Python实现堆
堆 (heap) 是一种经过排序的完全二叉树,其中任一非叶子节点的值均不大于(或不小于)其左孩子和右孩子节点的值。
注:定义来自百度百科。
堆,又被为优先队列(priority queue)。尽管名为优先队列,但堆并不是队列。
其他概念解释
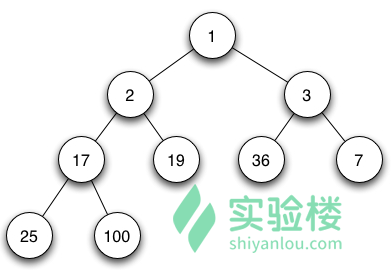
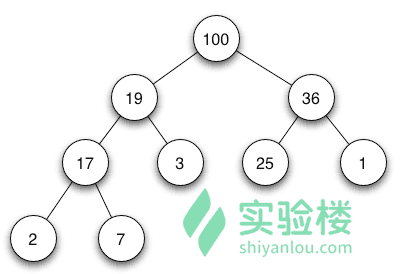
最大堆 根结点的键值是所有堆结点键值中最大者。
最小堆 根结点的键值是所有堆结点键值中最小者。
最小堆
最大堆
在接下来的内容里,我们将逐步介绍堆的具体功能是如何实现的。
堆有两点需要了解,一是堆一般采用完全二叉树;二是堆中的每一个节点都大于其左右子节点(大顶堆),或者堆中每一个节点都小于其左右子节点(小顶堆)。
1. 创建 heap 类
class heap(object):
def __init__(self):
#初始化一个空堆,使用数组来在存放堆元素,节省存储
self.data_list = []
2. 添加 get_parent_index 函数
def get_parent_index(self,index):
#返回父节点的下标
if index == 0 or index > len(self.data_list) -1:
return None
else:
return (index -1) >> 1
3. 添加 swap 函数
def swap(self,index_a,index_b):
#交换数组中的两个元素
self.data_list[index_a],self.data_list[index_b] = self.data_list[index_b],self.data_list[index_a]
4. 添加 insert 函数
def insert(self,data):
#先把元素放在最后,然后从后往前依次堆化
#这里以大顶堆为例,如果插入元素比父节点大,则交换,直到最后
self.data_list.append(data)
index = len(self.data_list) -1
parent = self.get_parent_index(index)
#循环,直到该元素成为堆顶,或小于父节点(对于大顶堆)
while parent is not None and self.data_list[parent] < self.data_list[index]:
#交换操作
self.swap(parent,index)
index = parent
parent = self.get_parent_index(parent)
5. 添加 removeMax 函数
def removeMax(self):
#删除堆顶元素,然后将最后一个元素放在堆顶,再从上往下依次堆化
remove_data = self.data_list[0]
self.data_list[0] = self.data_list[-1]
del self.data_list[-1] #堆化
self.heapify(0)
return remove_data
6. 添加 heapify 函数
def heapify(self,index):
#从上往下堆化,从index 开始堆化操作 (大顶堆)
total_index = len(self.data_list) -1
while True:
maxvalue_index = index
if 2*index +1 <= total_index and self.data_list[2*index +1] > self.data_list[maxvalue_index]:
maxvalue_index = 2*index +1
if 2*index +2 <= total_index and self.data_list[2*index +2] > self.data_list[maxvalue_index]:
maxvalue_index = 2*index +2
if maxvalue_index == index:
break
self.swap(index,maxvalue_index)
index = maxvalue_index
Python实现堆的更多相关文章
- python学习笔记29(python中堆的使用)
堆(heap):优先队列的一种,使用优先队列能够以任意顺序增加对象,并且能在任意时间(可能在增加对象的同时)找到(也可能是移除)最小元素,比用于列表中min的方法要高效. Python中并没有独立的堆 ...
- 堆排、python实现堆排
一.堆-完全二叉树 堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),是不稳定排序 堆排序中的堆有大顶堆.小顶堆两种.他们都是完 ...
- 从一个集合中查找最大最小的N个元素——Python heapq 堆数据结构
Top N问题在搜索引擎.推荐系统领域应用很广, 如果用我们较为常见的语言,如C.C++.Java等,代码量至少也得五行,但是用Python的话,只用一个函数就能搞定,只需引入heapq(堆队列)这个 ...
- Python实现堆数据结构
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/3/18 19:47 # @Author : baoshan # @Site ...
- Python - 二叉树, 堆, headq 模块
二叉树 概念 二叉树是n(n>=0)个结点的有限集合,该集合或者为空集(称为空二叉树), 或者由一个根结点和两棵互不相交的.分别称为根结点的左子树和右子树组成. 特点 每个结点最多有两颗子树,所 ...
- 最小堆实现优先队列:Python实现
最小堆实现优先队列:Python实现 堆是一种数据结构,因为Heapsort而被提出.除了堆排序,“堆”这种数据结构还可以用于优先队列的实现. 堆首先是一个完全二叉树:它除了最底层之外,树的每一层的都 ...
- python数据结构之堆(heap)
本篇学习内容为堆的性质.python实现插入与删除操作.堆复杂度表.python内置方法生成堆. 区分堆(heap)与栈(stack):堆与二叉树有关,像一堆金字塔型泥沙:而栈像一个直立垃圾桶,一列下 ...
- python 链表、堆、栈
简介 很多开发在开发中并没有过多的关注数据结构,当然我也是,因此,我写这篇文章就是想要带大家了解一下这些分别是什么东西. 链表 概念:数据随机存储,并且通过指针表示数据之间的逻辑关系的存储结构. 链表 ...
- 技术专题—Python黑客【优质内容聚合贴】
作者:坏蛋链接:https://zhuanlan.zhihu.com/p/24645819来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 一.前言 本着知识分享,聚合优 ...
随机推荐
- 线程太多导致socket连接池爆满,进程启动不了
Issue: 某部机上跟其它机器的连接有问题,ping可以通,telnet端口不通,可以其它机器可以连接到该机器上的进程. java应用启动不起来,产生以下错误. java.net.SocketExc ...
- 6.学习springmvc的文件上传
一.文件上传前提与原理分析 1.文件上传必要前提: 2.文件上传原理分析: 3.需要引入的jar包: 二.传统方式文件上传程序 1.pom.xml <dependency> <gro ...
- NOIP 2013货车运输
当然这题有很多做法,但是我看到没有人写DSU的很惊奇 按照之前做连双向边题的经验,这题可以用并查集维护联通 然后对于每个询问\(x,y\),考虑启发式合并 当两个点集\(x,y\)合并时,一些涉及到其 ...
- 是什么让我走上Java之路?
选择方向,很多人都为根据自己的兴趣爱好和自己的能力所长而作出选择.那么是什么让我走上Java之路? 整个高三我有两门课程没有听过课,一门是数学,一门是物理.当时候物理没有听课的原因很简单,我有一本&l ...
- golang字节数组拷贝BlockCopy函数实现
在C#中,Buffer.BlockCopy(Array, Int32, Array, Int32, Int32) 函数使用比较广泛,其含义: 将指定数目的字节从起始于特定偏移量的源数组复制到起始于特定 ...
- MySQL索引原理(一)
MySQL索引原理 索引目的 索引的目的在于提高查询效率,可以类比字典,如果要查“mysql”这个单词,我们肯定需要定位到m字母,然后从下往下找到y字母,再找到剩下的sql.如果没有索引,那么你可能需 ...
- Vue系列——动态设置img标签的src属性
声明 本文转自:vue动态设置img的src路径 正文 相信开发的小伙伴已经遇到这个问题了,动态切换img标签的src时,写的路径就是不生效,原因是vue并没有把你的路径字符串当做路径来处理,而是直接 ...
- DVT JetBrains License Server(JetBrains授权服务器)2018 v1.1 最新版 含32位/64位
DVT JetBrains License Server是JetBrains系列软件授权服务器,支持2017版本得jetbrains pycharm,JetBrainswebstorm,JetBrai ...
- Python安装依赖包及开发工具转移到Visual Studio 2019
#pip升级pip install --upgrade pip#安装pillow图形库pip install pillow #安装二维码库 pip install MyQR PyCharm工具导入依赖 ...
- Python之快速排序代码
def quicksort(array): less = [] greater = [] if len(array) <= 1: return array pivot = array.pop() ...