzaiabc/article/details/81008330 无论遇到的网页代码是何种编码方式,都可以用以下方法统一解决 imp ...
- Python 爬虫常见的坑和解决方法
1.请求时出现HTTP Error 403: Forbidden headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23. ...
- python爬虫框架scrapy问题的解决
2016-09-24:今天的弄了一天的scrapy的环境的配置的,linux很多的学过的事情都忘记啦.理论和实践的结合还是非常的重要的,不光要学会思考,更要学会总结纪录.还要多多回忆的和复习.学习了不 ...
- Python爬虫技术:爬虫时如何知道是否代理ip伪装成功?
前言本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. python爬虫时如何知道是否代理ip伪装成功: 有时候我们的爬虫程序添加了 ...
- Python爬虫:设置Cookie解决网站拦截并爬取蚂蚁短租
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: Eastmount PS:如有需要Python学习资料的小伙伴可以加 ...
- 从python爬虫引发出的gzip,deflate,sdch,br压缩算法分析
今天在使用python爬虫时遇到一个奇怪的问题,使用的是自带的urllib库,在解析网页时获取到的为b'\x1f\x8b\x08\x00\x00\x00\x00...等十六进制数字,尝试使用chard ...
- Python爬虫之xpath语法及案例使用
Python爬虫之xpath语法及案例使用 ---- 钢铁侠的知识库 2022.08.15 我们在写Python爬虫时,经常需要对网页提取信息,如果用传统正则表达去写会增加很多工作量,此时需要一种对数 ...
- python爬虫中文乱码解决方法
python爬虫中文乱码 前几天用python来爬取全国行政区划编码的时候,遇到了中文乱码的问题,折腾了一会儿,才解决.现特记录一下,方便以后查看. 我是用python的requests和bs4库来实 ...
随机推荐
- java基础知识——程序员面试基础
一.面向对象的特征有哪些? 答:①.抽象:抽象是忽略一个主题中与当前目标无关的那些方面,一边更充分的注意与当前目标有关的方面.抽象并不打算了解全面问题,而是选择其中的一部分,暂时不用部分细节.抽象包括 ...
- java教程
http://www.xfonlineclass.com/ http://java.itcast.cn/ http://www.xasxt.com/index.php/list/161 [UI]htt ...
- JSP中Filter中访问Spring管理的beans
@Override public void init(FilterConfig filterConfig) { //unchecked = filterConfig.getInitParameter ...
- Redis 作为缓存服务器的配置
随着redis的发展,越来越多的架构用它取代了memcached作为缓存服务器的角色,它有几个很突出的特点:1. 除了Hash,还提供了Sorted Set, List等数据结构2. 可以持久化到磁盘 ...
- ~/microwindows-0.89pre8/src/bin$ ./nano-X error:Cannot bind to named socket
GUI:microwindows-0.89pre8+nona-X you are successful compiling, run nano-X,below is information: ~/mi ...
- Python Challenge 过关心得(0)
最近开始用Openerp进行开发,在python语言本身上并没有什么太大的进展,于是决定利用空闲时间做一点python练习. 最终找到了这款叫做Python Challenge(http://www. ...
- 会场安排问题--nyoj题目14
会场安排问题 时间限制:3000 ms | 内存限制:65535 KB 难度:4 描述 学校的小礼堂每天都会有许多活动,有时间这些活动的计划时间会发生冲突,需要选择出一些活动进行举办.小刘的工 ...
- Nginx 变量漫谈(八)
与 $arg_XXX 类似,我们在 (二) 中提到过的内建变量 $cookie_XXX 变量也会在名为 XXX 的 cookie 不存在时返回特殊值“没找到”: location /test ...
- gdal vc++ 配置说明
1在VC中,打开菜Tool-Option,在Directories页面中的Library files中和Include files中分别添加GDAL的LIB文件目录和INCLUDE文件目录2打开菜 ...
- stream~filestream
http://blog.csdn.net/feliciafay/article/details/6157356 http://blog.csdn.net/feliciafay/article/deta ...