分布式任务队列 Celery —— 详解工作流
目录
前文列表
前言
Celery 的工作流具有非常浓厚的函数式编程风格,在理解工作流之前,我们需要对「签名」、「偏函数」以及「回调函数」有所了解。
文中所用的示例代码紧接前文,其中 taks.py 模块有少量修改。
# filename: tasks.py
from proj.celery import app
@app.task
def add(x, y, debug=False):
if debug:
print("x: %s; y: %s" % (x, y))
return x + y
@app.task
def log(msg):
return "LOG: %s" % msg任务签名 signature
使用 Celery Signature 签名(Subtask 子任务),可生成一个特殊的对象——任务签名。任务签名和函数签名类似,除了包含函数的常规声明信息(形参、返回值)之外,还包含了执行该函数所需要的调用约定和(全部/部分)实参列表。你可以在任意位置直接使用该签名,甚至不需要考虑实参传递的问题(实参可能在生成签名时就已经包含)。可见,任务签名的这种特性能够让不同任务间的组合、嵌套、调配变得简单。
任务签名支持「直接执行」和「Worker 执行」两种方式:
- 生成任务签名并直接执行:签名在当前进程中执行
>>> from celery import signature
>>> from proj.task.tasks import add
# 方式一
>>> signature('proj.task.tasks.add', args=(2, 3), countdown=10)
proj.task.tasks.add(2, 3)
>>> s_add = signature('proj.task.tasks.add', args=(2, 3), countdown=10)
>>> s_add()
5
# 方式二
>>> add.signature((3, 4), countdown=10)
proj.task.tasks.add(3, 4)
>>> s_add = add.signature((3, 4), countdown=10)
>>> s_add()
7
# 方式三
>>> add.subtask((3, 4), countdown=10)
proj.task.tasks.add(3, 4)
>>> s_add = add.subtask((3, 4), countdown=10)
>>> s_add()
7
# 方式四
>>> add.s(3, 4)
proj.task.tasks.add(3, 4)
>>> s_add = add.s(3, 4)
>>> s_add()
7- 生成任务签名并交由 Worker 执行:签名在 Worker 服务进程中执行
# 调用 delay/apply_async 方法将签名加载到 Worker 中执行
>>> s_add = add.s(2, 2)
>>> s_add.delay()
<AsyncResult: 75be3776-b36b-458e-9a89-512121cdaa32>
>>> s_add.apply_async()
<AsyncResult: 4f1bf824-331a-42c0-9580-48b5a45c2f7a>
>>> s_add = add.s(2, 2)
>>> s_add.delay(debug=True) # 任务签名支持动态传递实参
<AsyncResult: 1a1c97c5-8e81-4871-bb8d-def39eb539fc>
>>> s_add.apply_async(kwargs={'debug': True})
<AsyncResult: 36d10f10-3e6f-46c4-9dde-d2eabb24c61c>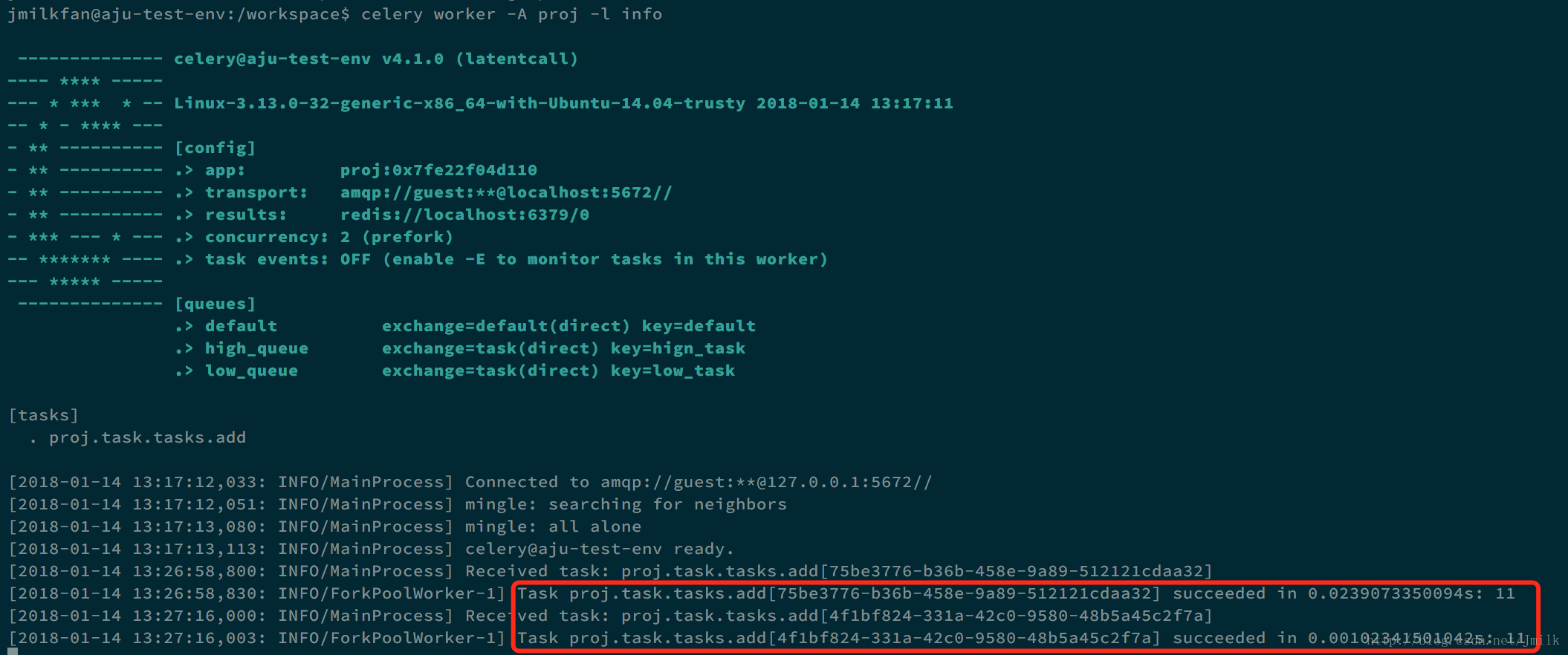
偏函数
偏函数(Partial Function Application,PFA):将拥有任意形参数量(顺序)的函数转化为另一个已经包含了任意实参的新的函数。简单来说,就是返回一个新的函数对象并将函数中的某些形参,固化为实参。从某个角度来看类似函数的默认参数特性,但也并不全是。因为默认参数列表是持久不变的,而 PFA 中,固化的参数列表能够任意定义。对于同一个函数,你可以得到关于它的许多偏函数,而且每一个偏函数的固化参数列表都可以不同。e.g.
# 普通偏函数:
>>> from functools import partial
>>> add_1 = partial(add, 1)
>>> add_1(2)
3
# add_1(x) == add(1, x)
>>> int_base2 = partial(int, base=2)
>>> int_base2.__doc__ = ‘Convert base 2 string to an int.'
>>> int_base2('10010')
18
int_base2(x) == int(x, base=2)Celery 中的偏函数实际上就是固化了部分参数的任务签名。e.g.
# Celery 偏函数
>>> add.s(1)
proj.task.tasks.add(1)
>>> s_add_1 = add.s(1)
>>> s_add_1(10)
11
>>> s_add_1.delay(20)
<AsyncResult: eb88ad9c-31f6-484f-8fd5-735a498aedbc>回调函数
回调函数就是一个通过函数指针(函数名)来调用的函数。如果你把函数指针作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就称之为回调。回调函数在发生特定事件或满足指定条件时被回调,从而对该事件或条件进行响应。
Celery 中的回调函数依旧是一个任务签名,而触发回调的事件或条件就是「任务执行成功」和「任务执行失败」。
调用 apply_async 方法的 link/link_error 来指定回调函数。e.g.
- 任务执行成功回调:
# 默认的,回调函数的实参来自于上一个任务的执行结果
>>> from proj.task.tasks import add, log
>>> result = add.apply_async(args=(1, 2), link=log.s())
>>> result.get()
3
- 任务执行失败回调:
>>> result = add.apply_async(args=(1, 2), link_error=log.s())
>>> result.status
u'SUCCESS'
>>> result.get()
3
如果你希望回调函数的实参不来自于上一个任务的结果,那么你可以将回调函数的实参设置为 immutable(不可变的):
>>> add.apply_async((2, 2), link=log.signature(args=('Task SUCCESS', ), immutable=True))
<AsyncResult: c136ad34-68b4-49a9-8462-84ac8cd75810>
# 简易写法
>>> add.apply_async((2, 2), link=log.si('Task SUCCESS'))
<AsyncResult: bbb35212-5a6b-427b-a6a6-d1eb5359365e>
当然了,回调函数和偏函数可以结合使用,拥有了更好的灵活性:
>>> result = add.apply_async((2, 2), link=add.s(2))
NOTE:需要注意的是,回调函数的结果不会被返回,所以使用 Result.get 只也能获取第一个任务的结果。
>>> result = add.apply_async((2, 2), link=add.s(2))
>>> result.get()
4Celery 工作流
group 任务组
任务组函数接收一组任务签名列表,返回一个新的任务签名——签名组,调用签名组会并行执行其包含的所有任务签名,并返回所有结果的列表。常用于一次性创建多个任务。
>>> from celery import group
>>> from proj.task.tasks import add
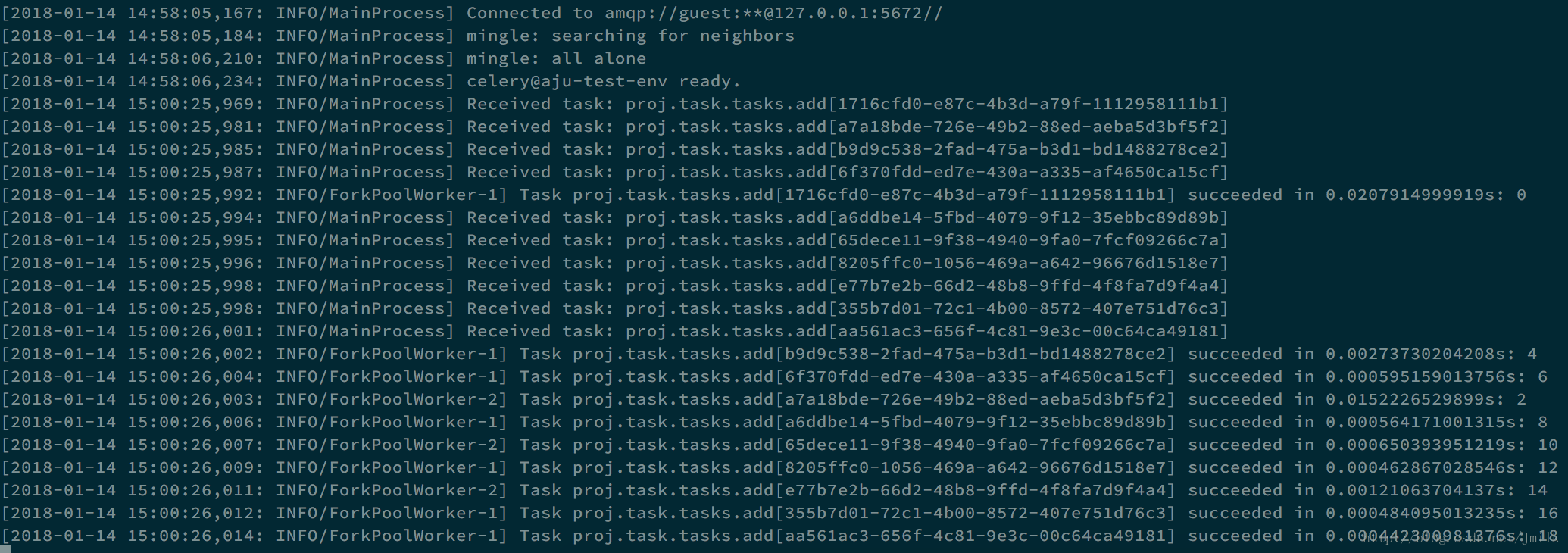
>>> add_group_sig = group(add.s(i, i) for i in range(10))
>>> result = add_group_sig.delay()
>>> result.get()
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
# 返回多个结果
>>> result.results
[<AsyncResult: 1716cfd0-e87c-4b3d-a79f-1112958111b1>,
<AsyncResult: a7a18bde-726e-49b2-88ed-aeba5d3bf5f2>,
<AsyncResult: b9d9c538-2fad-475a-b3d1-bd1488278ce2>,
<AsyncResult: 6f370fdd-ed7e-430a-a335-af4650ca15cf>,
<AsyncResult: a6ddbe14-5fbd-4079-9f12-35ebbc89d89b>,
<AsyncResult: 65dece11-9f38-4940-9fa0-7fcf09266c7a>,
<AsyncResult: 8205ffc0-1056-469a-a642-96676d1518e7>,
<AsyncResult: e77b7e2b-66d2-48b8-9ffd-4f8fa7d9f4a4>,
<AsyncResult: 355b7d01-72c1-4b00-8572-407e751d76c3>,
<AsyncResult: aa561ac3-656f-4c81-9e3c-00c64ca49181>] (并行执行)
chain 任务链
任务链函数接收若干个任务签名,并返回一个新的任务签名——链签名。调用链签名会并串行执行其所含有的任务签名,每个任务签名的执行结果都会作为第一个实参传递给下一个任务签名,最后只返回一个结果。
>>> from celery import chain
>>> from proj.task.tasks import add
>>> add_chain_sig = chain(add.s(1, 2), add.s(3))
# 精简语法
>>> add_chain_sig = (add.s(1, 2) | add.s(3))
>>> result = add_chain_sig.delay() # ((1 + 2) + 3)
>>> result.status
u’SUCCESS’
>>> result.get()
6
# 仅返回最终结果
>>> result.results
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'AsyncResult' object has no attribute 'results'
# 结合偏函数
>>> add_chain_sig = chain(add.s(1), add.s(3))
>>> result = add_chain_sig.delay(3) # ((3 + 1) + 3)
>>> result.get()
7(串行执行)

chord 复合任务
复合任务函数生成一个任务签名时,会先执行一个组签名(不支持链签名),等待任务组全部完成时执行一个回调函数。
>>> from proj.task.tasks import add, log
>>> from celery import chord, group, chain
>>> add_chord_sig = chord(group(add.s(i, i) for i in range(10)), log.s())
>>> result = add_chord_sig.delay()
>>> result.status
u'SUCCESS'
>>> result.get()
u'LOG: [0, 2, 4, 6, 8, 10, 12, 16, 14, 18]'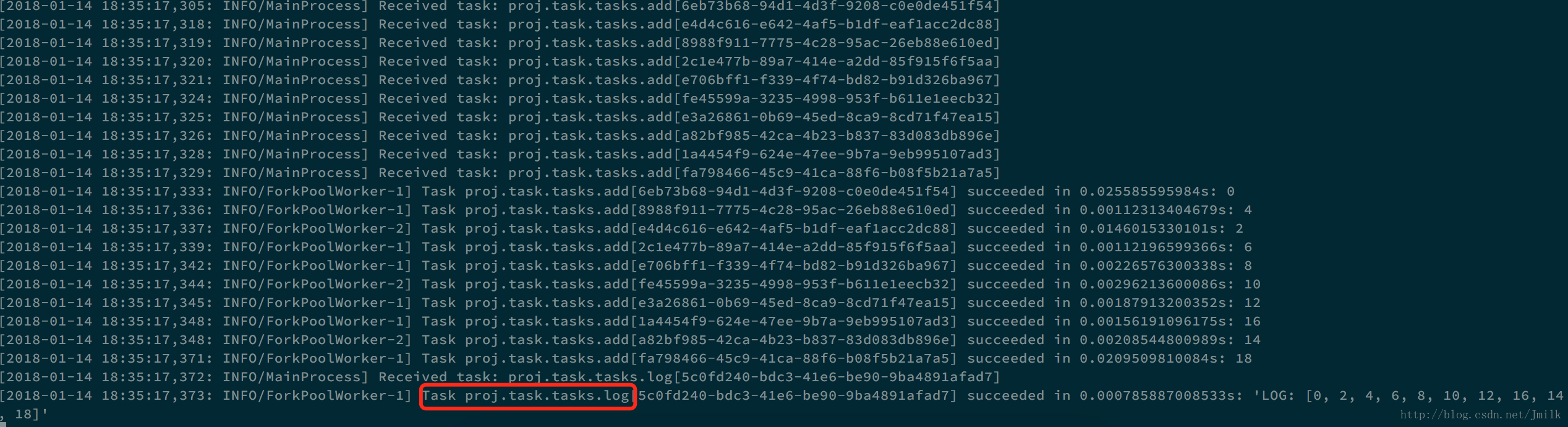
可见任务组函数依旧是并行执行的,但任务组和回调函数时串行执行的,所以 chord 被称为复合任务函数。
chunks 任务块
任务块函数能够让你将需要处理的大量对象分为分成若干个任务块,如果你有一百万个对象,那么你可以创建 10 个任务块,每个任务块处理十万个对象。有些人可能会担心,分块处理会导致并行性能下降,实际上,由于避免了消息传递的开销,因此反而会大大的提高性能。
>>> add_chunks_sig = add.chunks(zip(range(100), range(100)), 10)
>>> result = add_chunks_sig.delay()
>>> result.get()
[[0, 2, 4, 6, 8, 10, 12, 14, 16, 18],
[20, 22, 24, 26, 28, 30, 32, 34, 36, 38],
[40, 42, 44, 46, 48, 50, 52, 54, 56, 58],
[60, 62, 64, 66, 68, 70, 72, 74, 76, 78],
[80, 82, 84, 86, 88, 90, 92, 94, 96, 98],
[100, 102, 104, 106, 108, 110, 112, 114, 116, 118],
[120, 122, 124, 126, 128, 130, 132, 134, 136, 138],
[140, 142, 144, 146, 148, 150, 152, 154, 156, 158],
[160, 162, 164, 166, 168, 170, 172, 174, 176, 178],
[180, 182, 184, 186, 188, 190, 192, 194, 196, 198]]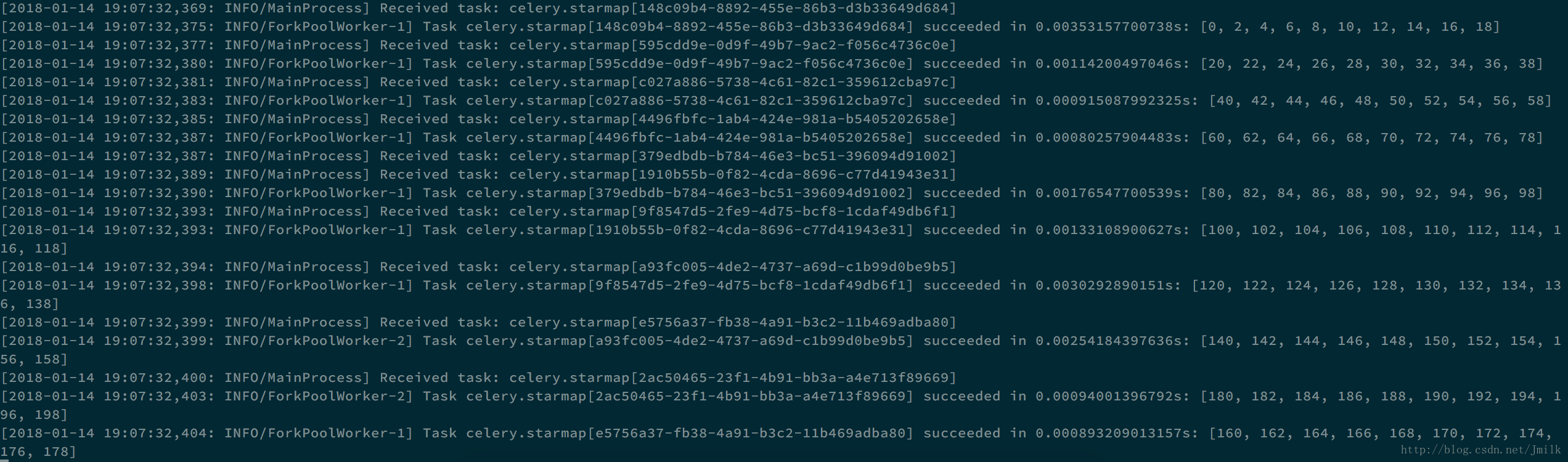
map/starmap 任务映射
映射函数,与 Python 函数式编程中的 map 内置函数相似。都是将序列对象中的元素作为实参依次传递给一个特定的函数。
map 和 starmap 的区别在于,前者的参数只有一个,后者支持的参数有多个。
>>> add.starmap(zip(range(10), range(100)))
[proj.task.tasks.add(*x) for x in [(0, 0), (1, 1), (2, 2), (3, 3), (4, 4), (5, 5), (6, 6), (7, 7), (8, 8), (9, 9)]]
>>> result = add.starmap(zip(range(10), range(100))).delay()
>>> result.get()
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
如果使用 map 来处理 add 函数会报错,因为 map 只能支持一个参数的传入。
>>> add.map(zip(range(10), range(100)))
[proj.task.tasks.add(x) for x in [(0, 0), (1, 1), (2, 2), (3, 3), (4, 4), (5, 5), (6, 6), (7, 7), (8, 8), (9, 9)]]
>>> result = add.map(zip(range(10), range(100))).delay(1)
>>> result.status
u’FAILURE'
分布式任务队列 Celery —— 详解工作流的更多相关文章
- 分布式任务队列 Celery —— Task对象
转载至 JmilkFan_范桂飓:http://blog.csdn.net/jmilk 目录 目录 前文列表 前言 Task 的实例化 任务的名字 任务的绑定 任务的重试 任务的请求上下文 任务的继 ...
- 分布式任务队列 Celery —— 深入 Task
目录 目录 前文列表 前言 Task 的实例化 任务的名字 任务的绑定 任务的重试 任务的请求上下文 任务的继承 前文列表 分布式任务队列 Celery 分布式任务队列 Celery -- 详解工作流 ...
- 分布式任务队列 Celery —— 应用基础
目录 目录 前文列表 前言 Celery 的周期定时任务 Celery 的同步调用 Celery 结果储存 Celery 的监控 Celery 的调试 前文列表 分布式任务队列 Celery 分布式任 ...
- [源码分析] 分布式任务队列 Celery 之 发送Task & AMQP
[源码分析] 分布式任务队列 Celery 之 发送Task & AMQP 目录 [源码分析] 分布式任务队列 Celery 之 发送Task & AMQP 0x00 摘要 0x01 ...
- [源码分析]并行分布式任务队列 Celery 之 子进程处理消息
[源码分析]并行分布式任务队列 Celery 之 子进程处理消息 0x00 摘要 Celery是一个简单.灵活且可靠的,处理大量消息的分布式系统,专注于实时处理的异步任务队列,同时也支持任务调度.在前 ...
- celery详解
目录 Celery详解 1.背景 2.形象比喻 3.celery具体介绍 3.1 Broker 3.2 Backend 4.使用 4.1 celery架构 4.2 安装redis+celery 4.3 ...
- 分布式任务队列 Celery
目录 目录 前言 简介 Celery 的应用场景 架构组成 Celery 应用基础 前言 分布式任务队列 Celery,Python 开发者必备技能,结合之前的 RabbitMQ 系列,深入梳理一下 ...
- [源码解析] 分布式任务队列 Celery 之启动 Consumer
[源码解析] 分布式任务队列 Celery 之启动 Consumer 目录 [源码解析] 分布式任务队列 Celery 之启动 Consumer 0x00 摘要 0x01 综述 1.1 kombu.c ...
- [源码解析] 并行分布式任务队列 Celery 之 Task是什么
[源码解析] 并行分布式任务队列 Celery 之 Task是什么 目录 [源码解析] 并行分布式任务队列 Celery 之 Task是什么 0x00 摘要 0x01 思考出发点 0x02 示例代码 ...
随机推荐
- 关于myBatis配置中的一些注意事项
最近在学习mybatis,在网上查阅资料,并按照别人的范例来测试,总会出一些错误,这里把配置过程中的一些注意事项梳理一下. 一.导包(用eclipse开发) 1.如果你新建的是普通的project,需 ...
- Vim搜索关键字
有以下两种方法 Method 1:/content 默认从上往下查找 只读模式下输入 /content 后回车 按 n 向下查找 按N 向上查找 Method 2:?content 默认从下往上查找 ...
- FPDF_CHAR_INFO
typedef struct { FX_WCHAR m_Unicode; FX_WCHAR m_Charcode; FX_INT32 m_Flag; FX_FLOAT m_FontSize; FX_F ...
- Luogu P2595 [ZJOI2009]多米诺骨牌 容斥,枚举,插头dp,轮廓线dp
真的是个好(毒)题(瘤).其中枚举的思想尤其值得借鉴. \(40pts\):插头\(dp\),记录插头的同时记录每一列的连接状况,复杂度\(O(N*M*2^{n + m} )\). \(100pts\ ...
- java课堂作业3 动手动脑
第一题 测试一下代码查看输出结果 public class InitializeBlockDemo { /** * @param args */ public static void main(Str ...
- thinkphp一般数据库操作
引入命名空间 插入 更新 查询 删除 一些支持命令行的操作 清空操作 分库操作 分库相关配置---在config.php中进行 使用: 参数绑定 占位符绑定 第一句后半拉
- 【Linux】CentOS6上redis安装
1.官网下载安装包 https://redis.io 2.解压 tar -zxvf xxxx.tar.gz 3.编译安装 进入解压后的目录后 make 出现以下内容表示make成功 Hint: It' ...
- k8-s存储
原文 https://mp.weixin.qq.com/s/6yg_bt5mYKWdXS0CidY6Rg 从用户角度看,存储就是一块盘或者一个目录,用户不关心盘或者目录如何实现,用户要求非常" ...
- const与#define的区别
1.const (1)为什么需要const成员函数? C中常用:“ #define 变量名 变量值”定义一个值替代,然而却有个致命缺点:缺乏类型检测机制,这样预处理在C++中成为可能引发错误的隐患,于 ...
- sh_08_打印分隔线
sh_08_打印分隔线 def print_line(char, times): print(char * times) print_line("hi ", 40)