Flink状态管理和容错机制介绍
本文主要内容如下:
- 有状态的流数据处理;
- Flink中的状态接口;
- 状态管理和容错机制实现;
- 阿里相关工作介绍;
一.有状态的流数据处理#
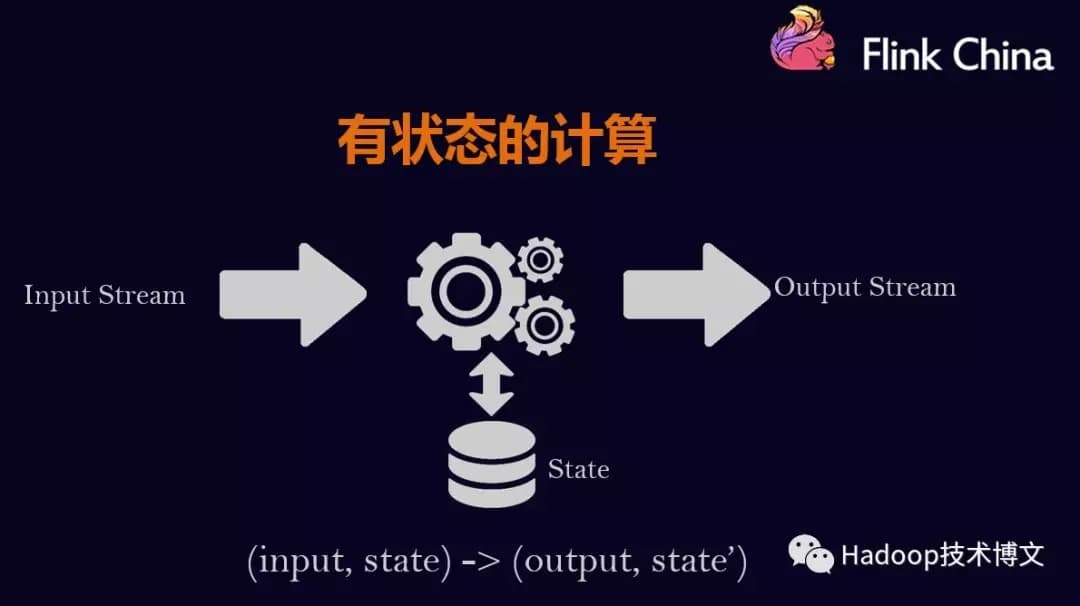
1.1.什么是有状态的计算#
计算任务的结果不仅仅依赖于输入,还依赖于它的当前状态,其实大多数的计算都是有状态的计算。 比如wordcount,给一些word,其计算它的count,这是一个很常见的业务场景。count做为输出,在计算的过程中要不断的把输入累加到count上去,那么count就是一个state。
1.2.传统的流计算系统缺少对于程序状态的有效支持#
状态数据的存储和访问;
状态数据的备份和恢复;
状态数据的划分和动态扩容;
在传统的批处理中,数据是划分为块分片去完成的,然后每一个Task去处理一个分片。当分片执行完成后,把输出聚合起来就是最终的结果。在这个过程当中,对于state的需求还是比较小的。
对于流计算而言,对State有非常高的要求,因为在流系统中输入是一个无限制的流,会运行很长一段时间,甚至运行几天或者几个月都不会停机。在这个过程当中,就需要将状态数据很好的管理起来。很不幸的是,在传统的流计算系统中,对状态管理支持并不是很完善。比如storm,没有任何程序状态的支持,一种可选的方案是storm+hbase这样的方式去实现,把这状态数据存放在Hbase中,计算的时候再次从Hbase读取状态数据,做更新在写入进去。这样就会有如下几个问题
流计算系统的任务和Hbase的数据存储有可能不在同一台机器上,导致性能会很差。这样经常会做远端的访问,走网络和存储;
备份和恢复是比较困难,因为Hbase是没有回滚的,要做到Exactly onces很困难。在分布式环境下,如果程序出现故障,只能重启Storm,那么Hbase的数据也就无法回滚到之前的状态。比如广告计费的这种场景,Storm+Hbase是是行不通的,出现的问题是钱可能就会多算,解决以上的办法是Storm+mysql,通过mysql的回滚解决一致性的问题。但是架构会变得非常复杂。性能也会很差,要commit确保数据的一致性。
对于storm而言状态数据的划分和动态扩容也是非常难做,一个很严重的问题是所有用户都会在strom上重复的做这些工作,比如搜索,广告都要在做一遍,由此限制了部门的业务发展。
1.3.Flink丰富的状态访问和高效的容错机制#
Flink在最早设计的时候就意识到了这个问题,并提供了丰富的状态访问和容错机制。如下图所示:

二.Flink中的状态管理#
2.1.按照数据的划分和扩张方式,Flink中大致分为2类:#
- Keyed States
- Operator States

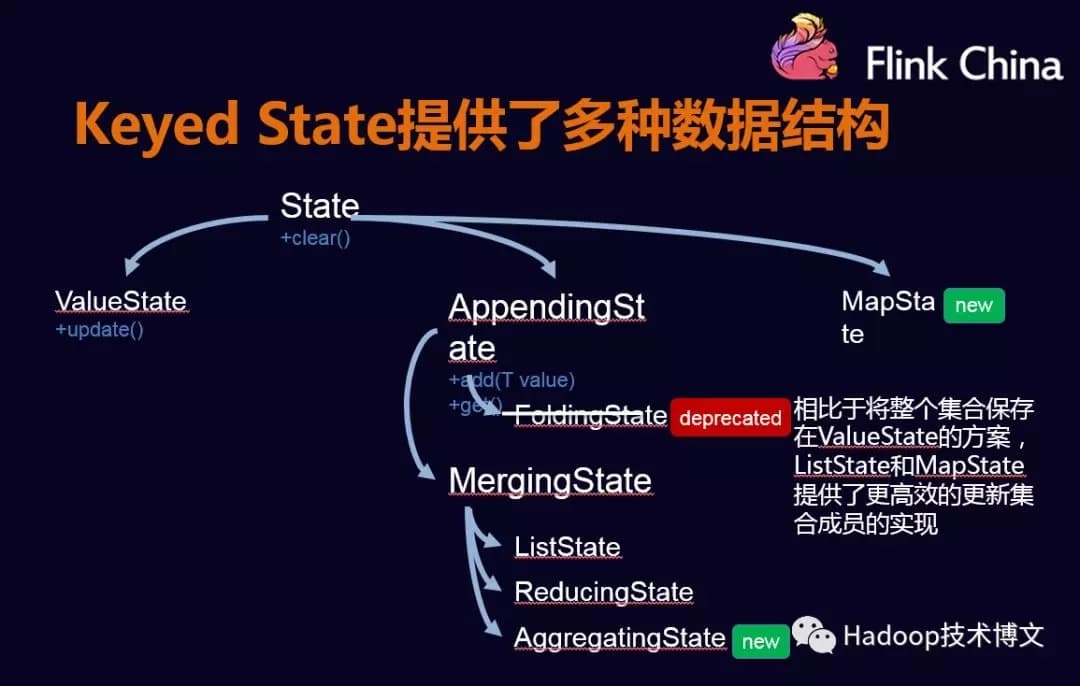
2.1.1.Keyed States#
Keyed States的使用

Flink也提供了Keyed States多种数据结构类型
Keyed States的动态扩容

2.1.2.Operator State#
Operator States的使用
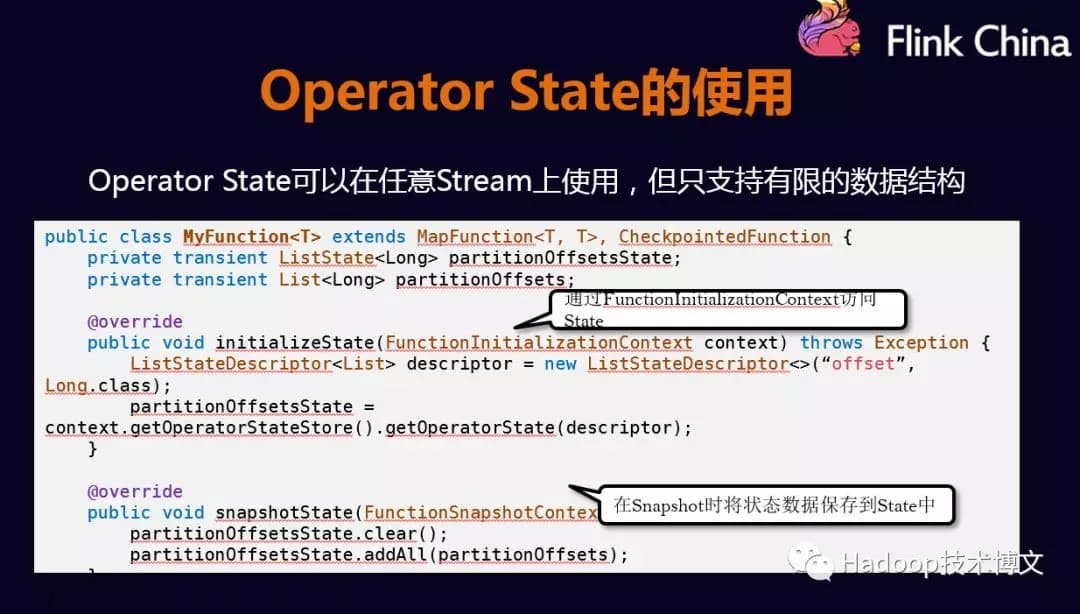
Operator States的数据结构不像Keyed States丰富,现在只支持List
Operator States多种扩展方式

Operator States的动态扩展是非常灵活的,现提供了3种扩展,下面分别介绍:
ListState:并发度在改变的时候,会将并发上的每个List都取出,然后把这些List合并到一个新的List,然后根据元素的个数在均匀分配给新的Task;
UnionListState:相比于ListState更加灵活,把划分的方式交给用户去做,当改变并发的时候,会将原来的List拼接起来。然后不做划分,直接交给用户;
BroadcastState:如大表和小表做Join时,小表可以直接广播给大表的分区,在每个并发上的数据都是完全一致的。做的更新也相同,当改变并发的时候,把这些数据COPY到新的Task即可
以上是Flink Operator States提供的3种扩展方式,用户可以根据自己的需求做选择。
使用Checkpoint提高程序的可靠性
用户可以根据的程序里面的配置将checkpoint打开,给定一个时间间隔后,框架会按照时间间隔给程序的状态进行备份。当发生故障时,Flink会将所有Task的状态一起恢复到Checkpoint的状态。从哪个位置开始重新执行。
Flink也提供了多种正确性的保障,包括:
AT LEAST ONCE;
Exactly once;

备份为保存在State中的程序状态数据
Flink也提供了一套机制,允许把这些状态放到内存当中。做Checkpoint的时候,由Flink去完成恢复。

从已停止作业的运行状态中恢复
当组件升级的时候,需要停止当前作业。这个时候需要从之前停止的作业当中恢复,Flink提供了2种机制恢复作业:
Savepoint:是一种特殊的checkpoint,只不过不像checkpoint定期的从系统中去触发的,它是用户通过命令触发,存储格式和checkpoint也是不相同的,会将数据按照一个标准的格式存储,不管配置什么样,Flink都会从这个checkpoint恢复,是用来做版本升级一个非常好的工具;
External Checkpoint:对已有checkpoint的一种扩展,就是说做完一次内部的一次Checkpoint后,还会在用户给定的一个目录中,多存储一份checkpoint的数据;

三.状态管理和容错机制实现#
下面介绍一下状态管理和容错机制实现方式,Flink提供了3种不同的StateBackend
MemoryStateBackend
FsStateBackend
RockDBStateBackend

用户可以根据自己的需求选择,如果数据量较小,可以存放到MemoryStateBackend和FsStateBackend中,如果数据量较大,可以放到RockDB中。
下面介绍HeapKeyedStateBackend和RockDBKeyedStateBackend
第一,HeapKeyedStateBackend#

第二,RockDBKeyedStateBackend#

Checkpoint的执行流程#
Checkpoint的执行流程是按照Chandy-Lamport算法实现的。
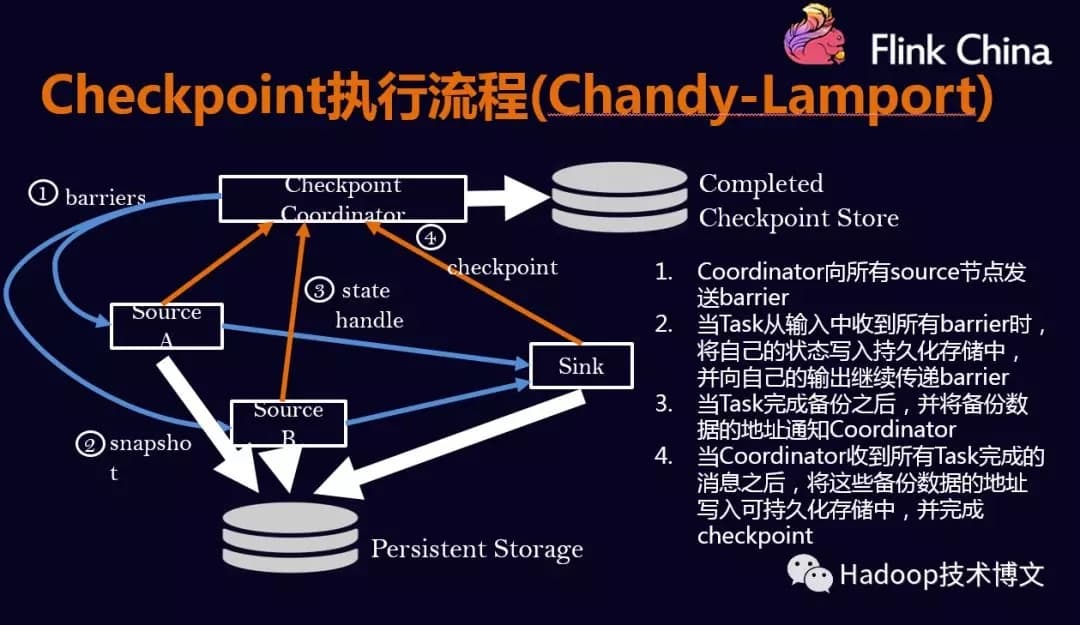
Checkpoint Barrier的对齐#

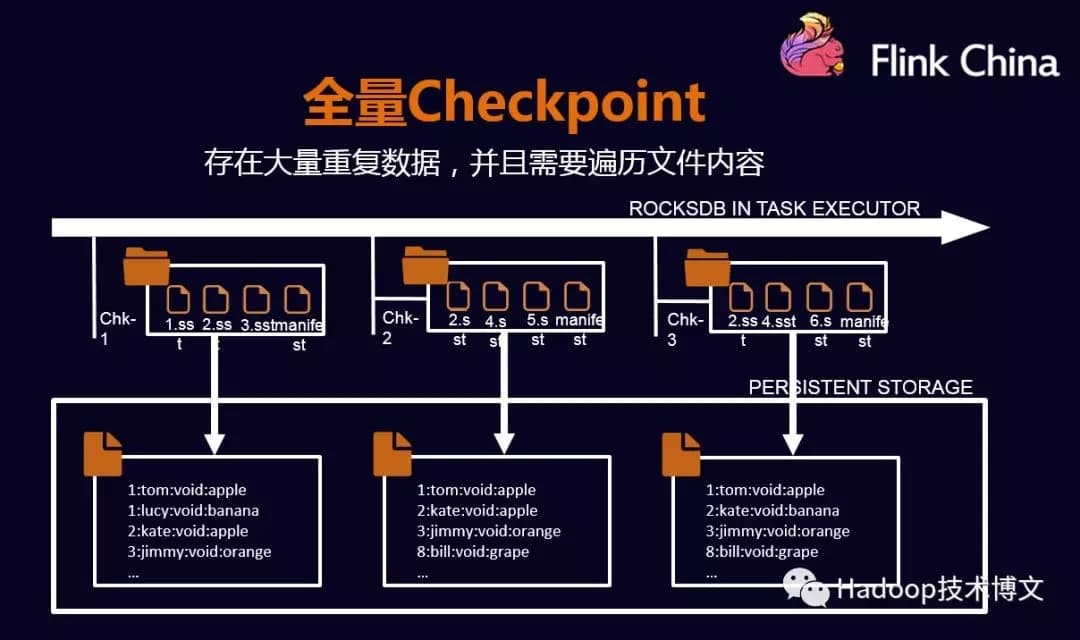
全量Checkpoint#
全量Checkpoint会在每个节点做备份数据时,只需要将数据都便利一遍,然后写到外部存储中,这种情况会影响备份性能。在此基础上做了优化。
RockDB的增量Checkpoint#
RockDB的数据会更新到内存,当内存满时,会写入到磁盘中。增量的机制会将新产生的文件COPY持久化中,而之前产生的文件就不需要COPY到持久化中去了。通过这种方式减少COPY的数据量,并提高性能。

Flink状态管理和容错机制介绍的更多相关文章
- 总结Flink状态管理和容错机制
本文来自8月11日在北京举行的 Flink Meetup会议,分享来自于施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发. 本文主要内容如 ...
- 大数据计算引擎之Flink Flink状态管理和容错
这里将介绍Flink对有状态计算的支持,其中包括状态计算和无状态计算的区别,以及在Flink中支持的不同状态类型,分别有 Keyed State 和 Operator State .另外针对状态数据的 ...
- 「Flink」Flink的状态管理与容错
在Flink中的每个函数和运算符都是有状态的.在处理过程中可以用状态来存储数据,这样可以利用状态来构建复杂操作.为了让状态容错,Flink需要设置checkpoint状态.Flink程序是通过chec ...
- Flink状态管理与状态一致性(长文)
目录 一.前言 二.状态类型 2.1.Keyed State 2.2.Operator State 三.状态横向扩展 四.检查点机制 4.1.开启检查点 (checkpoint) 4.2.保存点机制 ...
- Flink的状态管理与恢复机制
参考地址:https://www.cnblogs.com/airnew/p/9544683.html 问题一.什么是状态? 问题二.Flink状态类型有哪几种? 问题三.状态有什么作用? 问题四.如何 ...
- Flink的状态编程和容错机制(四)
一.状态编程 Flink 内置的很多算子,数据源 source,数据存储 sink 都是有状态的,流中的数据都是 buffer records,会保存一定的元素或者元数据.例如 : ProcessWi ...
- Salt状态管理
Salt状态管理 前言 上一篇文章概括性的介绍了Salt的用途和它的基本组成和实现原理,也深入的的介绍了Salt的命令编排和批量执行,但是对于状态管理只是简单的介绍了一下,因为状态管理是一个比较重 ...
- Flutter 对状态管理的认知与思考
前言 由 编程技术交流圣地[-Flutter群-] 发起的 状态管理研究小组,将就 状态管理 相关话题进行为期 两个月 的讨论. 目前只有内定的 5 个人参与讨论,如果你对 状态管理 有什么独特的见解 ...
- 关于 Flink 状态与容错机制
Flink 作为新一代基于事件流的.真正意义上的流批一体的大数据处理引擎,正在逐渐得到广大开发者们的青睐.就从我自身的视角看,最近也是在数据团队把一些原本由 Flume.SparkStreaming. ...
随机推荐
- 7、CentOS6 编译安装
LAMP组合的编译安装: httpd*php modules:把php编译成httpd的DSO对象 prefork:libphp5 event,worker : libphp5-zts cgi fpm ...
- [代码审计]php弱类型总结
0x01 前言 php是世界上最好的语言,所以php自身的安全问题也是web安全的一个方面.由于其自身弱类型语言的特性以及内置函数对于传入参数的松散处理,所以会带来很多的问题,这里将进行简要介绍. 弱 ...
- 开放-封闭原则(OCP)
怎样的升级才能面对需求的改变却可以保持相对稳定,从而使得系统可以在第一个版本以后不断推出新的版本呢?开放-封闭原则(The Open-Closed Principle, OCP)为我们提供了指引.软件 ...
- SignalR的几种方式_转自:https://www.cnblogs.com/zuowj/p/5674615.html
SignalR有三种传输模式: LongLooping(长轮询). WebSocket(HTML5的WEB套接字). Forever Frame(隐藏框架的长请求连接), 可以在WEB客户端显式指定一 ...
- [教程] Packt - Create a Game Environment with Blender and Unity by Darrin Lile
学习了解如何使用Blender,photoshop和Unity创建自己的游戏环境!了解如何通过比以往更加集成的方式使用Blender和Unity,将自己的游戏设计变为现实.在Unity中创建测试版本 ...
- JS Array.apply会有内存泄漏问题
报错内容: Maximum call stack size exceeded 参考:https://www.jianshu.com/p/b9ba0ddd3392 对象较多,前端JS内存溢出: 数组克隆 ...
- git clone时报错“Failed to connect to 127.0.0.1 port 2453: Connection refused”如何处理?
1. 查看git的配置 git config --global --list| grep -i proxy 如果有内容输出,那么unset配置项,如: git config --global --un ...
- openresty开发系列19--lua的table操作
openresty开发系列19--lua的table操作 Lua中table内部实际采用哈希表和数组分别保存键值对.普通值:下标从1开始 不推荐混合使用这两种赋值方式. local color={fi ...
- 003-结构型-05-桥接模式(Bridge)
一.概述 将抽象部分与它的具体实现部分分离.使它们都可以独立地变化.通过组合的方式建立两个类之间联系,而不是继承. Bridge 模式又叫做桥接模式,是构造型的设计模式之一.Bridge模式基于类的最 ...
- error C1002: 在第 2 遍中编译器的堆空间不足
error C1002: 在第 2 遍中编译器的堆空间不足 fatal error C1083: Not enough space 打开VS2015 x64 x86 兼容工具命令提示符,在此命令行中再 ...