浅谈Manacher算法
Manacher
manacher是一种\(O(n)\)求最长回文子串的算法,俗称马拉车(滑稽)
直接步入正题
首先可以知道的是:每一个回文串都有自己的对称中心,相应的也有自己的最大延伸长度(可以称之为“半径”)
我们设\(rad[i]\)表示以\(i\)为中心的回文子串的半径,那么只需要知道所有的\(rad[i]\)就可以求出最长回文子串了
从\(1\)到\(n\)枚举\(i\),求解\(rad[i]\)
设当前已经求到了\(rad[k]\),设前\(k-1\)个数中\(rad[i]+i\)(即右端点)最大的数为\(mid\),令\(r=mid+rad[mid]\)
那么可以证明一个点\(i\)关于\(mid\)的对称点是\(2\times mid-i\)(两点距离公式)
opt1:如果\(k\leq r\)
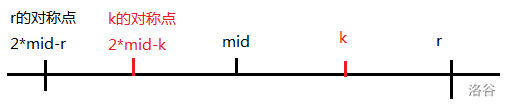
方便起见,令\(j=2\times mid-k\)
1.若\(j-rad[j]>mid-rad[mid]\),即以\(j\)点为中心的最长回文子串的左端点在以\(mid\)为中心的最长回文子串的左端点右边,则\(rad[i]\)可以直接由\(rad[j]\)转移过来(因为\(2\times mid-r\)$mid$和$mid$\(r\)是对称的,所以\(k\)的半径和\(j\)的半径是一样的),即\(rad[i]=rad[j]\)
2.若\(j-rad[j]\leq mid-rad[mid]\),则\(rad[k]\)至少是\(r-k\)。接下来再暴力延伸,顺便更新\(mid\)和\(r\)
opt2:如果\(k>r\)
直接暴力延伸,顺便更新\(mid\)和\(r\)
可以发现每次暴力延伸的时候,暴力延伸多少,\(r\)也会变化多少,且\(r\)是递增的且不超过\(n\)的数
关于复杂度:
由于每一个字符最多只会被遍历一次,所以复杂度是\(O(n)\)的
实现细节:
1.由于长度为偶数的回文串对称中心并不能实际找到,所以在两个字符之间插入#。这样不会影响答案,并且可以解决这个问题
2.对于不同情况的相似之处可以合并到一起来降低码量,如op1.1的直接转移和opt1.2的转移等
3.不要忘了更新\(mid\)和\(r\)
4.注意下标
代码:
#include<bits/stdc++.h>
using namespace std;
char cString[22000005];
int iRad[22000005];
int iLen,iAns;
void read()
{
char c = getchar();
cString[0] = '|', cString[++iLen] = '#';
while(c < 'a' || c > 'z') c = getchar();
while(c >= 'a'&& c <= 'z') cString[++iLen] = c, cString[++iLen] = '#', c = getchar();
}
int main()
{
read();//读入
for(int i = 1, mid = 0, r = 0; i <= iLen; i++)
{
if(i <= r) iRad[i] = min(iRad[mid * 2 - i], r - i + 1);//opt1
while(cString[i - iRad[i]] == cString[i + iRad[i]]) ++iRad[i];//opt1.2,opt2 尝试暴力延伸
if(i + iRad[i] > r) r = i + iRad[i] - 1, mid = i;//更新mid和r
if(iRad[i] > iAns) iAns = iRad[i];//更新答案
}
printf("%d", iAns-1);
}
浅谈Manacher算法的更多相关文章
- 浅谈Manacher算法与扩展KMP之间的联系
首先,在谈到Manacher算法之前,我们先来看一个小问题:给定一个字符串S,求该字符串的最长回文子串的长度.对于该问题的求解.网上解法颇多.时间复杂度也不尽同样,这里列述几种常见的解法. 解法一 ...
- 【字符串算法2】浅谈Manacher算法
[字符串算法1] 字符串Hash(优雅的暴力) [字符串算法2]Manacher算法 [字符串算法3]KMP算法 这里将讲述 字符串算法2:Manacher算法 问题:给出字符串S(限制见后)求出最 ...
- 浅谈分词算法(5)基于字的分词方法(bi-LSTM)
目录 前言 目录 循环神经网络 基于LSTM的分词 Embedding 数据预处理 模型 如何添加用户词典 前言 很早便规划的浅谈分词算法,总共分为了五个部分,想聊聊自己在各种场景中使用到的分词方法做 ...
- 浅谈分词算法(4)基于字的分词方法(CRF)
目录 前言 目录 条件随机场(conditional random field CRF) 核心点 线性链条件随机场 简化形式 CRF分词 CRF VS HMM 代码实现 训练代码 实验结果 参考文献 ...
- 浅谈分词算法(3)基于字的分词方法(HMM)
目录 前言 目录 隐马尔可夫模型(Hidden Markov Model,HMM) HMM分词 两个假设 Viterbi算法 代码实现 实现效果 完整代码 参考文献 前言 在浅谈分词算法(1)分词中的 ...
- 浅谈分词算法基于字的分词方法(HMM)
前言 在浅谈分词算法(1)分词中的基本问题我们讨论过基于词典的分词和基于字的分词两大类,在浅谈分词算法(2)基于词典的分词方法文中我们利用n-gram实现了基于词典的分词方法.在(1)中,我们也讨论了 ...
- 【字符串算法3】浅谈KMP算法
[字符串算法1] 字符串Hash(优雅的暴力) [字符串算法2]Manacher算法 [字符串算法3]KMP算法 这里将讲述 [字符串算法3]KMP算法 Part1 理解KMP的精髓和思想 其实KM ...
- 浅谈Manacher
\(Manacher\)是由一个叫做\(Manacher\)的人发明的能在\(O(n)\)时间内找出一个字符串长度最长的回文子串的算法. 由于偶回文串形如\(abba\)这样的不好找对称中心,所以我们 ...
- 浅谈Tarjan算法
从这里开始 预备知识 两个数组 Tarjan 算法的应用 求割点和割边 求点-双连通分量 求边-双连通分量 求强连通分量 预备知识 设无向图$G_{0} = (V_{0}, E_{0})$,其中$V_ ...
随机推荐
- vue-cli常用配置
官方配置表:https://cli.vuejs.org/zh/config/#publicpath 1.vue inspect > output.js 将配置按webpack.config.js ...
- vscode常用插件列表
vscode插件 备注 Markdown PDF 把markdown文件转换成别的文件 Markdown TOC markdown文件目录生成 PHP Debug PHP调试 PHP Intenlli ...
- symfony2学习笔记——控制器
//获取get过来的参数 $val = $request->query->get('aaa'); //获取post过来的参数 //$val = $request->request-& ...
- linux命令详解——yum
1.如果不知道确切名字可以:rpm -qa|grep pkgname 2.查看软件安装的文件:rpm -qpl pkgname 3.如果不知道提供某个软件的包是叫什么,可以使用类似下面的写法: yum ...
- 51单片机通过ESP8266模块与手机进行通讯(单片机)
相关连接和资料下载: 个人博客 资料下载 Step1:配置ESP8266 通过USB转TTL模块把ESP8266模块和电脑连接起来,如图: 把ESP8266模块的VCC,GND,CH_PD,UTXD, ...
- 详解thinkphp+redis+队列的实现代码
1,安装Redis,根据自己的PHP版本安装对应的redis扩展(此步骤简单的描述一下) 1.1,安装 php_igbinary.dll,php_redis.dll扩展此处需要注意你的php版本如图: ...
- 记录一下RAC的使用
1 常规的对数组的操作,包括遍历.刷选.映射.替换 // 遍历 NSArray * array = @["]; [array.rac_sequence.signal subscribeNe ...
- SpringBoot项目多模块打包与部署【pom文件问题】
[bean的pom] [user的pom] 特别注意,user模块因为有返回jsp页面和web相关,所以需要加入web依赖. chapter23 com.yuqiyu 1.0.0 4.0.0 com. ...
- MySQL第二次安装随笔
找到之前的MySQL的安装包,重新安装MySQL. 1.设置环境变量,win10的可以右键此电脑-属性,在系统变量Path中添加mysql文件bin的路径 2.修改配置文件mydefault.ini( ...
- poj2018 Best Cow Fences[二分答案or凸包优化]
题目. 首先暴力很好搞,但是优化的话就不会了.放弃QWQ. 做法1:二分答案 然后发现平均值是$ave=\frac{sum}{len}$,这种形式似乎可以二分答案?把$len$移到左边. 于是二分$a ...