Python进阶:并发编程之Futures
区分并发和并行
并发(Concurrency).
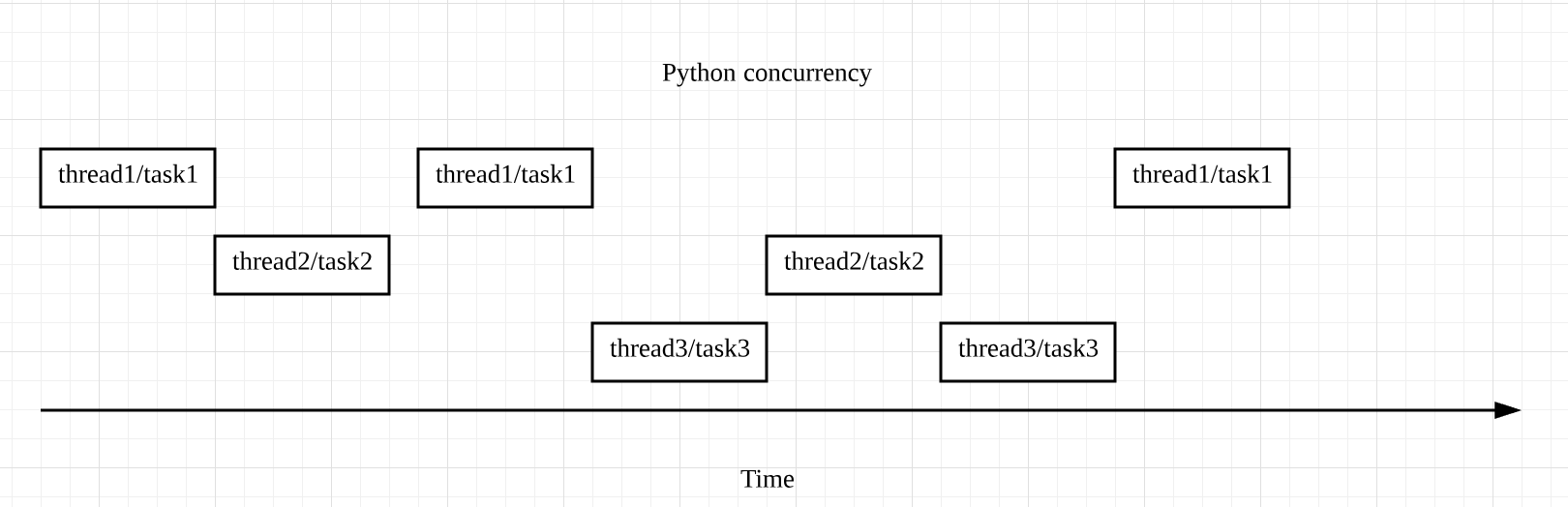
并行(Parallelism)

并发编程之 Futures
单线程与多线程性能比较
import requests
import time def download_one(url):
resp = requests.get(url)
print('Read {} from {}'.format(len(resp.content), url)) def download_all(sites):
for site in sites:
download_one(site) def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
download_all(sites)
end_time = time.perf_counter()
print('Download {} sites in {} seconds'.format(len(sites), end_time - start_time)) if __name__ == '__main__':
main() # 输出
Read 129196 from https://en.wikipedia.org/wiki/Portal:Arts
Read 183867 from https://en.wikipedia.org/wiki/Portal:History
Read 224161 from https://en.wikipedia.org/wiki/Portal:Society
Read 114387 from https://en.wikipedia.org/wiki/Portal:Biography
Read 152871 from https://en.wikipedia.org/wiki/Portal:Mathematics
Read 156339 from https://en.wikipedia.org/wiki/Portal:Technology
Read 162872 from https://en.wikipedia.org/wiki/Portal:Geography
Read 91504 from https://en.wikipedia.org/wiki/Portal:Science
Read 323262 from https://en.wikipedia.org/wiki/Computer_science
Read 391073 from https://en.wikipedia.org/wiki/Python_(programming_language)
Read 319710 from https://en.wikipedia.org/wiki/Java_(programming_language)
Read 470754 from https://en.wikipedia.org/wiki/PHP
Read 180774 from https://en.wikipedia.org/wiki/Node.js
Read 56799 from https://en.wikipedia.org/wiki/The_C_Programming_Language
Read 325451 from https://en.wikipedia.org/wiki/Go_(programming_language)
Download 15 sites in 67.349395015 seconds
import concurrent.futures
import requests
import threading
import time def download_one(url):
try:
resp = requests.get(url)
print('Read {} from {}'.format(len(resp.content), url))
except Exception as ex:
print(ex) def download_all(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
results = executor.map(download_one, sites)
# with concurrent.futures.ProcessPoolExecutor() as executor:
# results = executor.map(download_one,sites) def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
download_all(sites)
end_time = time.perf_counter()
print('Download {} sites in {} seconds'.format(len(sites), end_time - start_time)) if __name__ == '__main__':
main() # 输出
Read 114387 from https://en.wikipedia.org/wiki/Portal:Biography
Read 129196 from https://en.wikipedia.org/wiki/Portal:Arts
Read 183867 from https://en.wikipedia.org/wiki/Portal:History
Read 152871 from https://en.wikipedia.org/wiki/Portal:Mathematics
Read 224161 from https://en.wikipedia.org/wiki/Portal:Society
Read 156339 from https://en.wikipedia.org/wiki/Portal:Technology
Read 91504 from https://en.wikipedia.org/wiki/Portal:Science
Read 391073 from https://en.wikipedia.org/wiki/Python_(programming_language)
Read 162872 from https://en.wikipedia.org/wiki/Portal:Geography
Read 323262 from https://en.wikipedia.org/wiki/Computer_science
Read 56799 from https://en.wikipedia.org/wiki/The_C_Programming_Language
Read 319710 from https://en.wikipedia.org/wiki/Java_(programming_language)
Read 325451 from https://en.wikipedia.org/wiki/Go_(programming_language)
Read 180774 from https://en.wikipedia.org/wiki/Node.js
Read 470754 from https://en.wikipedia.org/wiki/PHP
Download 15 sites in 10.022916933 seconds
with futures.ThreadPoolExecutor(workers) as executor
=>
with futures.ProcessPoolExecutor() as executor:
对于这种IO场景,用并行的方式并不会比并发的方式效率高.
到底什么是 Futures ?
import concurrent.futures
import requests
import time def download_one(url):
resp = requests.get(url)
print('Read {} from {}'.format(len(resp.content), url))
return f'download {len(resp.content)} ok' # def over(arg):
# print(arg)
# print('over') def download_all(sites):
#future列表中每个future完成的顺序,和它在列表中的顺序并不一定完全一致。
#到底哪个先完成、哪个后完成,取决于系统的调度和每个future的执行时间
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
to_do = []
for site in sites:
#executor.submit返回future实例
future = executor.submit(download_one, site)
to_do.append(future)
#future.add_done_callback(over) #在futures完成后打印结果
for future in concurrent.futures.as_completed(to_do):
if future.exception() is not None:
print(future.exception())
else:
print(future.result()) def main():
sites = [
'https://en.wikipedia.org/wiki/Portal:Arts',
'https://en.wikipedia.org/wiki/Portal:History',
'https://en.wikipedia.org/wiki/Portal:Society',
'https://en.wikipedia.org/wiki/Portal:Biography',
'https://en.wikipedia.org/wiki/Portal:Mathematics',
'https://en.wikipedia.org/wiki/Portal:Technology',
'https://en.wikipedia.org/wiki/Portal:Geography',
'https://en.wikipedia.org/wiki/Portal:Science',
'https://en.wikipedia.org/wiki/Computer_science',
'https://en.wikipedia.org/wiki/Python_(programming_language)',
'https://en.wikipedia.org/wiki/Java_(programming_language)',
'https://en.wikipedia.org/wiki/PHP',
'https://en.wikipedia.org/wiki/Node.js',
'https://en.wikipedia.org/wiki/The_C_Programming_Language',
'https://en.wikipedia.org/wiki/Go_(programming_language)'
]
start_time = time.perf_counter()
download_all(sites)
end_time = time.perf_counter()
print('Download {} sites in {} seconds'.format(len(sites), end_time - start_time)) if __name__ == '__main__':
main() # 输出
Read 129886 from https://en.wikipedia.org/wiki/Portal:Arts
Read 107634 from https://en.wikipedia.org/wiki/Portal:Biography
Read 224118 from https://en.wikipedia.org/wiki/Portal:Society
Read 158984 from https://en.wikipedia.org/wiki/Portal:Mathematics
Read 184343 from https://en.wikipedia.org/wiki/Portal:History
Read 157949 from https://en.wikipedia.org/wiki/Portal:Technology
Read 167923 from https://en.wikipedia.org/wiki/Portal:Geography
Read 94228 from https://en.wikipedia.org/wiki/Portal:Science
Read 391905 from https://en.wikipedia.org/wiki/Python_(programming_language)
Read 321352 from https://en.wikipedia.org/wiki/Computer_science
Read 180298 from https://en.wikipedia.org/wiki/Node.js
Read 321417 from https://en.wikipedia.org/wiki/Java_(programming_language)
Read 468421 from https://en.wikipedia.org/wiki/PHP
Read 56765 from https://en.wikipedia.org/wiki/The_C_Programming_Language
Read 324039 from https://en.wikipedia.org/wiki/Go_(programming_language)
Download 15 sites in 0.21698231499976828 seconds
future列表中每个future完成的顺序,和它在列表中的顺序并不一定完全一致。到底哪个先完成、哪个后完成,取决于系统的调度和每个future的执行时间。
并发通常用于 I/O 操作频繁的场景,而并行则适用于 CPU heavy 的场景。
参考
极客时间《Python核心技术与实战》专栏
Python进阶:并发编程之Futures的更多相关文章
- Python进阶:并发编程之Asyncio
什么是Asyncio 多线程有诸多优点且应用广泛,但也存在一定的局限性: 比如,多线程运行过程容易被打断,因此有可能出现 race condition 的情况:再如,线程切换本身存在一定的损耗,线程数 ...
- Python核心技术与实战——十七|Python并发编程之Futures
不论是哪一种语言,并发编程都是一项非常重要的技巧.比如我们上一章用的爬虫,就被广泛用在工业的各个领域.我们每天在各个网站.App上获取的新闻信息,很大一部分都是通过并发编程版本的爬虫获得的. 正确并合 ...
- python基础-并发编程之I/O模型基础
1. I/O模型介绍 1.1 I/O模型基础 更好的理解I/O模型,需要先回顾:同步.异步.阻塞.非阻塞 同步:执行完代码后,原地等待,直至出现结果 异步:执行完代码后,不等待,继续执行其他事务(常与 ...
- Python 之并发编程之manager与进程池pool
一.manager 常用的数据类型:dict list 能够实现进程之间的数据共享 进程之间如果同时修改一个数据,会导致数据冲突,因为并发的特征,导致数据更新不同步. def work(dic, lo ...
- python并发编程之Queue线程、进程、协程通信(五)
单线程.多线程之间.进程之间.协程之间很多时候需要协同完成工作,这个时候它们需要进行通讯.或者说为了解耦,普遍采用Queue,生产消费模式. 系列文章 python并发编程之threading线程(一 ...
- python并发编程之gevent协程(四)
协程的含义就不再提,在py2和py3的早期版本中,python协程的主流实现方法是使用gevent模块.由于协程对于操作系统是无感知的,所以其切换需要程序员自己去完成. 系列文章 python并发编程 ...
- python并发编程之asyncio协程(三)
协程实现了在单线程下的并发,每个协程共享线程的几乎所有的资源,除了协程自己私有的上下文栈:协程的切换属于程序级别的切换,对于操作系统来说是无感知的,因此切换速度更快.开销更小.效率更高,在有多IO操作 ...
- python并发编程之multiprocessing进程(二)
python的multiprocessing模块是用来创建多进程的,下面对multiprocessing总结一下使用记录. 系列文章 python并发编程之threading线程(一) python并 ...
- python并发编程之threading线程(一)
进程是系统进行资源分配最小单元,线程是进程的一个实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位.进程在执行过程中拥有独立的内存单元,而多个线程共享内存等资源. 系列文章 py ...
随机推荐
- 关于解决'\u'开头的字符串转中文的方法
如果字符串是”\u70ed\u95e8\u94ed\u6587\u63a8\u8350”这种形式的字符串: python3的解决办法:字符串.encode(‘utf-8’).decode(‘unico ...
- longitudinal models | 纵向研究 | mixed model
A longitudinal study refers to an investigation where participant outcomes and possibly treatments o ...
- VUE导入Excel
import FilenameOption from './components/FilenameOption' import AutoWidthOption from './components/A ...
- 海思uboot启动流程详细分析(转)
海思uboot启动流程详细分析(一) 海思uboot启动流程详细分析(二) 海思uboot启动流程详细分析(三)
- Typora 精美而强大的Markdown编辑器
Typora 精美而强大的Markdown编辑器 转 https://www.jianshu.com/p/45e284645d30 Markdown编辑器千千万,可是有颜值.功能强并且免费的,就没有 ...
- centos和windows添加路由命令记录
# 默认路由做香港出口route add default gw 192.168.10.33route add default gw 192.168.10.1 # 删除默认路由# route del d ...
- spark sql插入表时的文件个数研究
spark sql执行insert overwrite table时,写到新表或者新分区的文件个数,有可能是200个,也有可能是任意个,为什么会有这种差别? 首先看一下spark sql执行inser ...
- 重装Mac系统
首先介绍重装macos的一些重要事项: 重装系统之前需要弄清楚本机上安装的系统版本. 重装系统是需要管理员账户的. 获取系统镜像有多种方式,其中最常见的方式是从appstore中获取,但要注意的是要确 ...
- 获取IFC构件的位置数据、方向数据
获取IFC构件的位置数据.方向数据 std::map<int, shared_ptr<BuildingEntity>> map_buildingEntity = b_model ...
- Python基于socket模块实现UDP通信功能示例
Python基于socket模块实现UDP通信功能示例 本文实例讲述了Python基于socket模块实现UDP通信功能.分享给大家供大家参考,具体如下: 一 代码 1.接收端 import ...