CMU Database Systems - Sorting,Aggregation,Join
Sorting
排序如果可在内存里面排,用经典的排序算法就ok,比如快排
问题在于,数据表中的的数据是很多的,没法一下都放到内存里面进行排序
所以就需要用到,外排,多路并归排序

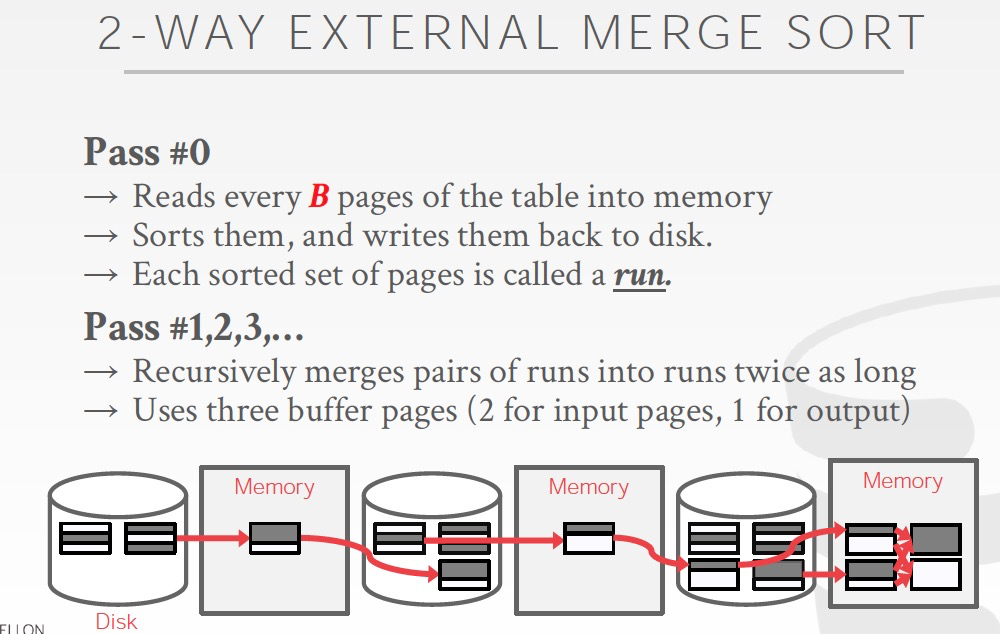
看下最简单的,2路并归排序,
设文件分为N个page,memory中一次最多可以放入B个pages
所以在sort过程,一次性可以载入B个page,在内存中page内排序,写回disk,称为一轮,run
那么如果一共N个page,需要N/B+1个run
在merge过程,如果双路并归排序,只需要用到3个page的buffer,多了也没用
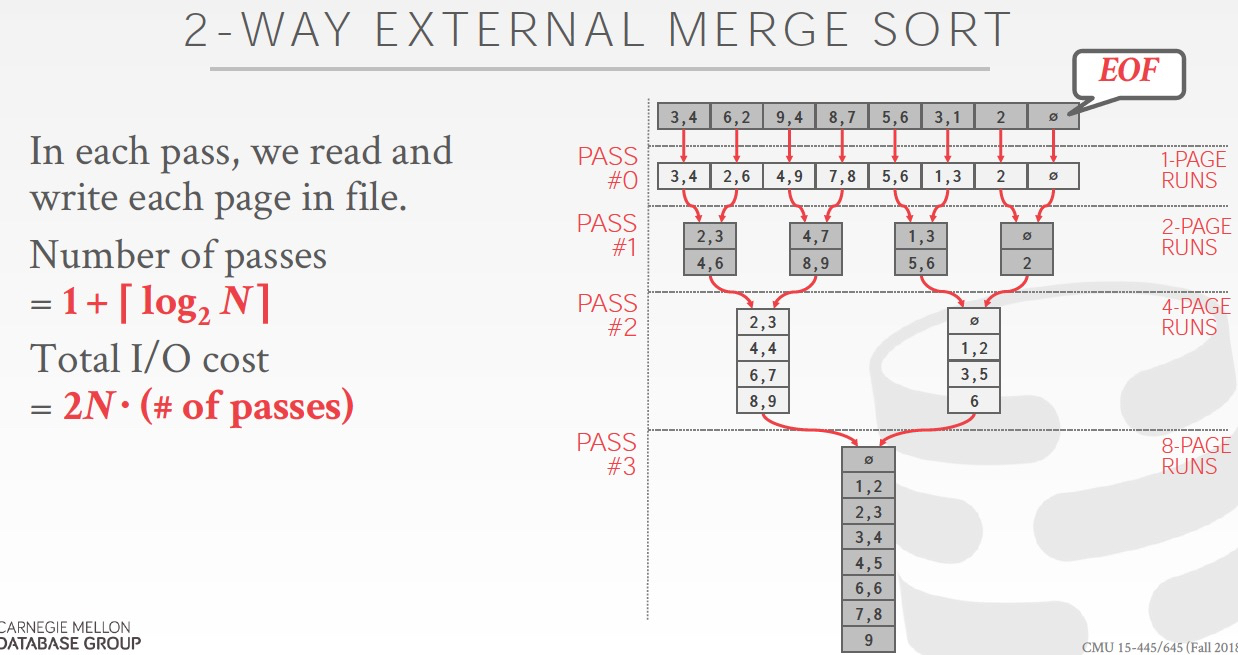
Merge过程的cost
每个pass都需要读写一遍所有的数据,cost为2N
2 way,所以一共有1 + logN个pass
多路并归排序的通用公式如下,
其他都比较容易理解,为什么way数是B-1?
因为memory一共B个buffer,需要留一个output,剩下的用于merge,所以最多是B-1路并归排序

如果我们有B+ index的情况下,
分两种情况,要排序的字段有Clustered B+索引,那么直接从左到右遍历叶子节点就好

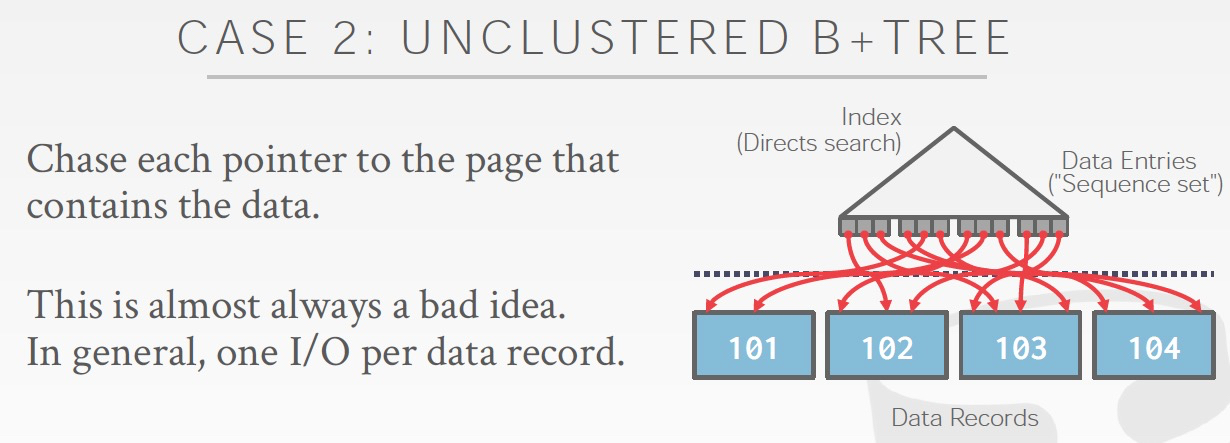
排序的字段不是Clustered B+索引,比如是secondary 索引
那么从索引里面只能获取到排好序的id,然后要通过id去Clustered B+索引中取真正的value,效率也很低,每个record都需要一次io
Aggregation
Aggregation有两种思路,
一种先排序sorting,然后再按顺序做aggregate
这个方法明显的问题,就是比较费,有些场景不需要sort,比如group by,distinct

所以第二种思路是Hashing,
在memory里面临时维护一个hash table,去重或聚合都在hash table上完成
问题就是,如果hash table太大,内存放不下怎么办?
所以解法的思路,放不下,就切开,切成能放下的一个个partition,并且要保证一个key的数据都在一个partition里面,这样只要保证内存能够放下一个partition就可以aggregate,不需要去读其他的partition
第一次partition划分成几个partition,如果内存B个buffer,划分成B-1个partition;如果划分完了某个partition还是放不下怎么办,那就继续划分,直到所有partition都可以放到内存中
这里有几个问题,
首先,一个partition应该不止一个key,如果只有一个,第二步里面的h2感觉没用
第二,假设数据是均匀分布的,不会出现太大的倾斜,不会有partition overflow


Join
为什么需要join?
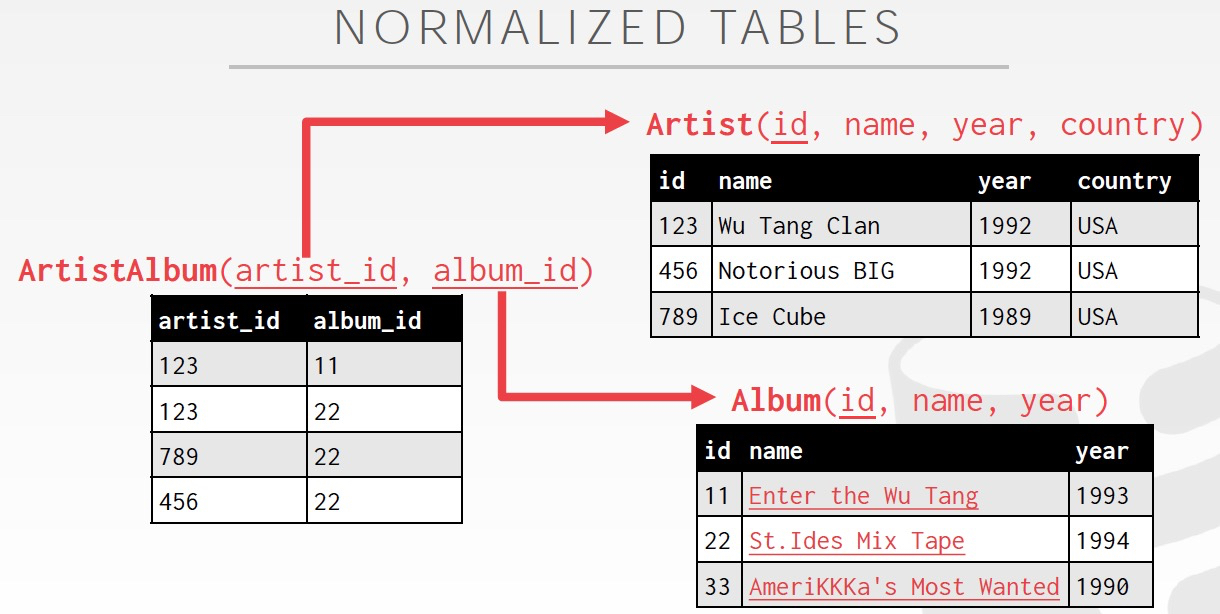
因为不同的数据存在不同的表里面,所以要查询就需要关联
那么为什么不能放在一张表里面,关系表的设计有范式的要求,避免大量的数据重复
Join Operator Output
直接输出data,这样好处是,后续operator不用回到数据表再去读数据
这个方法比较实用于TP需求,结果数据较少的情况


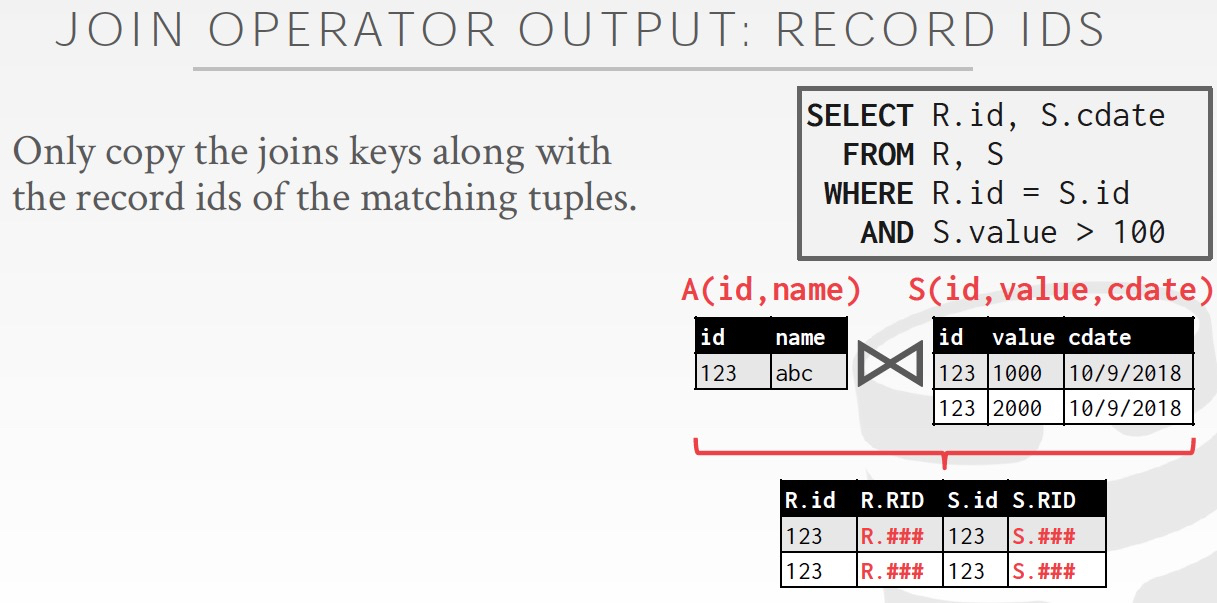
仅仅输出ids,适合AP需求,join结果集非常大的情况
尤其适用于列存,因为这样你只需要读出join id列,也不浪费
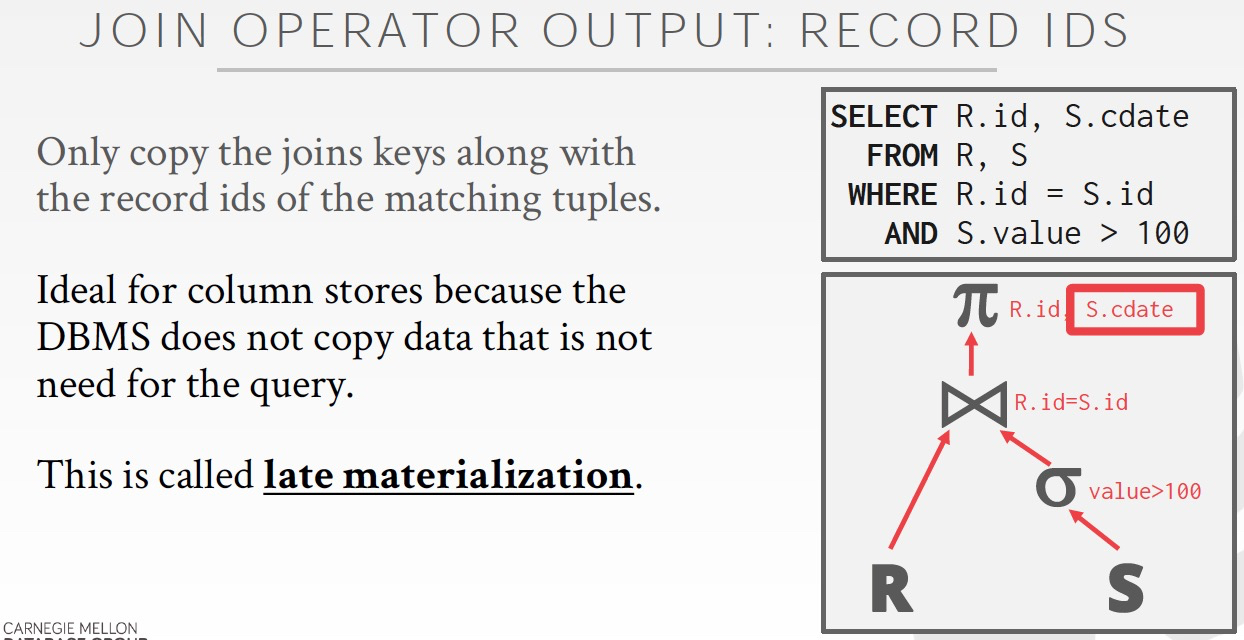
然后在最后要显示的时候,才去把需要的数据从表里面查出来,这叫做late materialization
这样的好处,过程中可能还有其他的join,过滤等,所以开始读可能浪费,到最后真正需要的时候再读
Join Cost
如何去评价join算法的好坏,就是要评价cost
传统的数据库的瓶颈在disk IO,所以这里就以磁盘IO的次数来评价join算法的好坏,这个和为何使用B+tree作为index的理由一样
所以就是读写page的个数

Join算法
Nested Loop Join
Simple,直觉的方式就是遍历两个表
这里的概念,分为Outer和Inner表
从Cost上看,最要取决于Outer的tuples数,所以如果把较小的表N作为Outer会效率高些


比较明显的问题是,没有必要读那么多遍的inner表
如果我能把outer表直接放在内存中,那么只需要读一遍inner就可以了,如果不行就用如下的block的方式
如果内存大小是B,那么要用两块来放inner和output,所以可以用B-2来放outer


Cost,outer表M需要读一次,inner表需要读M/(B-2)次
这里也写了,如果memory比较大,那么cost就是M+N,只需要读一遍inner

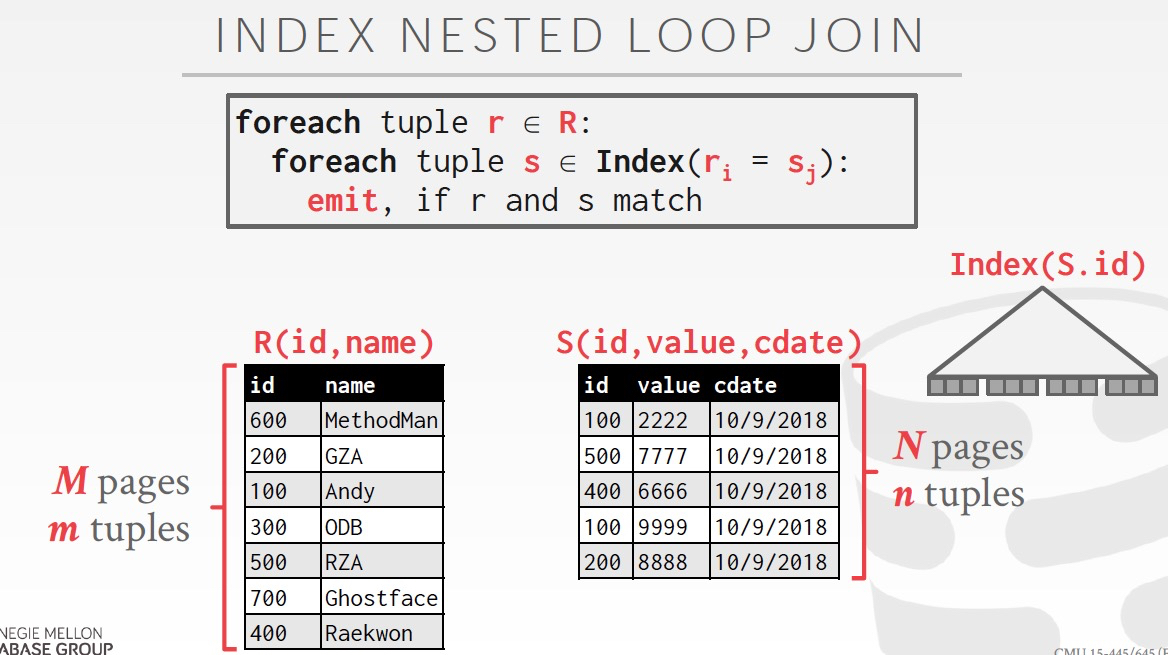
如果有index,是否可以加快join的效率?应该可以,但是效果要看是什么index,如果hash,C=O(1),B+tree,C=O(logn)

Sort-Merge Join
这个方法要求,两个表先排序,然后做一轮幷归就可以完成join
所以这个方法适用于,两个表本身就有序,或是在join key上有index
这个方法附带的好处是结果有序
这个算法的Cost,主要是两个表排序的cost,幷归的cost就是M+N


Hash Join
HashJoin分为两步,两步的hash函数用同一个
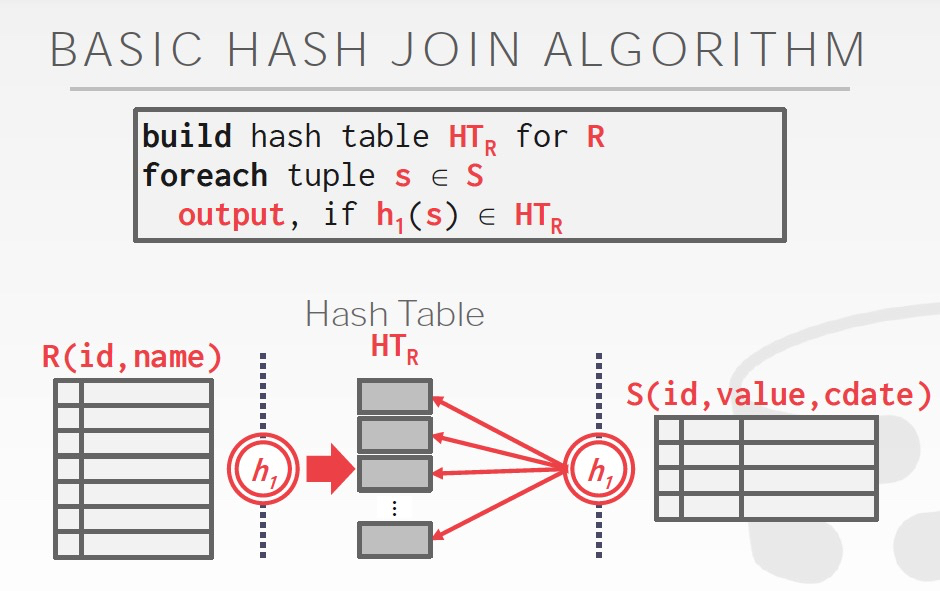
Build,对较小的表建临时的hash table
Probe,读取另一张表,进行join
这有个类似的问题,Hash Table里面存什么?
当然可以直接存join的结果,也可以存tuple id,这个选择就取决于场景
自然有个疑问,如果内存放不下这个hash table怎么办?
既然放不下,就需要分而治之,两个表用相同的hash函数,hash到相同数目的buckets里面去
在内存中,一次只读一组bucket来进行join,是不是很ok
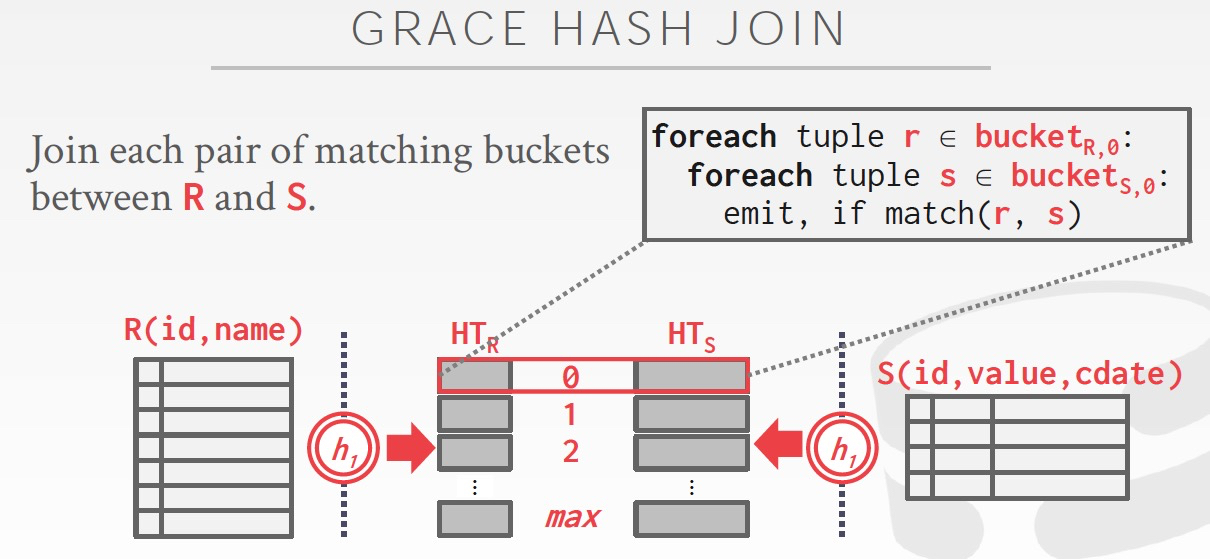
那么如果hash成bucket的时候,不均衡,一个bucket也overflow,怎么办?答案是继续分


Grace Hash Join的cost

所有join算法的Cost对比,

CMU Database Systems - Sorting,Aggregation,Join的更多相关文章
- CMU Database Systems - Storage and BufferPool
Database Storage 存储分为volatile和non-volatile,越快的越贵越小 那么所以要解决的第一个问题就是,如果尽量在有限的成本下,让读写更快些 意思就是,尽量读写volat ...
- CMU Database Systems - Distributed OLTP & OLAP
OLTP scale-up和scale-out scale-up会有上限,无法不断up,而且相对而言,up升级会比较麻烦,所以大数据,云计算需要scale-out scale-out,就是分布式数据库 ...
- CMU Database Systems - Database Recovery
数据库数据丢失的典型场景如下, 数据commit后,还没有来得及flush到disk,这时候crash就会丢失数据 当然这只是fail的一种情况,DataBase Recovery要讨论的是,在各种f ...
- CMU Database Systems - Timestamp Ordering Concurrency Control
2PL是悲观锁,Pessimistic,这章讲乐观锁,Optimistic,单机的,非分布式的 Timestamp Ordering,以时间为序,这个是非常自然的想法,按每个transaction的时 ...
- CMU Database Systems - Concurrency Control Theory
并发控制是数据库理论里面最难的课题之一 并发控制首先了解一下事务,transaction 定义如下, 其实transaction关键是,要满足ACID属性, 左边的正式的定义,由于的intuitive ...
- CMU Database Systems - Query Optimization
查询优化应该是数据库领域最难的topic 当前查询优化,主要有两种思路, Rules-based,基于先验知识,用if-else把优化逻辑写死 Cost-based,试图去评估各个查询计划的cost, ...
- CMU Database Systems - Query Processing
Query Model Query处理有三种方式, 首先是Iterator model,这是最基本的model,又称为volcano,pipeline模式 他是top-down的模式,通过next函数 ...
- CMU Database Systems - Two-phase Locking
首先锁是用来做互斥的,解决并发执行时的数据不一致问题 如图会导致,不可重复读 如果这里用lock就可以解决,数据库里面有个LockManager来作为master,负责锁的记录和授权 数据库里面的基本 ...
- CMU Database Systems - MVCC
MVCC是一种用空间来换取更高的并发度的技术 对同一个对象不去update,而且记录下每一次的不同版本的值 存在不会消失,新值并不能抹杀原先的存在 所以update操作并不是对世界的真实反映,这是一种 ...
随机推荐
- oracle 设置归档日模式
首先关闭ORACLE SQL> shutdown immediate 把ORACLE启动为MOUNT模式 SQL:>startup mount sql:> alter databas ...
- SecureCRT中文乱码解决已设置UTF-8了
参考网址:http://www.iitshare.com/securecrt-chinese-garbled-solution.html 问题描述 SecureCRT与SecureFX的常规选项里面已 ...
- ISCC之msc_无法运行的exe
打开hxd,里面老长一串base64 解码试了一下,解出来是png文件头,但是图片有错误 百度了一下,PNG文件头是89 50 4E 47 0D 0A 1A 0A 再回去看 改成0A了事, 出来一张二 ...
- CF: Long Number
题目链接 #include<iostream> #include<string> ...
- Servlet的入门
什么是Servlet? Servlet是运行在服务端的java小程序,是sun公司提供的一套规范,用来处理客户端请求.响应给浏览器的动态资源.Servlet是JavaWeb三大组件之一(Setvlet ...
- java -static的特性和使用,静态类/方法/块/内部类/回收机制
mark一下,今天的作业. java-core P115 如果将域定义为static,每个类中只有一个这样的域.(这里的域应该是指一片物理数据空间,而不是单纯的指代某一个变量,而是静态域). publ ...
- PHP——封装Curl请求方法支持POST | DELETE | GET | PUT 等
前言 Curl: https://www.php.net/manual/en/book.curl.php curl_setopt: https://www.php.net/manual/en/fun ...
- PostgreSQL 输出 JSON 结果
PostGreSQL 从 9.2 开始增加对 JSON 的支持.9.5 已经支持多个 JSON 函数,见 http://www.postgres.cn/docs/9.5/functions-json. ...
- SVN “Previous operation has not finished”
https://jingyan.baidu.com/article/cbcede0761334902f40b4d31.html 需要运行sqlite3打开.svn下的wc.db数据库文件, sqlit ...
- C语言函数的定义和使用(2)
一:无参函数 类型说明符 get(){ //函数体 } 二:无参函数 类型说明符 getname(int a,int b){ //函数体 } 三:类型说明符包括: int ,char,float,do ...