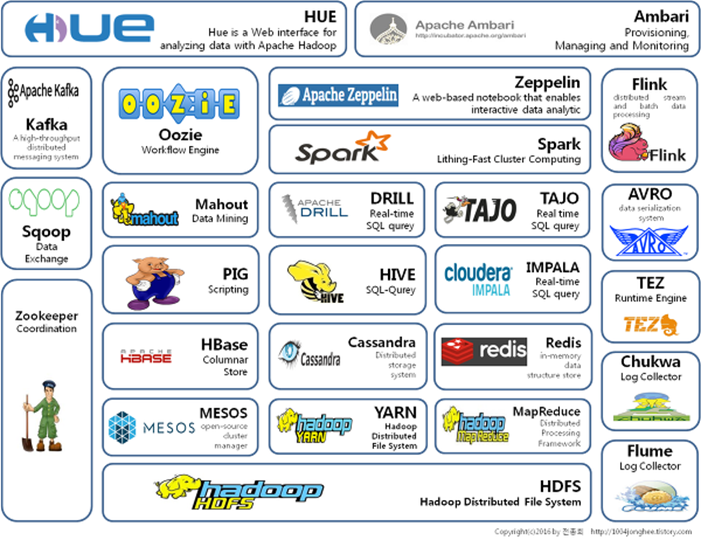
Ambari 2.6.0 HDP 2.6.3集群搭建
1.安装环境说明
三台机器安装好CentOS-7-x86_64-Minimal-1708.iso
下载地址:https://www.centos.org/download/
最好在安装时设置好IP和HOSTNAME
三台机器的IP和HOSTNAME下载如下
主 192.168.31.11 SY-001.hadoop
从 192.168.31.12 SY-002.hadoop
从 192.168.31.13 SY-003.hadoop
每个节点设置host
[root@SY-001 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.31.11 SY-001 SY-001.hadoop
192.168.31.12 SY-002 SY-002.hadoop
192.168.31.13 SY-003 SY-003.hadoop
2.操作系统环境准备
2.1 配置SSH免密码登录
主节点里root用户登录执行如下步骤
[root@SY-001 ~]# ssh-keygen
[root@SY-001 ~]# cd ~/.ssh/
[root@SY-001 ~]# cat id_rsa.pub >>authorized_keys
[root@SY-001 ~]# chmod 600 ~/.ssh
[root@SY-001 ~]# chmod 600 ~/.ssh/authorized_keys
先在从节点登录root执行命令
[root@SY-002 ~]# mkdir ~/.ssh/
[root@SY-003 ~]# mkdir ~/.ssh/
分发主节点里配置好的authorized_keys到各从节点
[root@SY-001 ~]# scp /root/.ssh/authorized_keys root@192.168.31.12:/root/.ssh/authorized_keys
[root@SY-001 ~]# scp /root/.ssh/authorized_keys root@192.168.31.13:/root/.ssh/authorized_keys
2.2 创建ambari系统用户和用户组
只在主节点操作
添加ambari安装、运行用户和用户组,也可以不创建新用户,直接使用root,我是直接用的root
[root@SY-001 ~]# adduser ambari
[root@SY-001 ~]# passwd ambari
2.3 开启NTP服务
所有节点都需要操作
[root@SY-001 ~]# yum install ntp
[root@SY-001 ~]# systemctl is-enabled ntpd
[root@SY-001 ~]# systemctl enable ntpd
[root@SY-001 ~]# systemctl start ntpd
2.4 检查DNS和NSCD
所有节点都要设置
ambari在安装时需要配置全域名,所以需要检查DNS。为了减轻DNS的负担, 建议在节点里用 Name Service Caching Daemon (NSCD)
[root@SY-001 ~]# vi /etc/hosts
192.168.131.11 SY-001 SY-001.hadoop
192.168.131.12 SY-002 SY-002.hadoop
192.168.131.13 SY-003 SY-003.hadoop
每台节点里配置FQDN,如下以主节点为例
[root@SY-001 ~]# vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=SY-001.hadoop
2.5 关闭防火墙
所有节点都要设置
[root@SY-001 ~]# systemctl disable firewalld
[root@SY-001 ~]# systemctl stop firewalld
2.6 关闭SELinux
所有节点都要设置
查看SELinux状态:
[root@SY-001 ~]# sestatus
SELinux status: enabled
[root@SY-001 ~]# sestatus
SELinux status: disabled
临时关闭,不用重启机器:
[root@SY-001 ~]# setenforce 0
修改配置文件需要重启机器:
[root@SY-001 ~]# vi /etc/sysconfig/selinux
SELINUX=disabled
3.制作本地源
制作本地源只需在主节点上进行即可
3.1 相关准备工作
3.1.1安装 Apache HTTP 服务器
安装HTTP 服务器,允许 http 服务通过防火墙(永久)
[root@SY-001 ~]# yum install httpd
[root@SY-001 ~]# firewall-cmd --add-service=http
[root@SY-001 ~]# firewall-cmd --permanent --add-service=http
添加 Apache 服务到系统层使其随系统自动启动
[root@SY-001 ~]# systemctl start httpd.service
[root@SY-001 ~]# systemctl enable httpd.service
3.1.2 安装本地源制作相关工具
[root@SY-001 ~]# yum install yum-utils createrepo
3.2 下载安装资源
下载 Ambari 2.6.0 , HDP 2.6.3 的安装资源,本次安装是在CentOS 7 上,只列出CentOS 7的资源,其他系统的请现在对用系统的资源
Ambari 2.6.0 下载资源
|
RedHat 7 CentOS 7 Oracle Linux 7 |
Base URL |
http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.6.0.0 |
|
Repo File |
http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.6.0.0/ambari.repo |
|
|
Tarball |
http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.6.0.0/ambari-2.6.0.0-centos7.tar.gz |
HDP 2.6.3 下载资源
|
RedHat 7 CentOS 7 Oracle Linux 7 |
HDP-2.6.3.0 |
HDP |
Version Definition File (VDF) |
http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.6.3.0/HDP-2.6.3.0-235.xml |
|
Base URL |
http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.6.3.0 |
|||
|
Repo File |
http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.6.3.0/hdp.repo |
|||
|
Tarball |
http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.6.3.0/HDP-2.6.3.0-centos7-rpm.tar.gz |
|||
|
HDP-UTILS |
Base URL |
http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.21/repos/centos7 |
||
|
Tarball |
http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.21/repos/centos7/HDP-UTILS-1.1.0.21-centos7.tar.gz |
下载上面列表的中的压缩包,
需要下载的压缩包如下:
Ambari2.6.0
http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.6.0.0/ambari-2.6.0.0-centos7.tar.gz
HDP2.6.3
http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.6.3.0/HDP-2.6.3.0-centos7-rpm.tar.gz
HDP-UTILS1.1.0.21
在httpd网站根目录,默认是即/var/www/html/,创建目录ambari,
并且将下载的压缩包解压到/var/www/html/ambari目录
HDP-UTILS需要先建立一个HDP-UTILS文件夹并将HDP-UTILS-1.1.0.21-centos7.tar.gz放到HDP-UTILS目录下再解压
[root@SY-001 ~]# cd /var/www/html/
[root@SY-001 html]# mkdir ambari
[root@SY-001 html]# cd /var/www/html/ambari/
[root@SY-001 ambari]# wget http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.6.0.0/ambari-2.6.0.0-centos7.tar.gz
[root@SY-001 ambari]# wget http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.6.3.0/HDP-2.6.3.0-centos7-rpm.tar.gz
[root@SY-001 ambari]# wget http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.21/repos/centos7/HDP-UTILS-1.1.0.21-centos7.tar.gz
[root@SY-001 ambari]# tar -zxvf ambari-2.6.0.0-centos7.tar.gz
[root@SY-001 ambari]# tar -zxvf HDP-2.6.3.0-centos7-rpm.tar.gz
[root@SY-001 ambari]# mkdir HDP-UTILS
[root@SY-001 ambari]# mv HDP-UTILS-1.1.0.21-centos7.tar.gz /var/www/html/ambari/HDP-UTILS/
[root@SY-001 ambari]# tar -zxvf HDP-UTILS-1.1.0.21-centos7.tar.gz
验证httpd网站是否可用,用浏览器直接访问下面的地址,如果能看到目录列表就表示成功:
http://192.168.31.1/ambari/
3.3 配置ambari、HDP、HDP-UTILS的本地源
首先下载上面资源列表中的相应repo文件,修改其中的URL为本地的地址,相关配置如下:
ambari.repo
[root@SY-001 yum.repos.d]# vi ambari.repo
#VERSION_NUMBER=2.6.0.0-267
[ambari-2.6.0.0]
name=ambari Version - ambari-2.6.0.0
baseurl=http://192.168.31.11/ambari/ambari/centos7/2.6.0.0-267
gpgcheck=1
gpgkey=http://192.168.31.11/ambari/ambari/centos7/2.6.0.0-267/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
hdp.repo
[root@SY-001 yum.repos.d]# vi hdp.repo
#VERSION_NUMBER=2.6.3.0-235
[HDP-2.6.3.0]
name=HDP Version - HDP-2.6.3.0
baseurl=http://192.168.31.11/ambari/HDP/centos7/2.6.3.0-235
gpgcheck=1
gpgkey=http://192.168.31.11/ambari/HDP/centos7/2.6.3.0-235/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
[HDP-UTILS-1.1.0.21]
name=HDP Utils Version - HDP-UTILS-1.1.0.21
baseurl=http://192.168.31.11/ambari/HDP-UTILS
gpgcheck=1
gpgkey=http://192.168.31.11/ambari/HDP-UTILS/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
将上面的修改过的源放到/etc/yum.repos.d/下面
[root@SY-001 yum.repos.d]# yum clean all
[root@SY-001 yum.repos.d]# yum list update
[root@SY-001 yum.repos.d]# yum makecache
[root@SY-001 yum.repos.d]# yum repolist
3.4 安装Mysql数据库
Ambari安装会将安装等信息写入数据库,建议使用MariaDB数据库,也可以不安装而使用默认数据库PostgreSQL
[root@SY-001 ~]# yum install mariadb-server
[root@SY-001 ~]# systemctl start mariadb
[root@SY-001 ~]# systemctl enable mariadb
#数据库初始化设置
[root@SY-001 ~]# mysql_secure_installation
#首先是设置密码,会提示先输入密码
Enter current password for root (enter for none):<–初次运行直接回车
#设置密码
Set root password? [Y/n] <– 是否设置root用户密码,输入y并回车或直接回车
New password: <– 设置root用户的密码
Re-enter new password: <– 再输入一次你设置的密码
#其他配置
Remove anonymous users? [Y/n] <– 是否删除匿名用户,回车
Disallow root login remotely? [Y/n] <–是否禁止root远程登录,回车,
Remove test database and access to it? [Y/n] <– 是否删除test数据库,回车
Reload privilege tables now? [Y/n] <– 是否重新加载权限表,回车
#初始化MariaDB完成,接下来测试登录,输入密码能正常登陆就完成了
[root@SY-001 ~]# mysql -uroot -p
安装完成后创建ambari数据库及用户,登录数据库root用户执行下面语句:
[root@SY-001 ~]# mysql -uroot -p
createdatabase ambari characterset utf8 ;
CREATEUSER'ambari'@'%'IDENTIFIED BY'Ambari-123';
GRANTALLPRIVILEGESON *.* TO'ambari'@'%';
FLUSH PRIVILEGES;
如果要安装Hive,再创建Hive数据库和用户再执行下面的语句:
createdatabase hive characterset utf8 ;
CREATEUSER'hive'@'%'IDENTIFIED BY'Hive-123';
GRANTALLPRIVILEGESON *.* TO'hive'@'%';
FLUSH PRIVILEGES;
如果要安装Oozie,再创建Oozie数据库和用户再执行下面的语句:
createdatabase oozie characterset utf8 ;
CREATEUSER'oozie'@'%'IDENTIFIED BY'Oozie-123';
GRANTALLPRIVILEGESON *.* TO'oozie'@'%';
FLUSH PRIVILEGES;
安装mysql jdbc 驱动
[root@SY-001 ~]# yum install mysql-connector-java
3.5 安装JDK
Java SE Development Kit 8u152下载地址:http://www.oracle.com/technetwork/cn/java/javase/downloads/jdk8-downloads-2133151-zhs.html
下载解压版jdk-8u152-linux-x64.tar.gz,再执行下面命令:
[root@SY-001 ~]# tar -zxvf jdk-8u152-linux-x64.tar.gz -C /opt/java/
[root@SY-001 ~]# vi /etc/profile
export JAVA_HOME=/opt/java/jdk1.8.0_152
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin
source /etc/profile
4.进行安装Ambari
4.1 安装Ambari2.6.0
4.1.1安装Ambari
[root@SY-001 ~]# yum install ambari-server
4.1.2配置Ambari
[root@SY-001 ~]# ambari-server setup
下面是配置执行流程,按照提示操作
1.检查SELinux是否关闭,如果关闭不用操作
Using python /usr/bin/python
Setup ambari-server
Checking SELinux...
SELinux status is'disabled'
2.提示是否自定义设置。输入:y
Customize user account for ambari-server daemon [y/n] (n)? y
3.ambari-server 账号。输入:ambari
Enter user account for ambari-server daemon (root):ambari
Adjusting ambari-server permissions and ownership...
4.检查防火墙,如果关闭则不用操作
Checking firewall status...
Redirecting to /bin/systemctl status iptables.service
5.设置JDK。输入:3
Checking JDK...
Do you want to change Oracle JDK [y/n] (n)? y
[] Oracle JDK 1.8 + Java Cryptography Extension (JCE) Policy Files 8
[] Oracle JDK 1.7 + Java Cryptography Extension (JCE) Policy Files 7
[] Custom JDK
==============================================================================
Enter choice (1): 3
6.如果上面选择3自定义JDK,则需要设置JAVA_HOME。输入:/opt/java/jdk1.8.0_152
WARNING: JDK must be installed onall hosts and JAVA_HOME must be valid onall hosts.
WARNING: JCE Policy files are required for configuring Kerberos security. If you plan to use Kerberos,please make sure JCE Unlimited Strength Jurisdiction Policy Files are valid onall hosts.
Path to JAVA_HOME: /opt/java/jdk1.8.0_152
Validating JDK on Ambari Server...done.
Completing setup...
7.数据库配置。选择:y
Configuringdatabase...
Enteradvanceddatabaseconfiguration[y/n] (n)? y
8.选择数据库类型。输入:3
Configuring database...
==============================================================================
Choose one of the following options:
[1] - PostgreSQL (Embedded)
[2] - Oracle
[3] - MySQL
[4] - PostgreSQL
[5] - Microsoft SQL Server (Tech Preview)
[6] - SQL Anywhere
==============================================================================
Enter choice (3): 3
9.设置数据库的具体配置信息,根据实际情况输入,如果和括号内相同,则可以直接回车。
Hostname (localhost):
Port (3306):
Database name (ambari):
Username (ambari):
Enter Database Password (Ambari-123):
10.提示必须安装MySQL JDBC,回车结束ambari配置
WARNING: Before starting Ambari Server, you must copy the MySQL JDBC driver JAR file to /usr/share/java.
Press <enter> to continue.
11.将Ambari数据库脚本导入到数据库
如果使用自己定义的数据库,必须在启动Ambari服务之前导入Ambari的sql脚本
#用Ambari用户(上面设置的用户)登录mysql
mysql -u ambari -p
use ambari;
source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
4.1.3启动Amabri
执行启动命令,启动Ambari服务
[root@SY-001 ~]# ambari-server start
成功启动后在浏览器输入Ambari地址:
http://192.168.31.1:8080/
出现登录界面,默认管理员账户登录,账户:admin 密码:admin
以下图片用的别人的图片,版本较低,仅供参考

登录成功后出现下面的界面,至此Ambari的安装成功
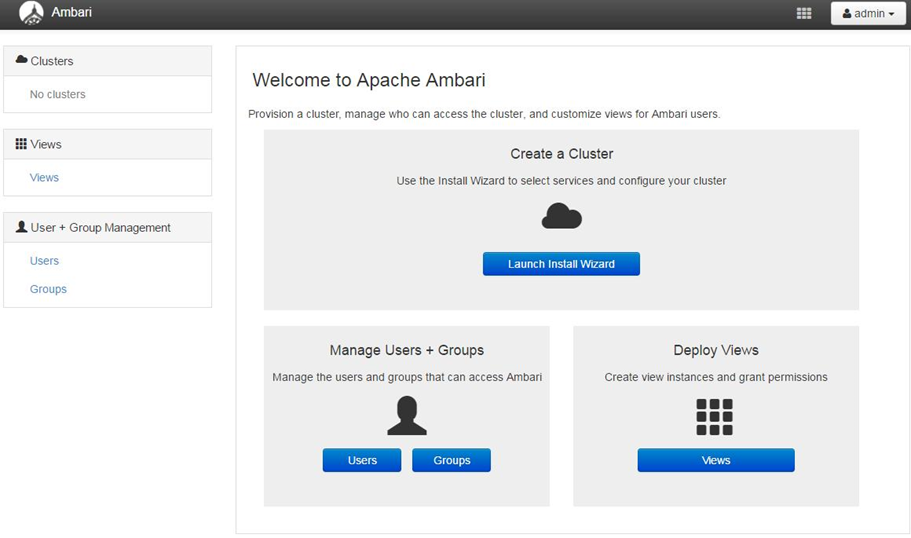
4.2 安装安装HDP 2.6.3 配置集群
点击上面登录成功页面的Launch Install Wizard 按钮进行集群配置
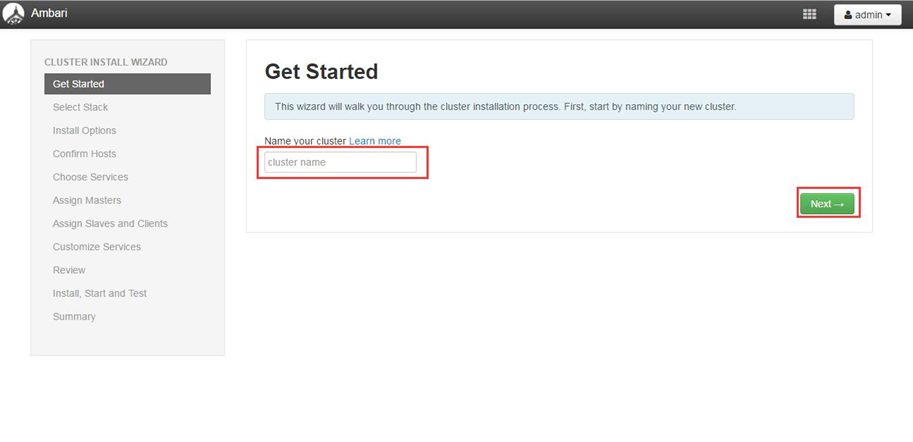
4.2.1设置集群名称
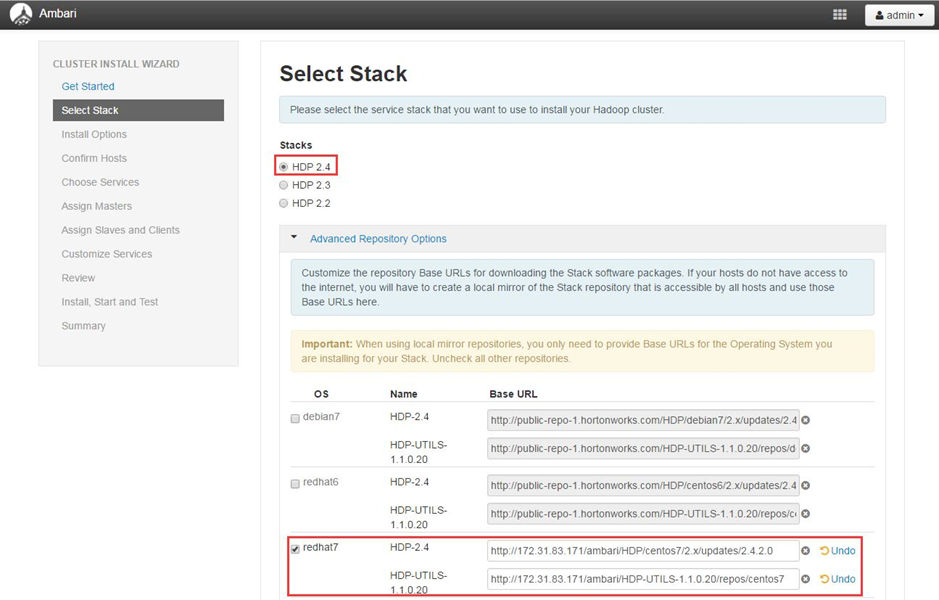
4.2.2设置HDP 安装源
选择HDP2.6 ,并且设置Advanced Repository Options 的信息,本次使用本地源,所以修改对用系统的安装源为本地源地址。
4.2.3设置集群机器
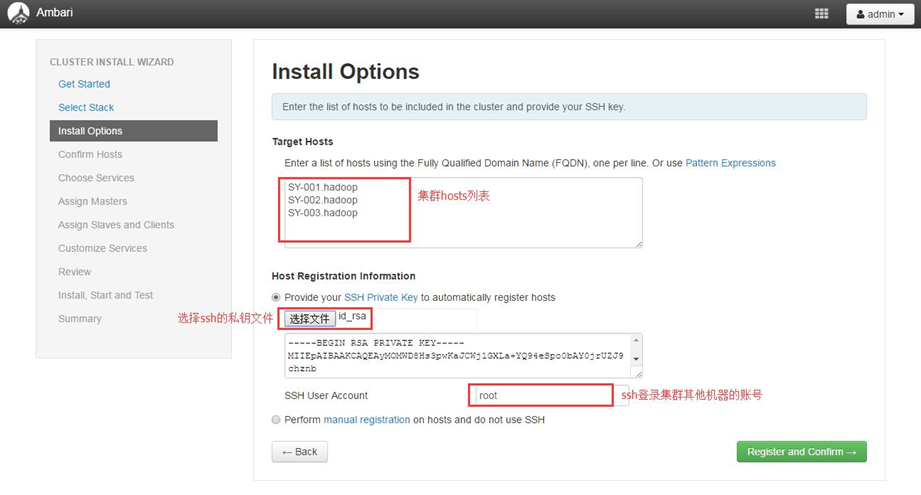
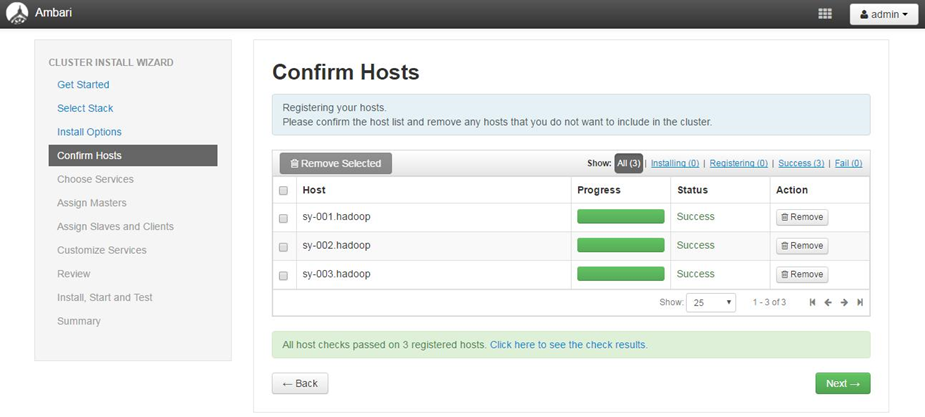
4.2.4 Host 确认
确认前面配置集群中hosts列表中的机器是否都可用,也可以移除相关机器,集群中机器Success后进行下一步操作。
4.2.5 选择要安装的服务

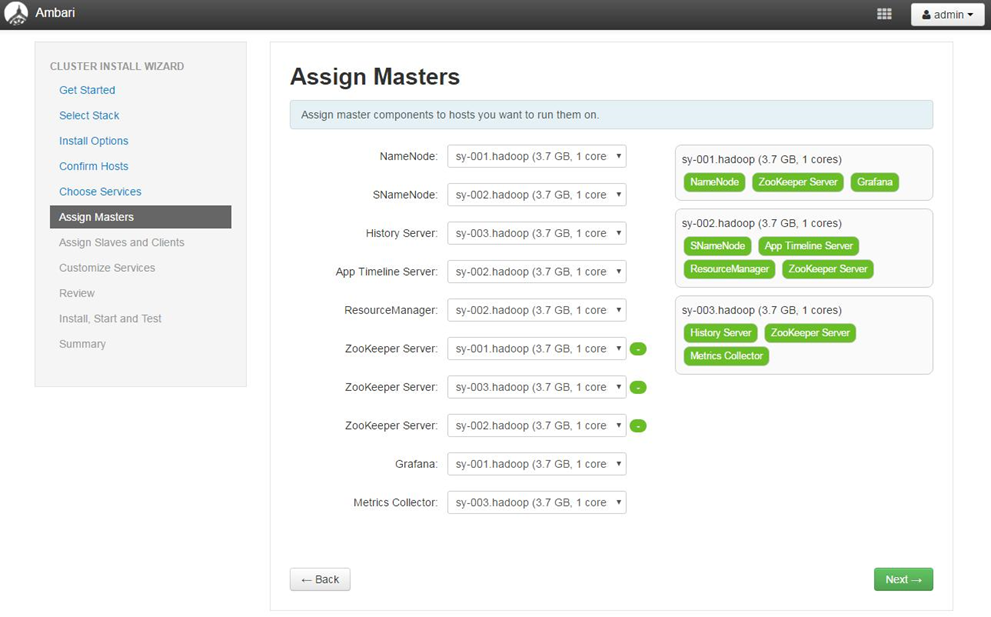
4.2.6各个服务Master配置
4.2.6 服务的Slaves 和 Clients节配置

4.2.7 服务的客制化配置
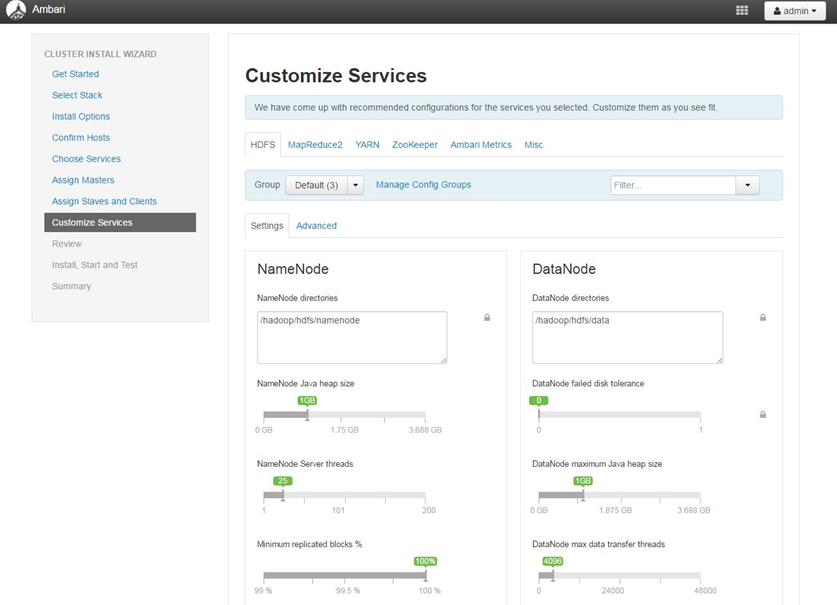
4.2.8 显示配置信息
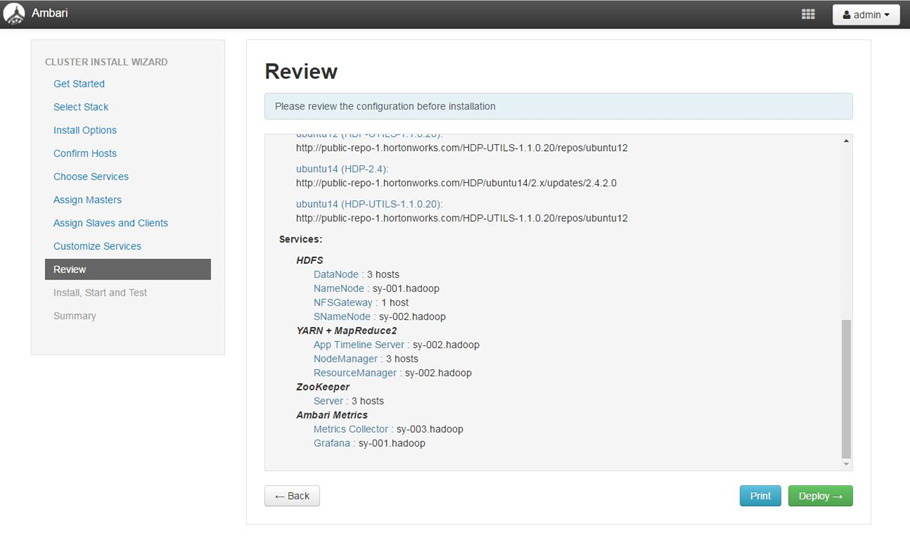
4.2.9开始安装
安装各个服务,并且完成安装后会启动相关服务,安装过程比较长,如果中途出现错误,请根据具体提示或者log进行操作。
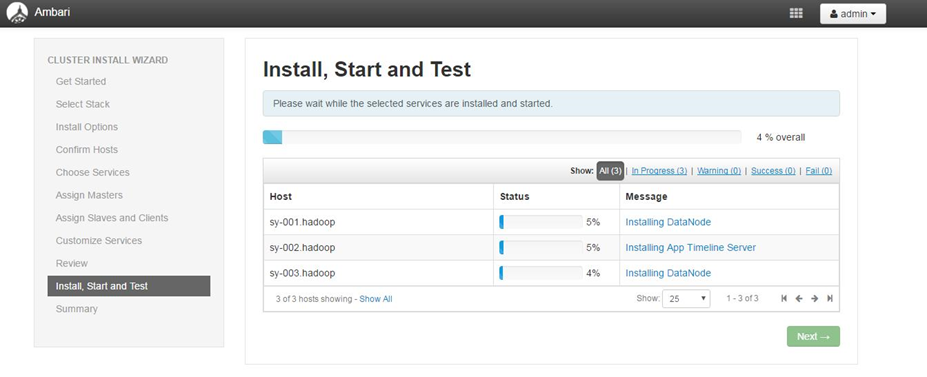
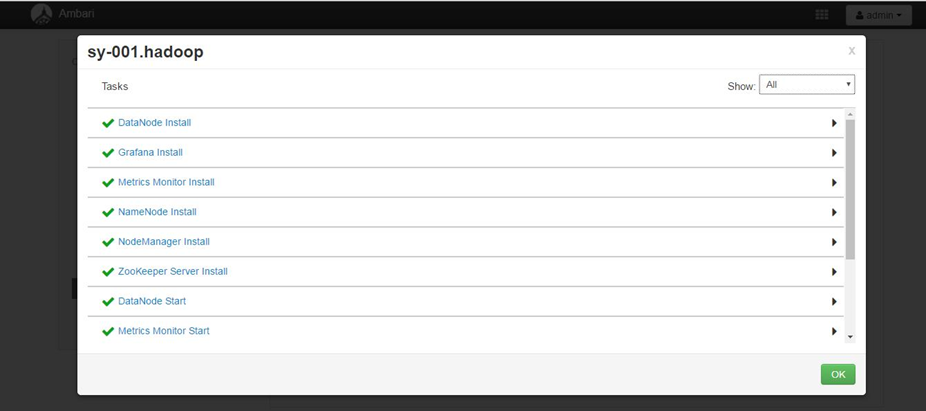
安装过程可以随时查看每个节点的安装进度及日志
全部安装成功界面如下
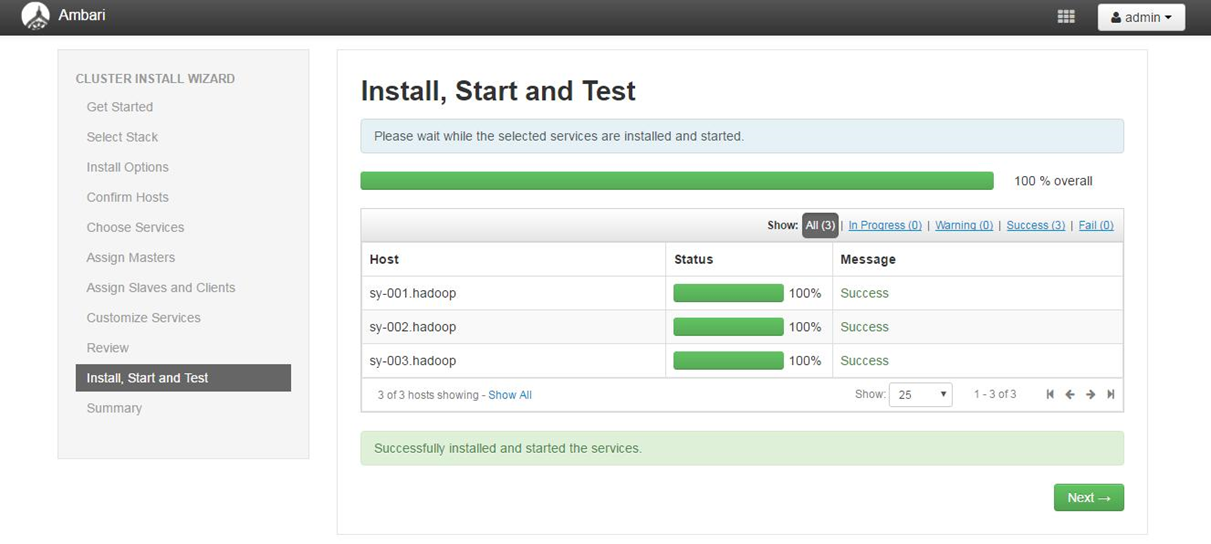
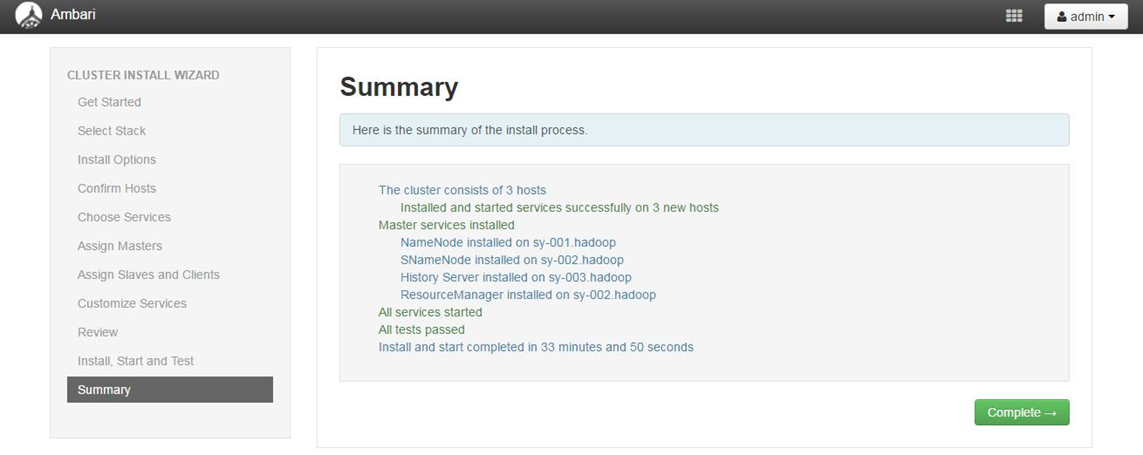
4.2.10安装完成

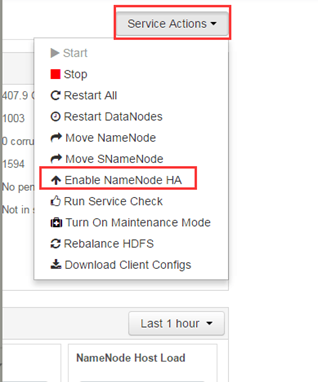
5、Hadooop开启高可用(现在安装好Hadoop是不支高可用的,下面准备开启Hadoop高可用)
1、开启高可用开关
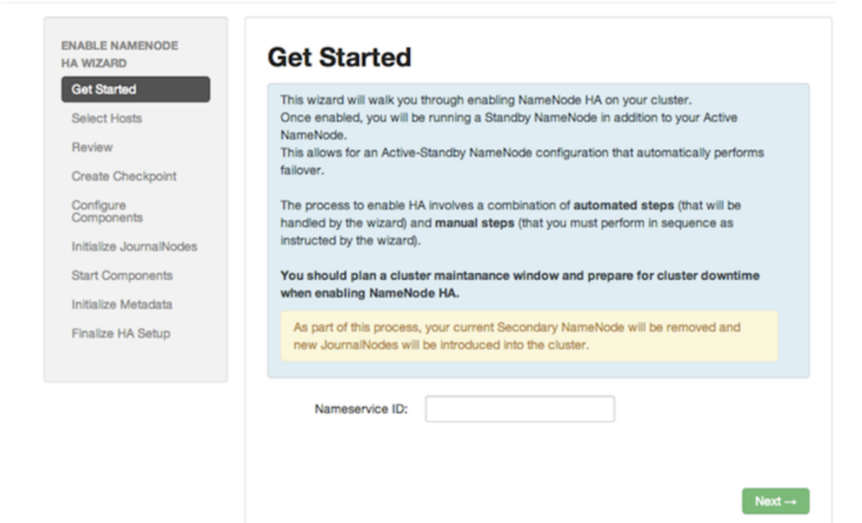
2、设置高可用名称(如果hbase是启动的话请关闭在开启HA高可用)
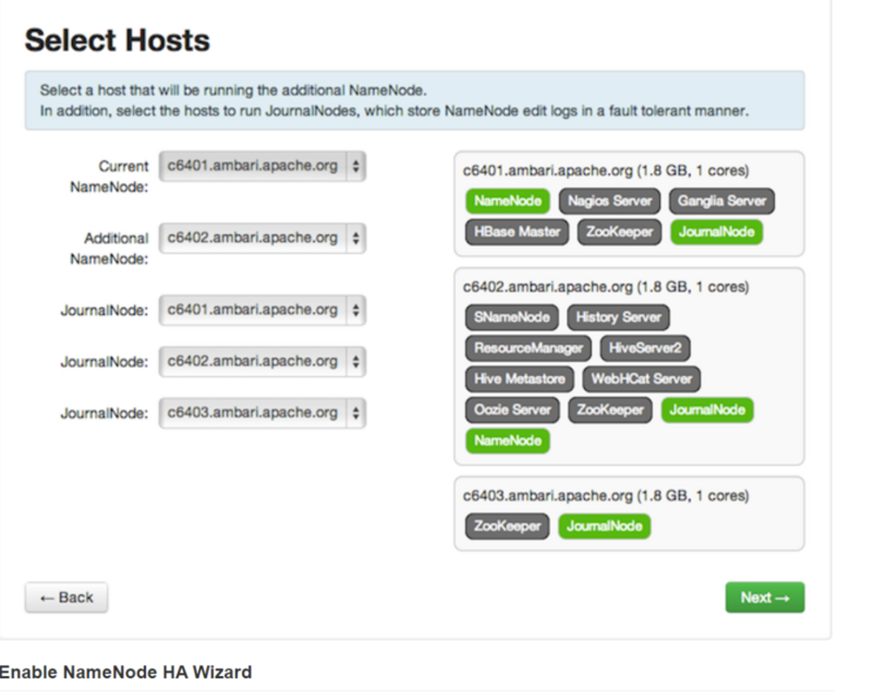
3、选择服务安装在那台主机上
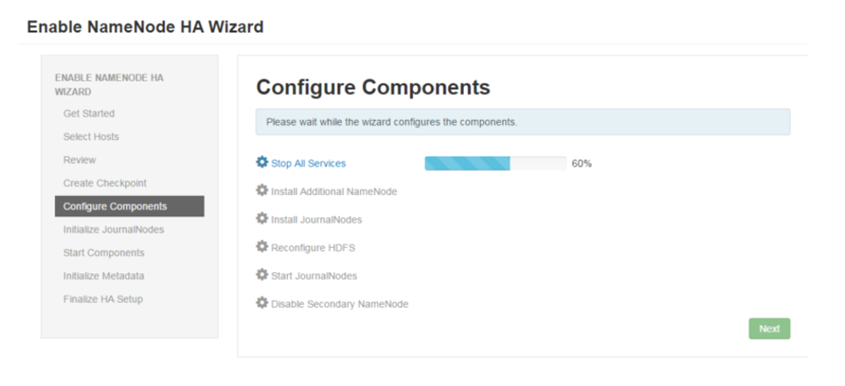
4、按照提示操作,最后显示如下表示HA安装成功

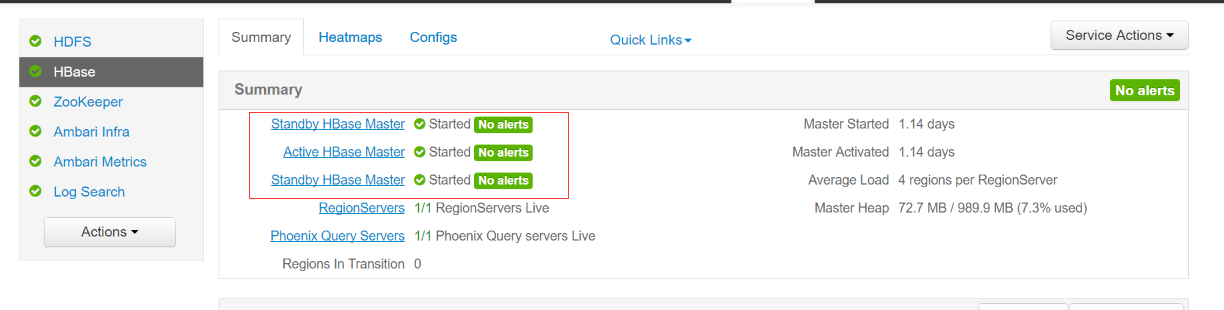
5、Hbase高可用会显示如下图
参考资料:
http://blog.csdn.net/mawenwu1983/article/details/78983275
参考资料:
http://blog.csdn.net/mawenwu1983/article/details/78983275
Ambari 2.6.0 HDP 2.6.3集群搭建的更多相关文章
- Kafka 0.9+Zookeeper3.4.6集群搭建、配置,新Client API的使用要点,高可用性测试,以及各种坑 (转载)
Kafka 0.9版本对java client的api做出了较大调整,本文主要总结了Kafka 0.9在集群搭建.高可用性.新API方面的相关过程和细节,以及本人在安装调试过程中踩出的各种坑. 关于K ...
- apache-storm-1.0.2.tar.gz的集群搭建(3节点)(图文详解)(非HA和HA)
不多说,直接上干货! Storm的版本选取 我这里,是选用apache-storm-1.0.2.tar.gz apache-storm-0.9.6.tar.gz的集群搭建(3节点)(图文详解) 为什么 ...
- 【原创】《从0开始学RocketMQ》—集群搭建
用两台服务器,搭建出一个双master双slave.无单点故障的高可用 RocketMQ 集群.此处假设两台服务器的物理 IP 分别为:192.168.50.1.192.168.50.2. 内容目录 ...
- Mac MySQL 8.0 (免安装版) 主从集群搭建
一.下载解压包 打开 MySQL 官网地址:https://dev.mysql.com/downloads/mysql/ ,选择面安装版本. 二.解压文件 下载到合适文件夹,解压压缩包. 解压 mys ...
- 基于【CentOS-7+ Ambari 2.7.0 + HDP 3.0】搭建HAWQ数据仓库01 —— 准备环境,搭建本地仓库,安装ambari
一.集群软硬件环境准备: 操作系统: centos 7 x86_64.1804 Ambari版本:2.7.0 HDP版本:3.0.0 HAWQ版本:2.3.05台PC作为工作站: ep-bd01 e ...
- 基于【CentOS-7+ Ambari 2.7.0 + HDP 3.0】搭建HAWQ数据仓库——操作系统配置,安装必备软件
注意未经说明,所有本文中所有操作都默认需要作为root用户进行操作. 一.安装zmodem,用于远程上传下载文件,安装gedit,方便重定向到远程windows上编辑文件(通过xlanuch) [ro ...
- Ambari HDP集群搭建全攻略
世界上最快的捷径,就是脚踏实地,本文已收录[架构技术专栏]关注这个喜欢分享的地方. 最近因为工作上需要重新用Ambari搭了一套Hadoop集群,就把搭建的过程记录了下来,也希望给有同样需求的小伙伴们 ...
- MongoDBV3.0.7版本(shard+replica)集群的搭建及验证
集群的模块介绍: 从MongoDB官方给的集群架构了解,整个集群主要有4个模块:Config Server.mongs. shard.replica set: Config Server:用来存放集群 ...
- Apache Spark-1.0.1集群搭建
欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3866791.html Apache Spark a fast and general engine ...
随机推荐
- java实现顺序队列
package queue; import java.util.Scanner; public class ArrayQueueLoop { public static void main(Strin ...
- POJ - 1251 Jungle Roads (最小生成树&并查集
#include<iostream> #include<algorithm> using namespace std; ,tot=; const int N = 1e5; ]; ...
- 列出连通集(DFS及BFS遍历图) -- 数据结构
题目: 7-1 列出连通集 (30 分) 给定一个有N个顶点和E条边的无向图,请用DFS和BFS分别列出其所有的连通集.假设顶点从0到N−1编号.进行搜索时,假设我们总是从编号最小的顶点出发,按编号递 ...
- scrapy架构图与执行流程
概览 本文描述了Scrapy的架构图.数据流动.以及个组件的相互作用 架构图与数据流 上图中各个数字与箭头代表数据的流动方向和流动顺序,具体执行流程如下: 0. Scrapy将会实例化一个Crawle ...
- [WPF]BringIntoView
1.在scrollview 中的frameworkelement可以使用 FE.BringIntoView(); 滚动到此控件. 2.该 方法能一个重载 Bottom.BringIntoView(ne ...
- 企业面试题|最常问的MySQL面试题集合(三)
分区表的原理 分库分表的原理 延伸: MySQL的复制原理及负载均衡 分区表的工作原理 对用户而言,分区表是一个独立的逻辑表,但是底层MySQL将其分成了多个物理子表,这对用户来说是透明的,每一个分区 ...
- notes-19-05-10
一 mysql查找一个表中字段相同的数据 2019-05-10 15:51:03 多字段 ) 二 Referer的作用?2019-05-17 10:03:48 (来自网络) 1.防盗链我在www ...
- 异步分布式队列Celery
异步分布式队列Celery 转载地址 Celery 是什么? 官网 Celery 是一个由 Python 编写的简单.灵活.可靠的用来处理大量信息的分布式系统,它同时提供操作和维护分布式系统所需的工具 ...
- Delphi 7的特点
- 深入理解JAVA虚拟机 虚拟机字节码执行引擎
执行引擎 执行引擎是java虚拟机的重要组成部分.它的作用是接收字节码,解析字节码,执行并输出执行结果. 虚拟机是相对于物理机的概念,物理机的执行引擎是直接建立在处理器.寄存器.指令集和操作系统的层面 ...