spark-2.1.1 yarn(高可用)搭建
一、概述
spark分布式搭建方式大致分为三种:standalone、yarn、mesos。三种分类的区别这里就不一一介绍了,不明白可自行了解。standalone是官方提供的一种集群方式,企业一般不使用。yarn集群方式在企业中应用是比较广泛的,这里也是介绍yarn的集群安装方式。mesos安装适合于超大型集群。
集群节点分配:
hadoop01:Zookeeper、NameNode(active)、ResourceManager(active)
hadoop02:Zookeeper、NameNode(standby)
hadoop03:Zookeeper、 ResourceManager(standby)
hadoop04: DataNode、 NodeManager、 JournalNode、 spark
hadoop05: DataNode、 NodeManager、 JournalNode、 spark
hadoop06: DataNode、 NodeManager、 JournalNode、 spark
二、安装
说明一下:
①选spark的时候要注意与hadoop版本对应。因为hadoop用的是2.7的,所以spark选的是spark-2.1.1-bin-hadoop2.7
②因为spark基于yarn来管理,spark只能安装在NodeManager节点上。
③spark安装放在/home/software目录下。
1、hadoop基于yarn(ha)的搭建,这里介绍步骤了。在我的上一个教程里有详细介绍。
2、安装scala,并配置好环境变量。
3、在NodeManager节点上解压spark文件。
tar -xvf spark-2.1.1-bin-hadoop2.7
3、修改spark-2.1.1-bin-hadoop2.7/conf/spark-env.sh,在文件尾部加上以下内容,其中HADOOP_CONF_DIR是必填项
export JAVA_HOME=/home/jack/jdk1.8.0_144
export SCALA_HOME=/home/jack/scala-2.12.3
export HADOOP_HOME=/home/software/hadoop-2.7.4
export HADOOP_CONF_DIR=/home/software/hadoop-2.7.4/etc/hadoop
export SPARK_MASTER_PORT=7077
export SPARK_EXECUTOR_CORES=2
export SPARK_EXECUTOR_MEMORY=1024m
export SPARK_EXECUTOR_INSTANCES=1
4、修改spark-2.1.1-bin-hadoop2.7/conf/slave文件,添加以下内容:
hadoop04
hadoop05
hadoop06
5、在hdfs上传spark的jar包,并修改/home/software/spark-2.1.1-bin-hadoop2.7/conf/spark-defaults.conf(可不做)
①hadoop fs -mkdir /spark_jars
②hadoop fs -put /home/software/spark-2.1.1-bin-hadoop2.7/jars/* /spark_jars
③修改/home/software/spark-2.1.1-bin-hadoop2.7/conf/spark-defaults.conf,添加以下内容:
spark.yarn.jars=hdfs://hadoop01:9000/spark_jars/*
6、完成以上操作就完成了spark基于yarn的安装。下面是验证部分:
在安装有spark的节点上执行以下命令:
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
--num-executors 3 \
/home/software/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jar \
10
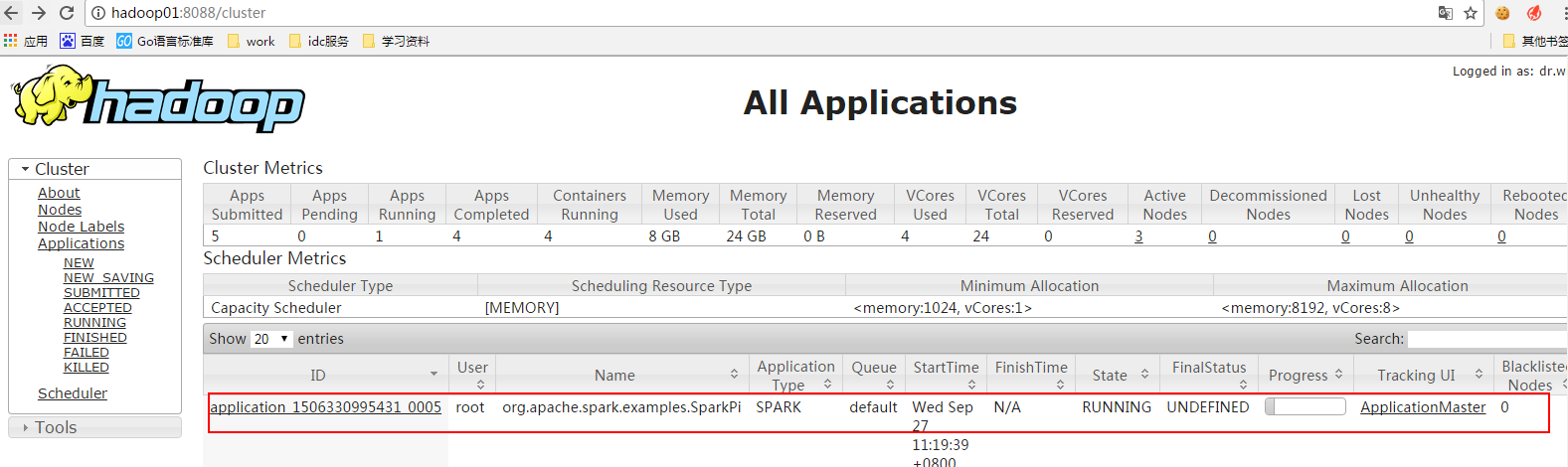
能看以上三张图就说明安装成功了!
备注:如果执行spark-shell --master yarn --deploy-mode client失败,报rpc连接失败,解决方法如下:
在hadoop的配置文件yarn-site.xml中加入:
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
报错的原因是:内存资源给的过小,yarn直接kill掉进程,则报rpc连接失败、ClosedChannelException等错误。
spark-2.1.1 yarn(高可用)搭建的更多相关文章
- hadoop2.6.0高可靠及yarn 高可靠搭建
以前用hadoop2.2.0只搭建了hadoop的高可用,但在hadoop2.2.0中始终没有完成YARN HA的搭建,直接下载了hadoop最新稳定版本2.6.0完成了YARN HA及HADOOP ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- hadoop+zookeeper集群高可用搭建
hadoop+zookeeper集群高可用搭建 Senerity 发布于 2 ...
- 七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
目录 前文 Hadoop3.3.1 HA 高可用集群的搭建 QJM 的 NameNode HA Hadoop HA模式搭建(高可用) 1.集群规划 2.Zookeeper集群搭建: 3.修改Hadoo ...
- 10-Flink集群的高可用(搭建篇补充)
戳更多文章: 1-Flink入门 2-本地环境搭建&构建第一个Flink应用 3-DataSet API 4-DataSteam API 5-集群部署 6-分布式缓存 7-重启策略 8-Fli ...
- Hadoop入门学习笔记-第三天(Yarn高可用集群配置及计算案例)
什么是mapreduce 首先让我们来重温一下 hadoop 的四大组件:HDFS:分布式存储系统MapReduce:分布式计算系统YARN: hadoop 的资源调度系统Common: 以上三大组件 ...
- Qingcloud_MySQL Plus(Xenon) 高可用搭建实验
实验:Xenon on 5.7.30 Xenon (MySQL Plus) 是青云Qingcloud的一个开源项目,号称金融级别强一致性的高可用解决方案,项目地址为 https://github.co ...
- Spring Cloud(Dalston.SR5)--Eureka 注册中心高可用搭建
高可用集群 在微服务架构这样的分布式环境中,我们需要充分考虑发生故障的情况,所以在生产环境中必须对各个组件进行高可用部署,对与微服务和服务注册中心都需要高可用部署,Eureka 高可用实际上就是将自己 ...
- kudu集群高可用搭建
首先咱得有KUDU安装包 这里就不提供直接下载地址了(因为有5G,我 的服务器网卡只有4M,你们下的很慢) 这里使用的是CDH版本 官方下载地址http://archive.cloudera.com/ ...
随机推荐
- Octavia health-manager 与 amphora 故障修复的实现与分析
目录 文章目录 目录 Health Manager 监控 amphora 健康状态 故障转移 故障迁移测试 Health Manager Health Manager - This subcompon ...
- SELECT-OPTIONS对象
1. SELECT-OPTIONS基本语法及定义 SELECT-OPTIONS通常用于参照一数据库字为建立数据输入域,其定义对象命名长度不能超过8位,其产生的屏幕对象最大输入长度为18位,语法如下: ...
- 动态网页基础——JSP
WEB项目的目录结构 META-INT WEB-INF 对外都是不可访问的,不可把index.jsp/index.html 放这 JSP JSP是为了简化Servlet的工作出现的替代品,Servl ...
- [转帖]Intel Xeon路线图:7nm处理器要上DDR5、PCIe 5.0
Intel Xeon路线图:7nm处理器要上DDR5.PCIe 5.0 https://www.cnbeta.com/articles/tech/849631.htm 在月初的投资者会议上,Intel ...
- Linux文件与目录操作 ls 命令(2)
说文件操作是最频繁地操作也不为过,在Linux中,使用ls命令可以列出当前目录中所有内容,本篇就先说说ls命令.本文所说的文件指文件和目录. ls命令常用选项 -a:显示指定目录下所有子目录与文件,包 ...
- 网络流 ISAP算法
网络流问题: 我自己理解,在流网络中,在不违背容量限制的条件下,解决各种从源点到汇点的问题. ISAP算法概念: 据说不会有卡ISAP时间的题目---时间复杂度O(E^2*V) 首先原理都是基于不断寻 ...
- D-多连块拼图
多连块是指由多个等大正方形边与边连接而成的平面连通图形. – 维基百科 给一个大多连块和小多连块,你的任务是判断大多连块是否可以由两个这样的小多连块拼成.小多连块只能平移,不能旋转或者翻转.两个小多连 ...
- 使用mysql的source批量导入多个sql文件
需求: 有一个文件,文件里面包含100多个sql文件,想要把这些sql文件都导入到mysql中 做法: 使用 mysql 的 source 可以将文件导入到 mysql 中,但是一次只能导入一个 sq ...
- Neo4j清空所有数据
两种方法: 一.用下列 Cypher 语句: match (n) detach delete n 二. 1.停掉服务: 2.删除 graph.db 目录: 3.重启服务. 原文地址:http://ne ...
- 使用英特尔® 驱动程序和支持助理更新英特尔®固态盘数据中心工具(英特尔®固态盘 DCT)后仍旧提示更新
再regedit中搜索原始版本,位于计算机\HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Uninstall\{82F015 ...