Java数据结构之算法时间度
1.度量一个程序(算法)执行时间的两种方法
1)事后统计的方法
这种方法可行, 但是有两个问题:一是要想对设计的算法的运行性能进行评测,需要实际运行该程序;二是所得时间的统计量依赖于计算机的硬件、软件等环境因素, 这种方式,要在同一台计算机的相同状态下运行,才能比较那个算法速度更快。
2)事前估算的方法
通过分析某个算法的时间复杂度来判断哪个算法更优。
2.时间频度
基本介绍:一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
举例说明:比如计算1-100所有数字之和,我们设计两种算法:
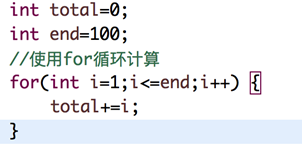
T(n) = n + 1 (加1是因为最后要多做一次i <= end判断)

T(n) = 1
3.时间频度举例说明
1)忽略常数项
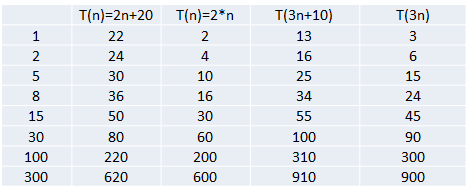
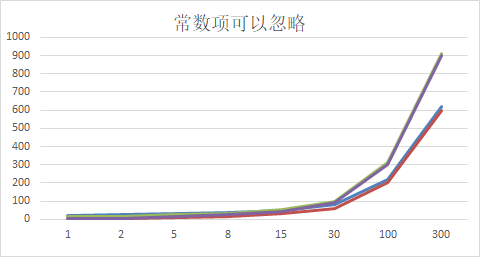
结论:
2n+20 和 2n 随着n 变大,执行曲线无限接近, 20可以忽略
3n+10 和 3n 随着n 变大,执行曲线无限接近, 10可以忽略
2)忽略低次项
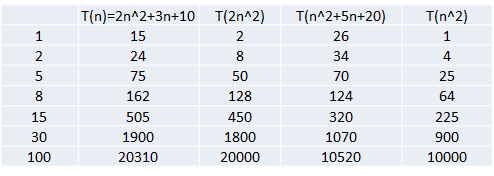
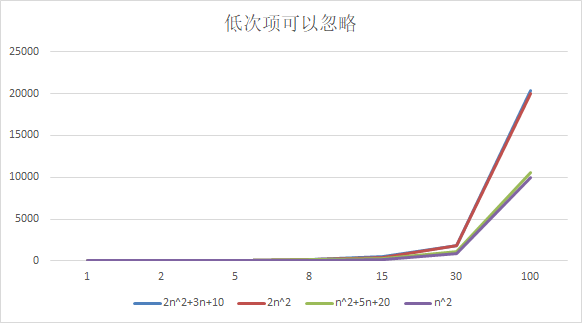
结论:
2n^2+3n+10 和 2n^2 随着n 变大, 执行曲线无限接近, 可以忽略 3n+10
n^2+5n+20 和 n^2 随着n 变大,执行曲线无限接近, 可以忽略 5n+20
3)忽略系数(2次方可忽略,3次方不可以)
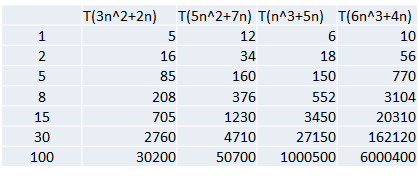
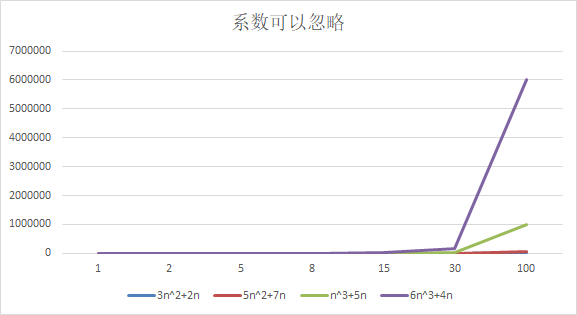
结论:
随着n值变大,5n^2+7n 和 3n^2 + 2n ,执行曲线重合, 说明 这种情况下, 5和3可以忽略。
而n^3+5n 和 6n^3+4n ,执行曲线分离,说明多少次方是关键
4. 时间复杂度
1)一般情况下,算法中的基本操作语句的重复执行次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n) / f(n) 的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作 T(n)=O( f(n) ),称O( f(n) ) 为算法的渐进时间复杂度,简称时间复杂度。
2)T(n) 不同,但时间复杂度可能相同。 如:T(n)=n²+7n+6 与 T(n)=3n²+2n+2 它们的T(n) 不同,但时间复杂度相同,都为O(n²)。(常数项、低次项、平方系数可忽略)
3)计算时间复杂度的方法:
用常数1代替运行时间中的所有加法常数 T(n)=n²+7n+6 => T(n)=n²+7n+1
修改后的运行次数函数中,只保留最高阶项 T(n)=n²+7n+1 => T(n) = n²
去除最高阶项的系数 T(n) = n² => T(n) = n² => O(n²)
5. 常见的时间复杂度
- 常数阶O(1):只要是没有循环等,无论代码执行了多少行
- 对数阶O(log2n):求2的多少次方为n执行的次数(n个数二分查找log2n次)默认情况下logN都是以2为底
- 线性阶O(n):循环里面的代码会执行n遍
- 线性对数阶O(nlog2n):将对数阶复杂度的代码循环n遍
- 平方阶O(n2):把 O(n) 的代码再嵌套循环一遍
- 立方阶O(n3):相当于三层n循环
- k次方阶O(nk):相当于k层n循环
- 指数阶O(2n)
6. 最优解:先保证时间复杂度最优,再保证空间复杂度最优
说明:
常见的算法时间复杂度由小到大依次为:Ο(1)<Ο(log2n)<Ο(n)<Ο(nlog2n)<Ο(n2)<Ο(n3)< Ο(nk) <Ο(2n) < O(n!),随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低
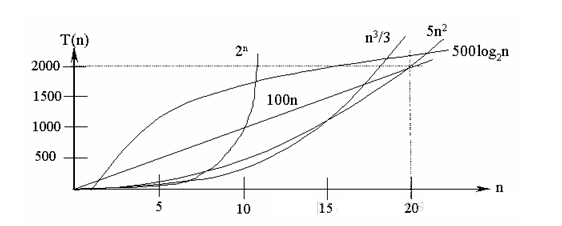
从图中可见,我们应该尽可能避免使用指数阶的算法
1)常数阶O(1):
无论代码执行了多少行,只要是没有循环等复杂结构,那这个代码的时间复杂度就都是O(1)
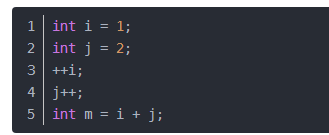
2)对数阶O(log2n)


说明:在while循环里面,每次都将 i 乘以 2,乘完之后,i 距离 n 就越来越近了。假设循环x次之后,i 就大于 2 了,此时这个循环就退出了,也就是说 2 的 x 次方等于 n,那么 x = log2n也就是说当循环 log2n 次以后,这个代码就结束了。因此这个代码的时间复杂度为:O(log2n) 。 O(log2n) 的这个2 时间上是根据代码变化的,i = i * 3 ,则是 O(log3n) .
3)线性阶O(n)
说明:for循环里面的代码会执行n遍,因此它消耗的时间是随着n的变化而变化的,因此这类代码都可以用O(n)来表示它的时间复杂度
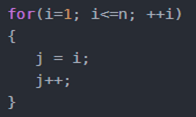
4)线性对数阶O(nlog2n):将对数阶复杂度的代码循环n遍
说明:线性对数阶O(nlogN) 其实非常容易理解,将时间复杂度为O(logn)的代码循环N遍的话,那么它的时间复杂度就是 n * O(logN),也就是了O(nlogN)
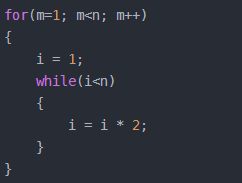
5)平方阶O(n2):把 O(n) 的代码再嵌套循环一遍

说明:这段代码其实就是嵌套了2层n循环,它的时间复杂度就是 O(n*n),即 O(n²) 如果将其中一层循环的n改成m,那它的时间复杂度就变成了 O(m*n)
6. 平均时间复杂度和最坏时间复杂度
平均时间复杂度:所有可能的输入实例均以等概率出现的情况下,该算法的运行时间。
最坏时间复杂度:最坏情况下的时间复杂度。一般讨论的时间复杂度均是最坏情况下的时间复杂度。
(这样做的原因是:最坏情况下的时间复杂度是算法在任何输入实例上运行时间的界限,这就保证了算法的运行时间不会比最坏情况更长。)
平均时间复杂度和最坏时间复杂度是否一致,和算法有关(如图:)。
各排序算法的时间复杂度对比:
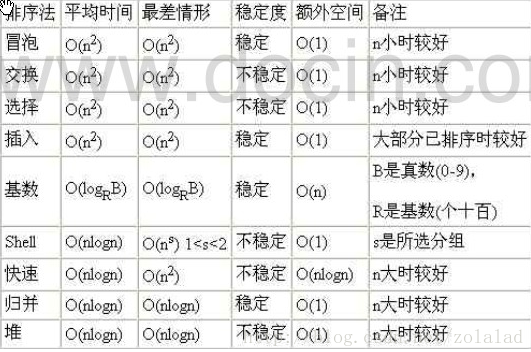
7.空间复杂度
类似于时间复杂度的讨论,一个算法的空间复杂度(Space Complexity)定义为该算法所耗费的存储空间,它也是问题规模n的函数。
空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的量度。有的算法需要占用的临时工作单元数与解决问题的规模n有关,它随着n的增大而增大,当n较大时,将占用较多的存储单元,例如快速排序和归并排序算法就属于这种情况。
在做算法分析时,主要讨论的是时间复杂度。从用户使用体验上看,更看重的程序执行的速度。一些缓存产品(redis, memcache)和算法(基数排序)本质就是用空间换时间。
Java数据结构之算法时间度的更多相关文章
- Java数据结构和算法(四)赫夫曼树
Java数据结构和算法(四)赫夫曼树 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 赫夫曼树又称为最优二叉树,赫夫曼树的一个 ...
- Java数据结构和算法 - 二叉树
前言 数据结构可划分为线性结构.树型结构和图型结构三大类.前面几篇讨论了数组.栈和队列.链表都是线性结构.树型结构中每个结点只允许有一个直接前驱结点,但允许有一个以上直接后驱结点.树型结构有树和二叉树 ...
- Java数据结构和算法(十四)——堆
在Java数据结构和算法(五)——队列中我们介绍了优先级队列,优先级队列是一种抽象数据类型(ADT),它提供了删除最大(或最小)关键字值的数据项的方法,插入数据项的方法,优先级队列可以用有序数组来实现 ...
- Java数据结构和算法(九)——高级排序
春晚好看吗?不存在的!!! 在Java数据结构和算法(三)——冒泡.选择.插入排序算法中我们介绍了三种简单的排序算法,它们的时间复杂度大O表示法都是O(N2),如果数据量少,我们还能忍受,但是数据量大 ...
- Java数据结构和算法 - 堆
堆的介绍 Q: 什么是堆? A: 这里的“堆”是指一种特殊的二叉树,不要和Java.C/C++等编程语言里的“堆”混淆,后者指的是程序员用new能得到的计算机内存的可用部分 A: 堆是有如下特点的二叉 ...
- Java数据结构和算法 - 高级排序
希尔排序 Q: 什么是希尔排序? A: 希尔排序因计算机科学家Donald L.Shell而得名,他在1959年发现了希尔排序算法. A: 希尔排序基于插入排序,但是增加了一个新的特性,大大地提高了插 ...
- Java数据结构和算法 - 递归
三角数字 Q: 什么是三角数字? A: 据说一群在毕达哥拉斯领导下工作的古希腊的数学家,发现了在数学序列1,3,6,10,15,21,……中有一种奇特的联系.这个数列中的第N项是由第N-1项加N得到的 ...
- Java数据结构和算法 - 栈和队列
Q: 栈.队列与数组的区别? A: 本篇主要涉及三种数据存储类型:栈.队列和优先级队列,它与数组主要有如下三个区别: A: (一)程序员工具 数组和其他的结构(栈.队列.链表.树等等)都适用于数据库应 ...
- Java数据结构和算法 - 简单排序
Q: 冒泡排序? A: 1) 比较相邻的元素.如果第一个比第二个大,就交换它们两个; 2) 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对.在这一点,最后的元素应该会是最大的数; 3) 针 ...
随机推荐
- Hadoop 开发环境虚拟机搭建
软件下载: VMware软件: 链接:https://pan.baidu.com/s/1gWinLJpfWdAQ8AyEkZxpfg 密码:i2ap 下载Ubuntu 镜像文件; 链接:https:/ ...
- 京东供应链模式TC转运流程
TC转运分上门提货和自己送货到网点 上门提货是TC委托第三方货运到商家提货,他们没有装货义务,需要商家自己装货等问题 上门提货简要流程: 采购单创建 商家打单打包出库(自己公司内部建单发货) TC预约 ...
- 【NOIP2016提高A组集训第14场11.12】随机游走
题目 YJC最近在学习图的有关知识.今天,他遇到了这么一个概念:随机游走.随机游走指每次从相邻的点中随机选一个走过去,重复这样的过程若干次.YJC很聪明,他很快就学会了怎么跑随机游走.为了检验自己是不 ...
- js支持中文的hex编码 bin2hex (utf-8)
背景: 最近对接接口的时候需要将请求参数转为16进制,因此研究了下这个bin2hex.在js中转16进制 使用的是: str.charCodeAt(i).toString(16); 在遇到中文的时候编 ...
- vmware哪个版本好用
这个问题要根据你的物理机操作系统而定,如果你电脑是xp,就选择vmw7.1.6:如果你电脑是win7,win8,win8.1,就选择vmw10.0.1.不要去理会vmw8.vmw9这些都是vmw10的 ...
- ansible-乱
工作机制:ssh 无客户端 工作方式: 1,CMDB 2,公有云私有云API 3,使用ad-hoc 4,ansible-playbook ansible 执行命令,底层调用传输连接模块,将命令或文件传 ...
- POJ 1182 食物链 (带权并查集 && 向量偏移)
题意 : 中文题就不说题意了…… 分析 : 通过普通并查集的整理归类, 能够单纯地知道某些元素是否在同一个集合内.但是题目不仅只有种类之分, 还有种类之间的关系, 即同类以及吃与被吃, 而且重点是题目 ...
- Scrapy终端(Scrapy shell)
1.介绍文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/topics/shell.html# 2.终端的启用方式:scrapy shell url u ...
- 论文阅读:Elastic Scaling of Stateful Network Functions
摘要: 弹性伸缩是NFV的核心承诺,但在实际应用中却很难实现.出现这种困难的原因是大多数网络函数(NFS)是有状态的,并且这种状态需要在NF实例之间共享.在满足NFS上的吞吐量和延迟要求的同时实现状态 ...
- Python3学习笔记(八):集合
集合(set)是一种可变的无序的不重复的数据类型 要创建集合,需要将所有项(元素)放在花括号({})内,以逗号(,)分隔. >>> s = {'p','y','t','h','o', ...