MySQL:查询、修改(二)
干货:
使用SELECT查询的基本语句
SELECT * FROM <表名>可以查询一个表的所有行和所有列的数据。SELECT查询的结果是一个二维表。使用
SELECT *表示查询表的所有列,使用SELECT 列1, 列2, 列3则可以仅返回指定列,这种操作称为投影。SELECT`语句可以对结果集的列进行重命名。使用
ORDER BY可以对结果集进行排序;可以对多列进行升序、倒序排序。使用
LIMIT <M> OFFSET <N>可以对结果集进行分页,每次查询返回结果集的一部分;分页查询需要先确定每页的数量和当前页数,然后确定LIMIT和OFFSET的值。使用SQL提供的聚合查询,我们可以方便地计算总数、合计值、平均值、最大值和最小值;聚合查询也可以添加
WHERE条件。使用多表查询可以获取M x N行记录;多表查询的结果集可能非常巨大,要小心使用。
JOIN查询需要先确定主表,然后把另一个表的数据“附加”到结果集上;INNER JOIN是最常用的一种JOIN查询,它的语法是
SELECT ... FROM <表1> INNER JOIN <表2> ON <条件...>;JOIN查询仍然可以使用WHERE条件和ORDER BY排序。使用
INSERT,我们就可以一次向一个表中插入一条或多条记录。使用
UPDATE,我们就可以一次更新表中的一条或多条记录。使用
DELETE,我们就可以一次删除表中的一条或多条记录。
三、查询数据
1.基本查询
SELECT * FROM <表名>
2.条件查询
SELECT * FROM <表名> WHERE <条件表达式>
| 条件 | 表达式举例1 | 表达式举例2 | 说明 |
|---|---|---|---|
| 使用=判断相等 | score = 80 | name = ‘abc’ | 字符串需要用单引号括起来 |
| 使用>判断大于 | score > 80 | name > ‘abc’ | 字符串比较根据ASCII码,中文字符比较根据数据库设置 |
| 使用>=判断大于或相等 | score >= 80 | name >= ‘abc’ | |
| 使用<判断小于 | score < 80 | name <= ‘abc’ | |
| 使用<=判断小于或相等 | score <= 80 | name <= ‘abc’ | |
| 使用<>判断不相等 | score <> 80 | name <> ‘abc’ | |
| 使用LIKE判断相似 | name LIKE ‘ab%’ | name LIKE ‘%bc%’ | %表示任意字符,例如’ab%’将匹配’ab’,’abc’,’abcd’;%表示0个到多个,_表示1个 |
优先级:NOT、AND、OR
3.投影查询
SELECT 列1, 列2, 列3 FROM <表名> WHERE <条件>
如果我们只希望返回某些列的数据,而不是所有列的数据,我们可以用SELECT 列1, 列2, 列3 FROM ...,让结果集仅包含指定列。这种操作称为投影查询。
给查询的列起列名,结果集的列名就可以与原表的列名不同
SELECT 列1 别名1, 列2 别名2, 列3 别名3 FROM <表名> WHERE <条件>
4.排序
使用SELECT查询时,查询结果集通常是按照id排序的,也就是根据主键排序。如果我们要根据其他条件排序怎么办?可以加上ORDER BY子句(默认升序)。
升序:ORDER BY 列名 (ASC可省略)
降序:ORDER BY 列名 DESC
如果score列有相同的数据,要进一步排序,可以继续添加列名。例如,使用ORDER BY score DESC, gender表示先按score列倒序,如果有相同分数的,再按gender列排序:
SELECT id, name, gender, score FROM students ORDER BY score DESC, gender;
如果有WHERE子句,那么ORDER BY子句要放到WHERE子句后面。例如,查询一班的学生成绩,并按照倒序排序:
SELECT id, name, gender, score
FROM students
WHERE class_id = 1
ORDER BY score DESC;
5.分页查询
使用SELECT查询时,如果结果集数据量很大,比如几万行数据,放在一个页面显示的话数据量太大,不如分页显示,每次显示100条。
SELECT 列1, 列2, 列3 FROM <表名> WHERE <条件> LIMIT <M> OFFSET <N>
要实现分页功能,实际上就是从结果集中显示第1-100条记录作为第1页,显示第101-200条记录作为第2页,以此类推。因此,分页实际上就是从结果集中“截取”出第M~N条记录。
分页查询的关键在于,首先要确定每页需要显示的结果数量pageSize(这里是3),然后根据当前页的索引pageIndex(从1开始),确定LIMIT和OFFSET应该设定的值:
LIMIT总是设定为pageSize;OFFSET计算公式为pageSize * (pageIndex - 1)。
注意
OFFSET是可选的,如果只写LIMIT 15,那么相当于LIMIT 15 OFFSET 0。- 在MySQL中,
LIMIT 15 OFFSET 30还可以简写成LIMIT 30, 15。 - 使用
LIMIT <M> OFFSET <N>分页时,随着N越来越大,查询效率也会越来越低。
例:把结果集分页,每页3条记录。要获取第1页的记录,可以使用LIMIT 3 OFFSET 0(注意SQL记录集的索引从0开始)
SELECT id, name, gender, score
FROM students
ORDER BY score DESC
LIMIT 3 OFFSET 0;
如果要查询第2页,那么我们只需要“跳过”头3条记录,也就是对结果集从3号记录开始查询,把OFFSET设定为3:
SELECT id, name, gender, score
FROM students
ORDER BY score DESC
LIMIT 3 OFFSET 3;
类似的,查询第3页的时候,OFFSET应该设定为6:
SELECT id, name, gender, score
FROM students
ORDER BY score DESC
LIMIT 3 OFFSET 6;
6.聚合查询
| 函数 | 说明 |
|---|---|
| SUM | 计算某一列的合计值,该列必须为数值类型 |
| AVG | 计算某一列的平均值,该列必须为数值类型 |
| MAX | 计算某一列的最大值 |
| MIN | 计算某一列的最小值 |
| COUNT | 查询所有列的行数 |
count
例子:查询students表一共有多少条记录
SELECT COUNT(*) FROM students;
COUNT(*)表示查询所有列的行数,要注意聚合的计算结果虽然是一个数字,但查询的结果仍然是一个二维表,只是这个二维表只有一行一列,并且列名是COUNT(*)。
通常,使用聚合查询时,我们应该给列名设置一个别名,便于处理结果:
SELECT COUNT(*) num FROM students;
COUNT(*)和COUNT(id)实际上是一样的效果。另外注意,聚合查询同样可以使用WHERE条件,因此我们可以方便地统计出有多少男生、多少女生、多少80分以上的学生等:
SELECT COUNT(*) boys FROM students WHERE gender = 'M';
MAX()和MIN()
注意,MAX()和MIN()函数并不限于数值类型。如果是字符类型,MAX()和MIN()会返回排序最后和排序最前的字符。
AVG
要统计男生的平均成绩,我们用下面的聚合查询:
SELECT AVG(score) average FROM students WHERE gender = 'M';
要特别注意:如果聚合查询的WHERE条件没有匹配到任何行,COUNT()会返回0,而SUM()、AVG()、MAX()和MIN()会返回NULL.
每页3条记录,通过聚合查询获得总页数:
SELECT CEILING(COUNT(*) / 3) FROM students;
分组
统计各班的男生和女生人数:
SELECT class_id, gender, COUNT(*) num FROM students GROUP BY class_id, gender;
7.多表查询
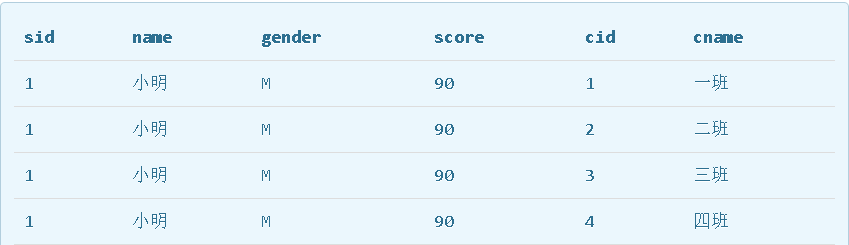
笛卡尔查询:查询的结果也是一个二维表,它是students表和classes表的“乘积”,即students表的每一行与classes表的每一行都两两拼在一起返回。结果集的列数是students表和classes表的列数之和,行数是students表和classes表的行数之积。
可能会出现结果集有两列id和两列name,两列id是因为其中一列是students表的id,而另一列是classes表的id,但是在结果集中,不好区分。两列name同理。要解决这个问题,我们仍然可以利用投影查询的“设置列的别名”来给两个表各自的id和name列起别名:
SELECT
students.id sid,
students.name,
students.gender,
students.score,
classes.id cid,
classes.name cname
FROM students, classes;
简洁写法:
SELECT
s.id sid,
s.name,
s.gender,
s.score,
c.id cid,
c.name cname
FROM students s, classes c;
8.连接查询
SELECT ... FROM tableA ??? JOIN tableB ON tableA.column1 = tableB.column2;
连接查询是另一种类型的多表查询。连接查询对多个表进行JOIN运算,简单地说,就是先确定一个主表作为结果集,然后,把其他表的行有选择性地“连接”在主表结果集上。
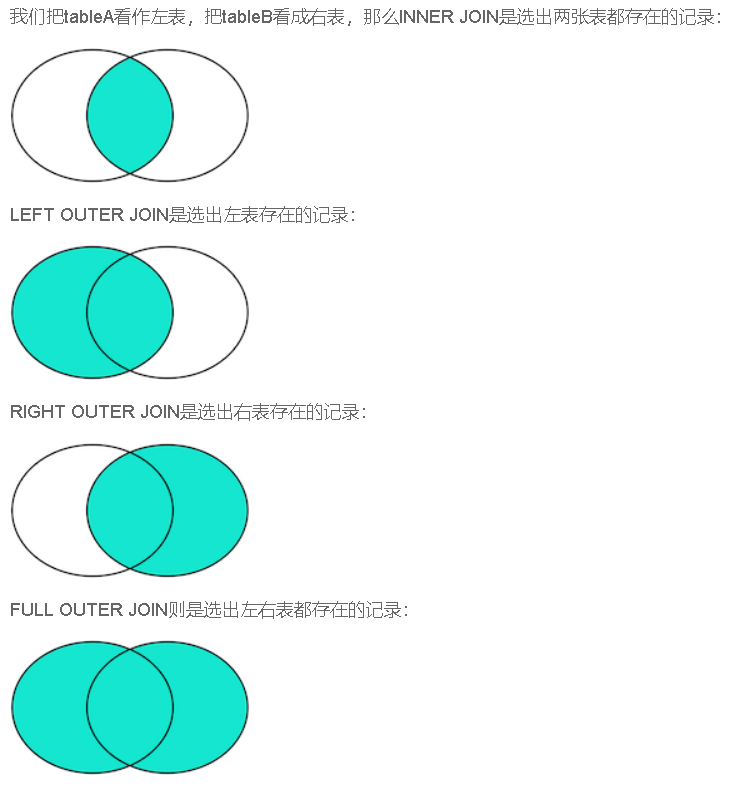
INNER JOIN
INNER JOIN只返回同时存在于两张表的行数据
先确定主表,仍然使用FROM <表1>的语法;
再确定需要连接的表,使用INNER JOIN <表2>的语法;
然后确定连接条件,使用ON <条件...>,这里的条件是s.class_id = c.id,表示students表的class_id列与classes表的id列相同的行需要连接;
可选:加上WHERE子句、ORDER BY等子句。
例:选出所有学生,同时返回班级名称
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
INNER JOIN classes c
ON s.class_id = c.id;
OUTER JOIN
RIGHT OUTER JOIN返回右表都存在的行。如果某一行仅在右表存在,那么结果集就会以NULL填充剩下的字段。
LEFT OUTER JOIN则返回左表都存在的行。如果我们给students表增加一行,并添加class_id=5,由于classes表并不存在id=5的行,所以,LEFT OUTER JOIN的结果会增加一行,对应的class_name是NULL。
FULL OUTER JOIN,它会把两张表的所有记录全部选择出来,并且,自动把对方不存在的列填充为NULL。
四、修改数据
关系数据库的基本操作就是增删改查,即CRUD:Create、Retrieve、Update、Delete
1.INSERT
基本语法:
INSERT INTO <表名> (字段1, 字段2, ...) VALUES (值1, 值2, ...);
例如,我们向students表插入一条新记录,先列举出需要插入的字段名称,然后在VALUES子句中依次写出对应字段的值:
INSERT INTO students (class_id, name, gender, score) VALUES (2, '大牛', 'M', 80);
-- 查询并观察结果:
SELECT * FROM students;
注意到我们并没有列出id字段,也没有列出id字段对应的值,这是因为id字段是一个自增主键,它的值可以由数据库自己推算出来。此外,如果一个字段有默认值,那么在INSERT语句中也可以不出现。
要注意,字段顺序不必和数据库表的字段顺序一致,但值的顺序必须和字段顺序一致。也就是说,可以写INSERT INTO students (score, gender, name, class_id) ...,但是对应的VALUES就得变成(80, 'M', '大牛', 2)。
一次性添加多条记录,只需要在VALUES子句中指定多个记录值,每个记录是由(...)包含的一组值:
INSERT INTO students (class_id, name, gender, score) VALUES
(1, '大宝', 'M', 87),
(2, '二宝', 'M', 81);
SELECT * FROM students;
2.UPDATE
基本语法:
UPDATE <表名> SET 字段1=值1, 字段2=值2, ... WHERE ...;
例如,我们想更新students表id=1的记录的name和score这两个字段,先写出UPDATE students SET name='大牛', score=66,然后在WHERE子句中写出需要更新的行的筛选条件id=1
UPDATE students SET name='大牛', score=66 WHERE id=1;
-- 查询并观察结果:
SELECT * FROM students WHERE id=1;
注意到UPDATE语句的WHERE条件和SELECT语句的WHERE条件其实是一样的,因此完全可以一次更新多条记录:
UPDATE students SET name='小牛', score=77 WHERE id>=5 AND id<=7;
-- 查询并观察结果:
SELECT * FROM students;
在UPDATE语句中,更新字段时可以使用表达式。例如,把所有80分以下的同学的成绩加10分:
UPDATE students SET score=score+10 WHERE score<80;
-- 查询并观察结果:
SELECT * FROM students;
如果WHERE条件没有匹配到任何记录,UPDATE语句不会报错,也不会有任何记录被更新。
最后,要特别小心的是,UPDATE语句可以没有WHERE条件,例如:
UPDATE students SET score=60;
这时,整个表的所有记录都会被更新。所以,在执行UPDATE语句时要非常小心,最好先用SELECT语句来测试WHERE条件是否筛选出了期望的记录集,然后再用UPDATE更新。
在使用MySQL这类真正的关系数据库时,UPDATE语句会返回更新的行数以及WHERE条件匹配的行数。
3.DELETE
基本语法:
DELETE FROM <表名> WHERE ...;
例如,我们想删除students表中id=1的记录,就需要这么写:
DELETE FROM students WHERE id=1;
-- 查询并观察结果:
SELECT * FROM students;
注意到DELETE语句的WHERE条件也是用来筛选需要删除的行,因此和UPDATE类似,DELETE语句也可以一次删除多条记录:
DELETE FROM students WHERE id>=5 AND id<=7;
-- 查询并观察结果:
SELECT * FROM students;
最后,要特别小心的是,和UPDATE类似,不带WHERE条件的DELETE语句会删除整个表的数据:
DELETE FROM students;
这时,整个表的所有记录都会被删除。所以,在执行DELETE语句时也要非常小心,最好先用SELECT语句来测试WHERE条件是否筛选出了期望的记录集,然后再用DELETE删除。
在使用MySQL这类真正的关系数据库时,DELETE语句也会返回删除的行数以及WHERE条件匹配的行数。
MySQL:查询、修改(二)的更多相关文章
- Mysql查询(笔记二)
1.两结构相同的表数据间移植 Inset into 表一 Select 字段1,字段2,....字段n from表二 建立数据库时设置数据库编码 create database 数据库名 charse ...
- mysql常用快速查询修改操作
mysql常用快速查询修改操作 一.查找并修改非innodb引擎为innodb引擎 # 通用操作 mysql> select concat('alter table ',table_schema ...
- mysql 数据库 添加查询 修改 删除
cmd 命令行模式操作数据库 添加查询 修改 删除 ( 表 字段 数据) 一 查看数据库.表.数据字段.数据 1 首先配置环境变量 进入mysql 或者通过一键集成工具 打开mysql命令行 ...
- 第四章 MySQL高级查询(二)
第四章 MySQL高级查询(二) 一.EXISTS子查询 在执行create 或drop语句之前,可以使用exists语句判断该数据库对像是否存在,返回值是true或false.除此之外,exists ...
- MySQL慢查询(二) - pt-query-digest详解慢查询日志 pt-query-digest 慢日志分析
随笔 - 66 文章 - 0 评论 - 19 MySQL慢查询(二) - pt-query-digest详解慢查询日志 一.简介 pt-query-digest是用于分析mysql慢查询的一个工具,它 ...
- navicat for Mysql查询数据不能直接修改
navicat for Mysql查询数据不能直接修改 原来的sql语句: <pre> select id,name,title from table where id = 5;</ ...
- MySQL查询性能优化---高性能(二)
转载地址:https://segmentfault.com/a/1190000011330649 避免向数据库请求不需要的数据 在访问数据库时,应该只请求需要的行和列.请求多余的行和列会消耗MySql ...
- 十二、MySQL 查询数据
MySQL 查询数据 MySQL 数据库使用SQL SELECT语句来查询数据. 你可以通过 mysql> 命令提示窗口中在数据库中查询数据,或者通过PHP脚本来查询数据. 语法 以下为在MyS ...
- MySQl查询区分大小写的解决办法
通过查询资料发现需要设置collate(校对) . collate规则: *_bin: 表示的是binary case sensitive collation,也就是说是区分大小写的 *_cs: ca ...
- Mysql索引总结(二)
在数据库表中,对字段建立索引可以大大提高查询速度.假如我们创建了一个 mytable表: ) NOT NULL ); 在查找username="admin"的记录 SELECT * ...
随机推荐
- [转]Gnome桌面的录屏插件easyscreencast
原文地址:https://www.linuxprobe.com/gnome-easyscreencast.html
- webpack四个基础概念
本文参考自:https://www.cnblogs.com/xiaohuochai/p/7002344.html webpack 核心概念:入口(entry).输出(output).加载器(loade ...
- Java多线程看这一篇就足够了(吐血超详细总结)
进程与线程 进程是程序的一次动态执行过程,它需要经历从代码加载,代码执行到执行完毕的一个完整的过程,这个过程也是进程本身从产生,发展到最终消亡的过程.多进程操作系统能同时达运行多个进程(程序),由于 ...
- JS系列:数据类型详细讲解
ctrl+B加粗 ### 数据类型: - 1.number数字类型 NaN:not a number 不是一个数 ,但他是数字类型 isNaN:检测当前值是否不是有效数字,返回true代表不是有效数字 ...
- 2019最新版Java程序员零基础入门视频教程资料(全套)
为了解决Java学习初学者在网上找视频难的事情,本人整理了一份2019年度最新版的Java学习视频教程.希望看到这份视频的你们都能找到一份称心的工作,技术上都能得到进一步的提升,好东西就要分享给你们, ...
- [转帖]POW , POS 与 DPOS 一切都为了共识
POW , POS 与 DPOS 一切都为了共识 https://www.jianshu.com/p/f99e8fe57c9a 共识机制的背景 加密货币都是去中心化的,去中心化的基础就是P2P节点 ...
- redis单机多节点集群
# ##安装Redis redis安装参考 https://www.cnblogs.com/renxixao/p/11442770.html Reids安装包里有个集群工具,要复制到/usr/loca ...
- js中常见的创建对象的方法(1)
工厂模式:抽象了创建具体对象的过程 function createPerson(name, age, job){ var obj = new Object(); obj.name = name; ob ...
- 宝塔linux定时任务设置
选择shell脚本选择执行周期在脚本内容内写入 curl -sS --connect-timeout 10 -m 60 '此处为地址链接';如下图所示:
- Django框架之第二篇--app注册、静态文件配置、form表单提交、pycharm连接数据库、django使用mysql数据库、表字段的增删改查、表数据的增删改查
本节知识点大致为:静态文件配置.form表单提交数据后端如何获取.request方法.pycharm连接数据库,django使用mysql数据库.表字段的增删改查.表数据的增删改查 一.创建app,创 ...