62、Spark Streaming:容错机制以及事务语义
一、 容错机制
1、背景
- 要理解Spark Streaming提供的容错机制,先回忆一下Spark RDD的基础容错语义:
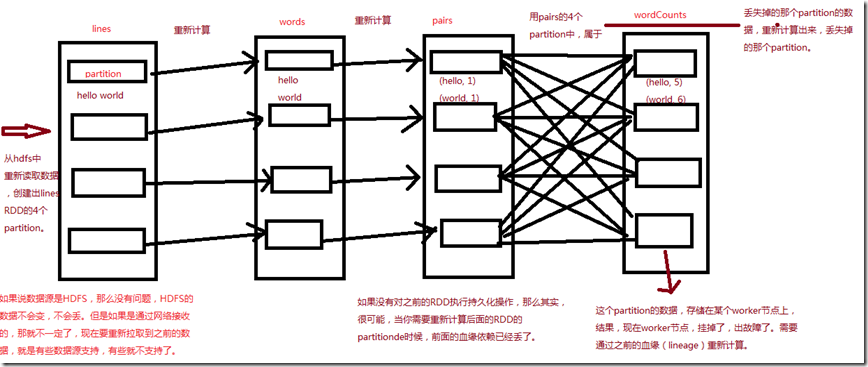
- 1、RDD,Ressilient Distributed Dataset,是不可变的、确定的、可重新计算的、分布式的数据集。每个RDD都会记住确定好的计算操作的血缘关系,
- (val lines = sc.textFile(hdfs file);
- val words = lines.flatMap();
- val pairs = words.map();
- val wordCounts = pairs.reduceByKey())这些操作应用在一个容错的数据集上来创建RDD。
- 2、如果因为某个Worker节点的失败(挂掉、进程终止、进程内部报错),导致RDD的某个partition数据丢失了,那么那个partition可以通过对原始的
- 容错数据集应用操作血缘,来重新计算出来。
- 3、所有的RDD transformation操作都是确定的,最后一个被转换出来的RDD的数据,一定是不会因为Spark集群的失败而丢失的。
- Spark操作的通常是容错文件系统中的数据,比如HDFS。因此,所有通过容错数据生成的RDD也是容错的。然而,对于Spark Streaming来说,这却行不通,
- 因为在大多数情况下,数据都是通过网络接收的(除了使用fileStream数据源)。要让Spark Streaming程序中,所有生成的RDD,都达到与普通Spark程序
- 的RDD,相同的容错性,接收到的数据必须被复制到多个Worker节点上的Executor内存中,默认的复制因子是2。
- 基于上述理论,在出现失败的事件时,有两种数据需要被恢复:
- 1、数据接收到了,并且已经复制过——这种数据在一个Worker节点挂掉时,是可以继续存活的,因为在其他Worker节点上,还有它的一份副本。
- 2、数据接收到了,但是正在缓存中,等待复制的——因为还没有复制该数据,因此恢复它的唯一办法就是重新从数据源获取一份。
- 此外,还有两种失败是我们需要考虑的:
- 1、Worker节点的失败——任何一个运行了Executor的Worker节点的挂掉,都会导致该节点上所有在内存中的数据都丢失。如果有Receiver运行在
- 该Worker节点上的Executor中,那么缓存的,待复制的数据,都会丢失。
- 2、Driver节点的失败——如果运行Spark Streaming应用程序的Driver节点失败了,那么显然SparkContext会丢失,那么该Application的所有Executor的数据都会丢失。
二、 Spark Streaming容错语义
1、定义
- 流式计算系统的容错语义,通常是以一条记录能够被处理多少次来衡量的。有三种类型的语义可以提供:
- 1、最多一次:每条记录可能会被处理一次,或者根本就不会被处理。可能有数据丢失。
- 2、至少一次:每条记录会被处理一次或多次,这种语义比最多一次要更强,因为它确保零数据丢失。但是可能会导致记录被重复处理几次。
- 3、一次且仅一次:每条记录只会被处理一次——没有数据会丢失,并且没有数据会处理多次。这是最强的一种容错语义。
2、Spark Streaming的基础容错语义
- 在Spark Streaming中,处理数据都有三个步骤:
- 1、接收数据:使用Receiver或其他方式接收数据。
- 2、计算数据:使用DStream的transformation操作对数据进行计算和处理。
- 3、推送数据:最后计算出来的数据会被推送到外部系统,比如文件系统、数据库等。
- 如果应用程序要求必须有一次且仅一次的语义,那么上述三个步骤都必须提供一次且仅一次的语义。每条数据都得保证,只能接收一次、只能计算一次、只能推送一次。
- Spark Streaming中实现这些语义的步骤如下:
- 1、接收数据:不同的数据源提供不同的语义保障。
- 2、计算数据:所有接收到的数据一定只会被计算一次,这是基于RDD的基础语义所保障的。即使有失败,只要接收到的数据还是可访问的,最后一个计算出来的数据一定是相同的。
- 3、推送数据:output操作默认能确保至少一次的语义,因为它依赖于output操作的类型,以及底层系统的语义支持(比如是否有事务支持等),但是用户可以实现它们自己的事务
- 机制来确保一次且仅一次的语义。
3、接收数据的容错语义
- 1、基于文件的数据源
- 如果所有的输入数据都在一个容错的文件系统中,比如HDFS,Spark Streaming一定可以从失败进行恢复,并且处理所有数据。这就提供了一次且仅一次的语义,
- 意味着所有的数据只会处理一次。
- 2、基于Receiver的数据源
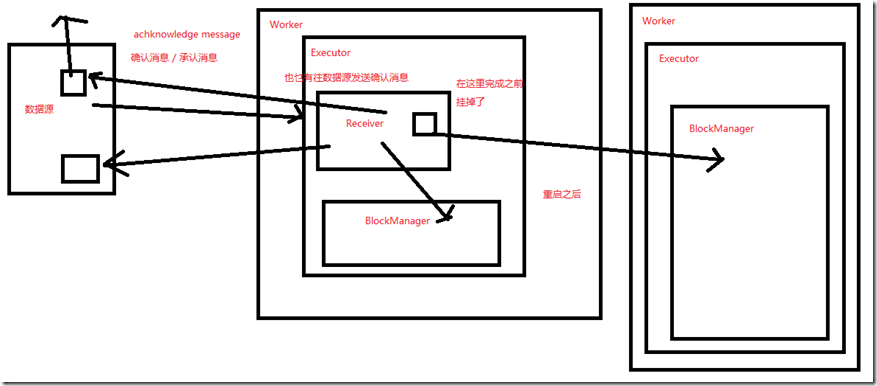
- 对于基于Receiver的数据源,容错语义依赖于失败的场景和Receiver类型。
- 可靠的Receiver:这种Receiver会在接收到了数据,并且将数据复制之后,对数据源执行确认操作。如果Receiver在数据接收和复制完成之前,就失败了,那么
- 数据源对于缓存的数据会接收不到确认,此时,当Receiver重启之后,数据源会重新发送数据,没有数据会丢失。
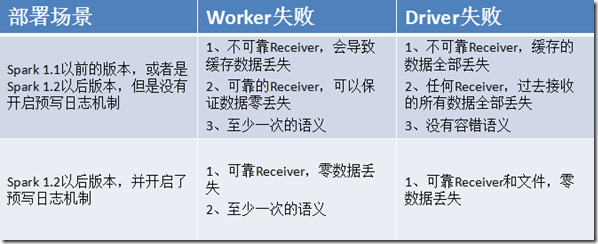
- 不可靠的Receiver:这种Receiver不会发送确认操作,因此当Worker或者Driver节点失败的时候,可能会导致数据丢失。
- 不同的Receiver,提供了不同的语义。如果Worker节点失败了,那么使用的是可靠的Receiver的话,没有数据会丢失。使用的是不可靠的Receiver的话,
- 接收到,但是还没复制的数据,可能会丢失。如果Driver节点失败的话,所有过去接收到的,和复制过缓存在内存中的数据,全部会丢失。
- 要避免这种过去接收的所有数据都丢失的问题,Spark从1.2版本开始,引入了预写日志机制,可以将Receiver接收到的数据保存到容错存储中。如果使用
- 可靠的Receiver,并且还开启了预写日志机制,那么可以保证数据零丢失。这种情况下,会提供至少一次的保障。(Kafka是可以实现可靠Receiver的)
- 从Spark 1.3版本开始,引入了新的Kafka Direct API,可以保证,所有从Kafka接收到的数据,都是一次且仅一次。基于该语义保障,
- 如果自己再实现一次且仅一次语义的output操作,那么就可以获得整个Spark Streaming应用程序的一次且仅一次的语义。
4、输出数据的容错语义
- output操作,比如foreachRDD,可以提供至少一次的语义。那意味着,当Worker节点失败时,转换后的数据可能会被写入外部系统一次或多次。对于写入文件系统来说,
- 这还是可以接收的,因为会覆盖数据。但是要真正获得一次且仅一次的语义,有两个方法:
- 1、幂等更新:多次写操作,都是写相同的数据,例如saveAs系列方法,总是写入相同的数据。
- 2、事务更新:所有的操作都应该做成事务的,从而让写入操作执行一次且仅一次。给每个batch的数据都赋予一个唯一的标识,然后更新的时候判定,如果数据库中还
- 没有该唯一标识,那么就更新,如果有唯一标识,那么就不更新。
- dstream.foreachRDD { (rdd, time) =>
- rdd.foreachPartition { partitionIterator =>
- val partitionId = TaskContext.get.partitionId()
- val uniqueId = generateUniqueId(time.milliseconds, partitionId)
- // partitionId和foreachRDD传入的时间,可以构成一个唯一的标识
- }
- }
5、Storm的容错语义
- 就输出数据这一点来看,网上有些同学,特别的挺Spark Streaming,踩Storm。问题是,他们真的对这两种实时计算技术都很精通吗?都对它们所有的高级特性掌握的非常彻底吗?
- Storm首先,它可以实现消息的高可靠性,就是说,它有一个机制,叫做Acker机制,可以保证,如果消息处理失败,那么就重新发送。保证了,至少一次的容错语义。
- 但是光靠这个,还是不行,数据可能会重复。
- Storm提供了非常非常完善的事务机制,可以实现一次且仅一次的事务机制。事务Topology、透明的事务Topology、非透明的事务Topology,可以应用各种各样的情况。
- 对实现一次且仅一次的这种语义的支持,做的非常非常好。用事务机制,可以获得它内部提供的一个唯一的id,然后基于这个id,就可以实现,output操作,输出,
- 推送数据的时候,先判断,该数据是否更新过,如果没有的话,就更新;如果更新过,就不要重复更新了。
- 所以,至少,在容错 / 事务机制方面,我觉得Spark Streaming还有很大的空间可以发展。特别是对于output操作的一次且仅一次的语义支持!
62、Spark Streaming:容错机制以及事务语义的更多相关文章
- 2.Spark Streaming运行机制和架构
1 解密Spark Streaming运行机制 上节课我们谈到了技术界的寻龙点穴.这就像过去的风水一样,每个领域都有自己的龙脉,Spark就是龙脉之所在,它的龙穴或者关键点就是SparkStreami ...
- Spark Streaming概念学习系列之Spark Streaming容错
Spark Streaming容错 检查点机制-checkpoint 什么是检查点机制? Spark Streaming 周期性地把应用数据存储到诸如HDFS 或Amazon S3 这样的可靠存储系统 ...
- Spark Streaming容错的改进和零数据丢失
本文来自Spark Streaming项目带头人 Tathagata Das的博客文章,他现在就职于Databricks公司.过去曾在UC Berkeley的AMPLab实验室进行大数据和Spark ...
- 通过案例对 spark streaming 透彻理解三板斧之三:spark streaming运行机制与架构
本期内容: 1. Spark Streaming Job架构与运行机制 2. Spark Streaming 容错架构与运行机制 事实上时间是不存在的,是由人的感官系统感觉时间的存在而已,是一种虚幻的 ...
- 通过案例对 spark streaming 透彻理解三板斧之二:spark streaming运行机制
本期内容: 1. Spark Streaming架构 2. Spark Streaming运行机制 Spark大数据分析框架的核心部件: spark Core.spark Streaming流计算. ...
- 大数据技术之_19_Spark学习_04_Spark Streaming 应用解析 + Spark Streaming 概述、运行、解析 + DStream 的输入、转换、输出 + 优化
第1章 Spark Streaming 概述1.1 什么是 Spark Streaming1.2 为什么要学习 Spark Streaming1.3 Spark 与 Storm 的对比第2章 运行 S ...
- Dream_Spark-----Spark 定制版:004~Spark Streaming事务处理彻底掌握
Spark 定制版:004~Spark Streaming事务处理彻底掌握 本讲内容: a. Exactly Once b. 输出不重复 注:本讲内容基于Spark 1.6.1版本(在2016年5月来 ...
- 4.Spark Streaming事务处理
首先,我们必须知道什么是事务及其一致性? 事务应该具有4个属性:原子性.一致性.隔离性.持久性.这四个属性通常称为ACID特性. 原子性(atomicity).一个事务是一个不可分割的工作单位,事务中 ...
- 4. Spark Streaming解析
4.1 初始化StreamingContext import org.apache.spark._ import org.apache.spark.streaming._ val conf = new ...
随机推荐
- Spring-Cloud之Spring-Boot框架-1
一.Spring Boot 是由 Pivotal 团队开发的 Spring 框架,采用了生产就绪的观点 ,旨在简化配置,致力于快速开发. Spring Boot 框架提供了自动装配和起步依赖,使开发人 ...
- C#录制声卡声音喇叭声音音箱声音
在项目中,我们会需要录制电脑播放的声音,比如歌曲,电影声音,聊天声音等通过声卡音箱发出的声音.那么如何采集呢?当然是采用SharpCapture!下面开始演示关键代码,您也可以在文末下载全部源码: 设 ...
- Nginx fastcgi_cache权威指南
一.简介 Nginx版本从0.7.48开始,支持了类似Squid的缓存功能.这个缓存是把URL及相关组合当做Key,用Md5算法对Key进行哈希,得到硬盘上对应的哈希目录路径,从而将缓存内容保存在该目 ...
- 数组中[::-1]或[::-n]的区别,如三维数组[:,::-1,:]
import numpy as npa=np.array([[11,12,13,14,15,16,17,18],[21,22,23,24,25,26,27,28],[31,32,33,34,35,36 ...
- 自学Python编程的第十一天----------来自苦逼的转行人
2019-09-21-23:00:26 今天看了很多博客网的博客,看完觉得自己的博客真的是垃圾中的垃圾 新手不知道怎样写博客,我也很想写好一篇能让人看的博客,但是目前水平不够 只能慢慢改,今天的博客还 ...
- pathlib的使用
目录 一. Python2与Python3的路径处理的对比 二. pathlib的几个使用示例 1. 最简单的使用 2. 追加路径到Python的sys.path中 3. 生成目录树的技巧 4. 递归 ...
- vue从零开始(二)指令
一.v-text和v-html <span v-text="msg"></span> <div v-html="html"> ...
- Vue父子,子父,非父子组件之间传值
Vue组件基础 纯属随笔记录,具体详细教程,请查阅vue.js网站 子组件给父组件传值: <body> <div id="app"> <my-app& ...
- CSS-盒模型与文本溢出笔记
注意点: 文本居中: text-align:center:文本左右居中 line-heigh:30px; 等于容器高度时,单行文本上下居中 margin:0 auto: 浏览器居中 清除margin ...
- Flask入门到放弃(四)—— 数据库
转载请在文章开头附上原文链接地址:https://www.cnblogs.com/Sunzz/p/10979970.html 数据库操作 ORM ORM 全拼Object-Relation Mappi ...