HBase安装指南
一.事前准备
- 此安装是建立在hadoop集群运行起来的基础上,此hadoop版本为2.6.0,其他版本未测试,可能存在兼容性问题。
- 上传所需文件到/usr/local/soft
二.zookeeper安装
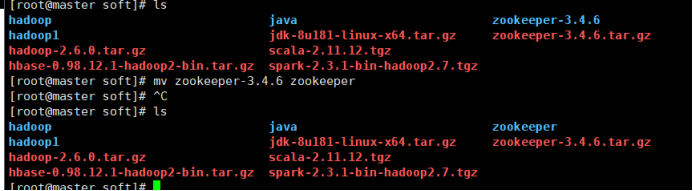
1.进入文件所在目录:cd /usr/local/soft/

2. 解压:tar -zxvf zookeeper-3.4.6.tar.gz
3. 重命名:mv zookeeper-3.4.6 zookeeper
4. 进入conf目录:cd zookeeper/conf/
5. 复制并重命名zoo_sample.cfg为zoo.cfg:cp zoo_sample.cfg zoo.cfg

6.返回上一级,并新建一个data文件夹:mkdir data

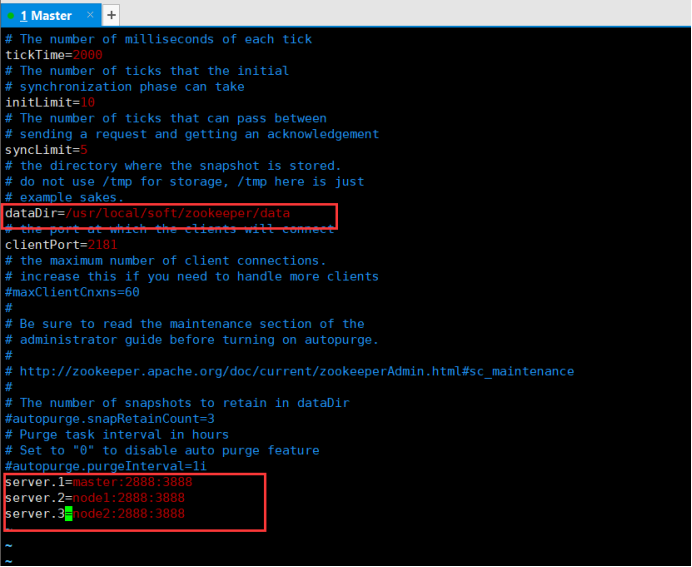
7.进入zoo.cfg文件并修改配置如下:vim conf/zoo.cfg
8. 返回软件安装目录soft,并将该配置目录同步到node1,node2
scp -r zookeeper root@node1:/usr/local/soft/
scp -r zookeeper root@node2:/usr/local/soft/

9.分别修改个三台主机的对应id:vim zookeeper/data/myid



10.启动zookeeper(三台都执行):bin/zkServer.sh start

11. 验证zookeeper(三台都执行):bin/zkServer.sh status
注意:node1为leader,master,node2为follower
以上zookeeper安装完成
三.Hbase安装
1.回到soft目录下,解压hbase:tar -zxvf hbase-0.98.12.1-hadoop2-bin.tar.gz
2.重命名hbase :mv hbase-0.98.12.1-hadoop2 hbase
3.配置profile文件并发送给其他节点:
vim /etc/profile.d/hbase.sh

# SET HBASE
export HBASE_HOME=/usr/local/soft/hbase
export PATH=$HBASE_HOME/bin:$PATH
发送节点:
scp -r /etc/profile.d/hbase.sh root@node1:/etc/profile.d/
scp -r /etc/profile.d/hbase.sh root@node2:/etc/profile.d/

4.使配置生效(三台都执行):source /etc/profile

5.修改hbase-env.sh配置文件: vim hbase/conf/hbase-env.sh


export JAVA_HOME=/usr/local/soft/java
export HBASE_MANAGES_ZK=false
6.修改hbase-site.xml配置文件:vim hbase/conf/hbase-site.xml

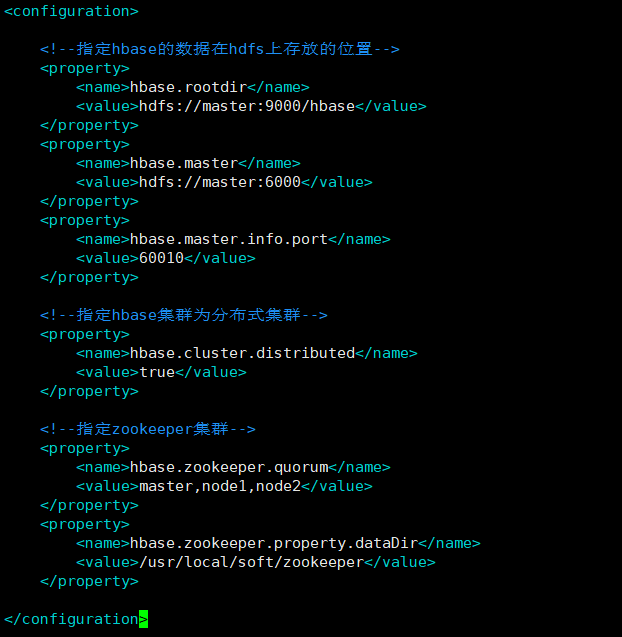
<!--指定hbase的数据在hdfs上存放的位置-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://master:6000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<!--指定hbase集群为分布式集群-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--指定zookeeper集群-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,node1,node2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/soft/zookeeper</value>
</property>
7. 设置备用:vim hbase/conf/backup-masters

8. 修改regionservers 配置文件:vim hbase/conf/regionservers

9.复制hadoop配置文件到hbase目录下:
cp hadoop/etc/hadoop/core-site.xml hbase/conf/
cp hadoop/etc/hadoop/hdfs-site.xml hbase/conf/

10.将hbase安装目录发送到其他节点:
scp -r hbase root@node1:/usr/local/soft/
scp -r hbase root@node2:/usr/local/soft/

11.启动hbase:start-hbase.sh

12.各节点jps截图:

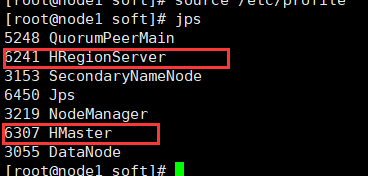

13. 验证hbase
网页验证:

简单命令验证

HBase安装指南的更多相关文章
- 菜鸟玩云计算之十一:Hadoop 手动安装指南
Hadoop 手动安装指南 cheungmine 2013-4 本文用于指导在Windows7,VMWare上安装Ubuntu, Java, Hadoop, HBase实验环境. 本指南用于实验的软件 ...
- Hadoop+HBase+Spark+Hive环境搭建
杨赟快跑 简书作者 2018-09-24 10:24 打开App 摘要:大数据门槛较高,仅仅环境的搭建可能就要耗费我们大量的精力,本文总结了作者是如何搭建大数据环境的(单机版和集群版),希望能帮助学弟 ...
- Hive 1.2.1&Spark&Sqoop安装指南
目录 目录 1 1. 前言 1 2. 约定 2 3. 服务端口 2 4. 安装MySQL 2 4.1. 安装MySQL 2 4.2. 创建Hive元数据库 4 5. 安装步骤 5 5.1. 下载Hiv ...
- HBase-1.2.1和Phoenix-4.7.0分布式安装指南
目录 目录 1 1. 前言 2 2. 概念 2 2.1. Region name 2 3. 约定 2 4. 相关端口 3 5. 下载HBase 3 6. 安装步骤 3 6.1. 修改conf/regi ...
- HBase-0.98.0和Phoenix-4.0.0分布式安装指南
目录 目录 1 1. 前言 1 2. 约定 2 3. 相关端口 2 4. 下载HBase 2 5. 安装步骤 2 5.1. 修改conf/regionservers 2 5.2. 修改conf/hba ...
- ZooKeeper-3.4.10分布式安装指南
目录 目录 1 1. 前言 1 2. 约定 1 3. 安装步骤 2 3.1. 配置/etc/hosts 2 3.2. 设置myid 2 3.3. 修改conf/zoo.cfg 2 3.4. 修改/bi ...
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- Redis/HBase/Tair比较
KV系统对比表 对比维度 Redis Redis Cluster Medis Hbase Tair 访问模式 支持Value大小 理论上不超过1GB(建议不超过1MB) 理论上可配置(默认配置1 ...
- Hbase的伪分布式安装
Hbase安装模式介绍 单机模式 1> Hbase不使用HDFS,仅使用本地文件系统 2> ZooKeeper与Hbase运行在同一个JVM中 分布式模式– 伪分布式模式1> 所有进 ...
随机推荐
- 【转】前后端分离的项目如何部署发布到Linux
前后端分离的项目如何部署发布到Linux 前期准备 1.服务器的基本配置信息2.本机远程连接服务器的工具(xshell.xftp或者mobaXterm等等,看你自己喜欢) 第一步:部署环境 1.安装j ...
- 莫烦TensorFlow_10 过拟合
import tensorflow as tf from sklearn.datasets import load_digits from sklearn.cross_validation impor ...
- Docker镜像(六)
一.镜像是什么 镜像是一种轻量级.可执行的独立软件包,用来打包软件运行环境和基于运行环境开发的软件,它包含运行某个软件所需的所有内容,包括代码.运行时.库.环境变量和配置文件. 1. UnionFS( ...
- java 深入理解jvm内存模型 jvm学习笔记
jvm内存模型 这是java堆和方法区内存模型 参考:https://www.cnblogs.com/honey01/p/9475726.html Java 中的堆也是 GC 收集垃圾的主要区域.GC ...
- 面试:Semaphore(信号量)的成长之路
2019最寒冷,面试跳槽不能等 马上就3月份了,所谓的金三银四招聘季.2019年也许是互联网最冷清的一年,很多知名的大型互联网公司都裁员过冬.当然也有一些公司还在持续招人的,比如阿里就宣称不裁员,反而 ...
- Linux中Too many open files 问题分析和解决
今天某个服务的日志中出现了大量的异常: [WARN ] 2018-06-15 16:55:20,831 --New I/O server boss #1 ([id: 0x55007b59, /0.0. ...
- python 根据文件的编码格式读取文件
因为各种文件的不同格式,导致导致文件打开失败,这时,我们可以先判断文件的编码吗格式,然后再根据文件的编码格式进行读取文件 举例:有一个data.txt文件,我们不知道它的编码格式,现在我们需要读取文件 ...
- SpringBoot第十八篇:异步任务
作者:追梦1819 原文:https://www.cnblogs.com/yanfei1819/p/11095891.html 版权声明:本文为博主原创文章,转载请附上博文链接! 引言 系统中的异 ...
- navicat for Mysql查询数据不能直接修改
navicat for Mysql查询数据不能直接修改 原来的sql语句: <pre> select id,name,title from table where id = 5;</ ...
- Centos 7.5 安装JDK
#wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com ...