13、SparkContext详解
一、SparkContext原理
1、图解
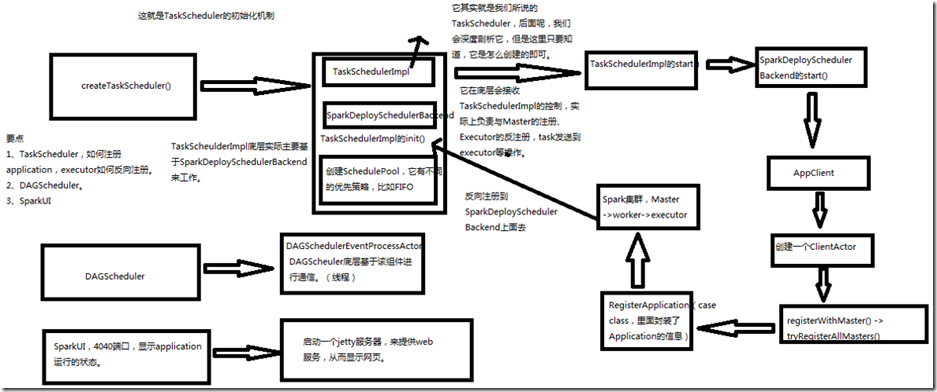
1、当driver启动后会去运行我们的application,在运行application的时候,所有spark程序的第一行都是先创建SparkContext,在创建SparkContext的时候,它的内部创建
两个非常重要的东西DAGSchedule和TaskSchedule,TaskSchedule在创建的时候就会向spark集群的master进行注册。 2、spark最核心的内部会创建3个东西,首先是会createTaskScheduler(),createTaskScheduler()里面会创建三个东西,首先是TaskSchedulerImpl(它其实就是TaskScheduler),
然后创建SparkDeploySchedulerBackend(它在底层会受TaskSchedulerImp的控制,实际上负责与Master的注册,Executor的反注册,Task发送到Executor等操作),然后调用
TaskSchedulerImpl的init()方法,创建SchedulerPool调度池 ,它有不同的优先策略,比如FIFO先进先出。 3、在创建完TaskSchedulerImpl和SparkDeploySchedulerBackend之后,是执行TaskSchedulerImpl的start()方法,这个方法内部实际上会调用SparkDeploySchedulerBackend的
start()方法,在这个start()方法里会创建AppClient,AppClient里会启动一个线程,也就是ClientActor,ClientActor会调用两个方法,registerWithMaster(),会去调用
tryRegisterAllMaster()。这两个方法会向master发送一个东西叫做RegisterApplication(case class,里面封装了application的信息),就会发送到spark集群的Master上面去,
后面回去找worker,然后启动executor,然后executor启动后会反向注册到SparkDeploySchedulerBackend上面去。这就是TaskScheduler的初始化机制。TaskSchedulerImpl底层
主要基于SparkDeploySchedulerBackend工作。 4、DAGScheduler创建的时候有一个非常重要的东西,DAGSchedulerEvenProcessActor,DAGScheduler底层基于该组件进行通讯(线程) 5、SparkUI。4040端口,线上application运行的状态,启动一个jetty服务器,来提供web服务,从而显示网页。
二、SparkContext源码
1、TaskScheduler创建
###SparkContext.scala // Create and start the scheduler
private[spark] var (schedulerBackend, taskScheduler) =
SparkContext.createTaskScheduler(this, master) //不同的提交模式,会创建不同的TaskScheduler
//standalone模式
case SPARK_REGEX(sparkUrl) =>
//TaskSchedulerImpl()底层通过操作一个SchedulerBackend,针对不同的种类的cluster(standalone、yarn和mesos),调度task。 //他也可以通过使用一个LocalBackend,并且将isLocal参数设置为true,来在本地模式下工作。 //它负责处理一些通用的逻辑,比如决定多个job的调度顺序,启动检查任务执行 //客户端首先应用调度initialize()方法和start()方法,然后通过runTasks()方法提交task sets
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new SparkDeploySchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler) ###TaskSchedulerImpl.scala def initialize(backend: SchedulerBackend) {
this.backend = backend
// temporarily set rootPool name to empty
rootPool = new Pool("", schedulingMode, 0, 0)
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
}
}
schedulableBuilder.buildPools()
}
TaskScheduler启动:
###TaskSchedulerImpl.scala
override def start() {
//重点是调用了SparkDeploySchedulerBackend类的start
backend.start()
if (!isLocal && conf.getBoolean("spark.speculation", false)) {
logInfo("Starting speculative execution thread")
import sc.env.actorSystem.dispatcher
sc.env.actorSystem.scheduler.schedule(SPECULATION_INTERVAL milliseconds,
SPECULATION_INTERVAL milliseconds) {
Utils.tryOrExit { checkSpeculatableTasks() }
}
}
}
###SparkDeploySchedulerBackend.scala
override def start() {
super.start()
// The endpoint for executors to talk to us
val driverUrl = AkkaUtils.address(
AkkaUtils.protocol(actorSystem),
SparkEnv.driverActorSystemName,
conf.get("spark.driver.host"),
conf.get("spark.driver.port"),
CoarseGrainedSchedulerBackend.ACTOR_NAME)
val args = Seq(
"--driver-url", driverUrl,
"--executor-id", "{{EXECUTOR_ID}}",
"--hostname", "{{HOSTNAME}}",
"--cores", "{{CORES}}",
"--app-id", "{{APP_ID}}",
"--worker-url", "{{WORKER_URL}}")
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
val libraryPathEntries = sc.conf.getOption("spark.executor.extraLibraryPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
// When testing, expose the parent class path to the child. This is processed by
// compute-classpath.{cmd,sh} and makes all needed jars available to child processes
// when the assembly is built with the "*-provided" profiles enabled.
val testingClassPath =
if (sys.props.contains("spark.testing")) {
sys.props("java.class.path").split(java.io.File.pathSeparator).toSeq
} else {
Nil
}
// Start executors with a few necessary configs for registering with the scheduler
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
val appUIAddress = sc.ui.map(_.appUIAddress).getOrElse("")
//ApplicationDescription非常重要,它代表了当前的这个
//application的一切情况
//包括application最大需要多少CPU core,每个slave上需要多少内存
val appDesc = new ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
appUIAddress, sc.eventLogDir, sc.eventLogCodec)
//创建APPClient
//APPClient是一个接口,它负责为application与Spark集群进行通信。
//它会接收一个Spark Master的URL,以及一个application,和
//一个集群事件的监听器,以及各种事件发生时监听器的回调函数
client = new AppClient(sc.env.actorSystem, masters, appDesc, this, conf)
client.start()
waitForRegistration()
}
2、DAGScheduler创建
###SparkContext.scala @volatile private[spark] var dagScheduler: DAGScheduler = _
try {
//DAGScheduler类实现了面向stage的调度机制的高层次的调度层,他会为每个job计算一个stage的DAG(有向无环图),
//追踪RDD和stage的输出是否被物化了(物化就是说,写入了磁盘或者内存等地方),并且寻找一个最少
//消耗(最优、最小)调度机制来运行job,它会将stage作为tasksets提交到底层的TaskSchedulerImple上,
//来在集群上运行它们(task)
//除了处理stage的DAG,它还负责决定运行每个task的最佳位置,基于当前的缓存状态,将这些最佳位置提交底层的
//TaskSchedulerImpl。此外,它会处理理由于shuffle输出文件丢失导致的失败,在这种情况下,旧的stage可能就会
//被重新提交,一个stage内部的失败,如果不是由于shuffle文件丢失所导致的,会被TAskSchedule处理,它会多次重试
//每一个task,直到最后,实在是不行了,才会去取消整个stage
dagScheduler = new DAGScheduler(this)
} catch {
case e: Exception => {
try {
stop()
} finally {
throw new SparkException("Error while constructing DAGScheduler", e)
}
}
}
3、SparkUI的创建
###SparkContext.scala // Initialize the Spark UI
private[spark] val ui: Option[SparkUI] =
if (conf.getBoolean("spark.ui.enabled", true)) {
Some(SparkUI.createLiveUI(this, conf, listenerBus, jobProgressListener,
env.securityManager,appName))
} else {
// For tests, do not enable the UI
None
} ###SparkUI.scall //默认端口
val DEFAULT_PORT = 4040
def createLiveUI(
sc: SparkContext,
conf: SparkConf,
listenerBus: SparkListenerBus,
jobProgressListener: JobProgressListener,
securityManager: SecurityManager,
appName: String): SparkUI = {
create(Some(sc), conf, listenerBus, securityManager, appName,
jobProgressListener = Some(jobProgressListener))
}
13、SparkContext详解的更多相关文章
- 在CentOS上编译安装MySQL 5.7.13步骤详解
MySQL 5.7主要特性 更好的性能 对于多核CPU.固态硬盘.锁有着更好的优化,每秒100W QPS已不再是MySQL的追求,下个版本能否上200W QPS才是用户更关心的. 更好的InnoDB存 ...
- spark[源码]-sparkContext详解[一]
spark简述 sparkContext在Spark应用程序的执行过程中起着主导作用,它负责与程序和spark集群进行交互,包括申请集群资源.创建RDD.accumulators及广播变量等.spar ...
- Java容器解析系列(13) WeakHashMap详解
关于WeakHashMap其实没有太多可说的,其与HashMap大致相同,区别就在于: 对每个key的引用方式为弱引用; 关于java4种引用方式,参考java Reference 网上很多说 弱引用 ...
- Appium自动化(13) - 详解 Keyboard 类里的方法和源码分析
如果你还想从头学起Appium,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1693896.html 前言 Keyboard 类在 a ...
- Jmeter 常用函数(13)- 详解 __machineIP
如果你想查看更多 Jmeter 常用函数可以在这篇文章找找哦 https://www.cnblogs.com/poloyy/p/13291704.html 作用 返回机器(电脑)IP 语法格式 ${_ ...
- 【小白学PyTorch】13 EfficientNet详解及PyTorch实现
参考目录: 目录 1 EfficientNet 1.1 概述 1.2 把扩展问题用数学来描述 1.3 实验内容 1.4 compound scaling method 1.5 EfficientNet ...
- Java(13)详解构造方法
作者:季沐测试笔记 原文地址:https://www.cnblogs.com/testero/p/15201600.html 博客主页:https://www.cnblogs.com/testero ...
- 13.Linux键盘驱动 (详解)
版权声明:本文为博主原创文章,未经博主允许不得转载. 在上一节分析输入子系统内的intput_handler软件处理部分后,接下来我们开始写input_dev驱动 本节目标: 实现键盘驱动,让开发板的 ...
- 【STM32H7教程】第13章 STM32H7启动过程详解
完整教程下载地址:http://forum.armfly.com/forum.php?mod=viewthread&tid=86980 第13章 STM32H7启动过程详解 本章教 ...
随机推荐
- Navicat 连接mysql 报错: Authentication plugin caching_ sha2_password cannot be loaded
出现这个错误的时候, 网上的资料都是修改mysql的登录信息的, ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password ...
- Ubuntu18.04防火墙相关
Ubuntu 18.04 LTS 系统中已经默认附带了 UFW 工具,如果您的系统中没有安装,可以在「终端」中执行如下命令进行安装: sudo apt install ufw 检查UFW状态 sudo ...
- iOS 播放系统自带铃声
播放声音代码例子 https://github.com/baitongtong/git-.git 给一个国外网址,苹果系统铃声以及自定义铃声免登陆免费下载:http://www.zedge.net/r ...
- 【转载】C#中使用List集合的Insert方法在指定位置插入数据
在C#的List集合等数据类型变量中,我们可以使用List集合的Insert方法在指定的索引位置插入一个新数据,例如指定在List集合的第一个位置写入一个新数据或者在List集合的中间某个位置插入个新 ...
- centOS学习part5:oracle 11g安装之环境准备
0 前几篇依次向大家介绍了centOS的基本安装以及常用软件的安装配置,接下来我们将挑战的是oracle 11g的安装配置.与之前安装的软件不一样的是,由于oracle并非开源免费软件(需要向orac ...
- ABAP开发环境终于支持以驼峰命名法自动格式化ABAP变量名了
Jerry进入SAP成都研究院前,一直是用C/C++开发,所以刚接触ABAP,对于她在某些语法环境下大小写敏感,某些环境下不敏感的特性很不适应.那时候Jerry深深地怀念之前在C/C++编程时遵循的驼 ...
- Http状态码502问题复盘
问题原因分析:502 bade gateway 一般都是upstream出错,对于PHP,造成502的原因常见的就是脚本执行超过timeout设置时间,或者timeout设置过大,导致PHP进程长时间 ...
- maven cmd 命令
1. mvn clean install :重新清理打包 2.详见:https://www.cnblogs.com/lukelook/p/11298168.html mvn versions:upd ...
- ES5_对象 与 继承
1. 对象的定义 //定义对象 function User(){ //在构造方法中定义属性 this.name = '张三'; this.age = 12; //在构造方法中定义方法: this.ru ...
- Python学习日记(十三) 递归函数和二分查找算法
什么是递归函数? 简单来说就是在一个函数中重复的调用自己本身的函数 递归函数在调用的时候会不断的开内存的空间直到程序结束或递归到一个次数时会报错 计算可递归次数: i = 0 def func(): ...