RabbitMq--4--集群(转载)
RabbitMQ消息服务用户手册
1 基础知识
1.1 集群总体概述
Rabbitmq Broker集群是多个erlang节点的逻辑组,每个节点运行Rabbitmq应用,他们之间共享用户、虚拟主机、队列、exchange、绑定和运行时参数。
1.2 集群复制信息
除了message queue(存在一个节点,从其他节点都可见、访问该队列,要实现queue的复制就需要做queue的HA)之外,任何一个Rabbitmq broker上的所有操作的data和state都会在所有的节点之间进行复制。
1.3 集群运行前提
1、集群所有节点必须运行相同的erlang及Rabbitmq版本。
2、hostname解析,节点之间通过域名相互通信,本文为3个node的集群,采用配置hosts的形式。
1.4 集群互通方式
1、集群所有节点必须运行相同的erlang及Rabbitmq版本hostname解析,节点之间通过域名相互通信,本文为3个node的集群,采用配置hosts的形式。
1.5 端口及其用途
1、5672 客户端连接端口。
2、15672 web管控台端口。
3、25672 集群通信端口。
1.6 集群配置方式
通过rabbitmqctl手工配置的方式。
1.7 集群故障处理
1、rabbitmq broker集群允许个体节点宕机。
2、对应集群的的网络分区问题(network partitions)集群推荐用于LAN环境,不适用WAN环境;要通过WAN连接broker,Shovel or Federation插件是最佳解决方案(Shovel or Federation不同于集群:注Shovel为中心服务远程异步复制机制,稍后会有介绍)。
1.8 节点运行模式
为保证数据持久性,目前所有node节点跑在disk模式,如果今后压力大,需要提高性能,考虑采用ram模式。
1.9 集群认证方式
通过Erlang Cookie,相当于共享秘钥的概念,长度任意,只要所有节点都一致即可。rabbitmq server在启动的时候,erlang VM会自动创建一个随机的cookie文件。cookie文件的位置: /var/lib/rabbitmq/.erlang.cookie 或者/root/.erlang.cookie。我们的为保证cookie的完全一致,采用从一个节点copy的方式,实现各个节点的cookie文件一致。
2 集群搭建
2.1 集群节点安装
1、安装依赖包
PS:安装rabbitmq所需要的依赖包
yum install build-essential openssl openssl-devel unixODBC unixODBC-devel make gcc gcc-c++ kernel-devel m4 ncurses-devel tk tc xz
2、下载安装包
wget www.rabbitmq.com/releases/erlang/erlang-18.3-.el7.centos.x86_64.rpm wget http://repo.iotti.biz/CentOS/7/x86_64/socat-1.7.3.2-5.el7.lux.x86_64.rpm wget www.rabbitmq.com/releases/rabbitmq-server/v3.6.5/rabbitmq-server-3.6.-.noarch.rpm
3、安装服务命令
rpm -ivh erlang-18.3-.el7.centos.x86_64.rpm rpm -ivh socat-1.7.3.2-.el7.lux.x86_64.rpm rpm -ivh rabbitmq-server-3.6.-.noarch.rpm
4、修改集群用户与连接心跳检测
注意修改vim /usr/lib/rabbitmq/lib/rabbitmq_server-3.6./ebin/rabbit.app文件 修改:loopback_users 中的 <<"guest">>,只保留guest 修改:heartbeat 为1
5、安装管理插件
//首先启动服务 /etc/init.d/rabbitmq-server start stop status restart //查看服务有没有启动: lsof -i:5672 rabbitmq-plugins enable rabbitmq_management //可查看管理端口有没有启动: lsof -i:15672 或者 netstat -tnlp|grep 15672
6、服务指令
/etc/init.d/rabbitmq-server start stop status restart 验证单个节点是否安装成功:http://192.168.11.71:15672/ Ps:以上操作三个节点(、、)同时进行操作
PS:选择76、77、78任意一个节点为Master(这里选择76为Master),也就是说我们需要把76的Cookie文件同步到77、78节点上去,进入/var/lib/rabbitmq目录下,把/var/lib/rabbitmq/.erlang.cookie文件的权限修改为777,原来是400;然后把.erlang.cookie文件copy到各个节点下;最后把所有cookie文件权限还原为400即可。
2.2 文件同步步骤
/etc/init.d/rabbitmq-server stop //进入目录修改权限;远程copy77、78节点,比如: scp /var/lib/rabbitmq/.erlang.cookie 到192.168.11.77和192.168.11.78中
2.3 组成集群步骤
1、停止MQ服务
PS:我们首先停止3个节点的服务
rabbitmqctl stop
PS:接下来我们就可以使用集群命令,配置76、77、78为集群模式,3个节点(76、77、78)执行启动命令,后续启动集群使用此命令即可。
rabbitmq-server -detached
2、组成集群操作
//注意做这个步骤的时候:需要配置/etc/hosts 必须相互能够寻址到 bhz77:rabbitmqctl stop_app bhz77:rabbitmqctl join_cluster --ram rabbit@bhz76 bhz77:rabbitmqctl start_app bhz78:rabbitmqctl stop_app bhz78:rabbitmqctl join_cluster rabbit@bhz76 bhz78:rabbitmqctl start_app //在另外其他节点上操作要移除的集群节点 rabbitmqctl forget_cluster_node rabbit@bhz24
3、slave加入集群操作(重新加入集群也是如此,以最开始的主节点为加入节点)
4、修改集群名称
PS:修改集群名称(默认为第一个node名称):
rabbitmqctl set_cluster_name rabbitmq_cluster1
5、查看集群状态
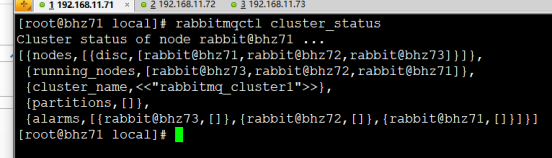
PS:最后在集群的任意一个节点执行命令:查看集群状态
rabbitmqctl cluster_status
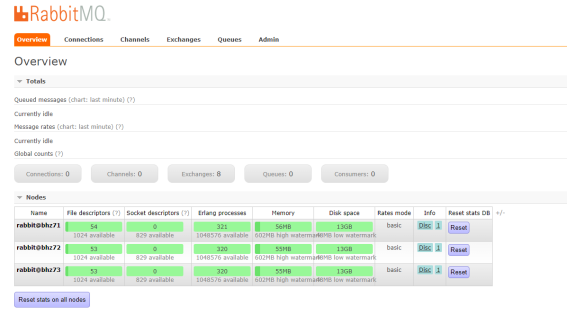
6、管控台界面
PS: 访问任意一个管控台节点:http://192.168.11.71:15672 如图所示
2.4 配置镜像队列
PS:设置镜像队列策略(在任意一个节点上执行)
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
PS:将所有队列设置为镜像队列,即队列会被复制到各个节点,各个节点状态一致,RabbitMQ高可用集群就已经搭建好了,我们可以重启服务,查看其队列是否在从节点同步。
2.5 安装Ha-Proxy
1、Haproxy简介
HAProxy是一款提供高可用性、负载均衡以及基于TCP和HTTP应用的代理软件,HAProxy是完全免费的、借助HAProxy可以快速并且可靠的提供基于TCP和HTTP应用的代理解决方案。
HAProxy适用于那些负载较大的web站点,这些站点通常又需要会话保持或七层处理。
HAProxy可以支持数以万计的并发连接,并且HAProxy的运行模式使得它可以很简单安全的整合进架构中,同时可以保护web服务器不被暴露到网络上。
2、Haproxy安装
PS:79、80节点同时安装Haproxy,下面步骤统一
//下载依赖包 yum install gcc vim wget //下载haproxy wget http://www.haproxy.org/download/1.6/src/haproxy-1.6.5.tar.gz //解压 tar -zxvf haproxy-1.6..tar.gz -C /usr/local //进入目录、进行编译、安装 cd /usr/local/haproxy-1.6. make TARGET=linux31 PREFIX=/usr/local/haproxy make install PREFIX=/usr/local/haproxy mkdir /etc/haproxy //赋权 groupadd -r -g haproxy useradd -g haproxy -r -s /sbin/nologin -u haproxy //创建haproxy配置文件 touch /etc/haproxy/haproxy.cfg
3、Haproxy配置
PS:haproxy 配置文件haproxy.cfg详解
vim /etc/haproxy/haproxy.cfg
#logging options
global
log 127.0.0.1 local0 info
maxconn
chroot /usr/local/haproxy
uid
gid
daemon
quiet
nbproc
pidfile /var/run/haproxy.pid
defaults
log global
#使用4层代理模式,”mode http”为7层代理模式
mode tcp
#if you set mode to tcp,then you nust change tcplog into httplog
option tcplog
option dontlognull
retries
option redispatch
maxconn
contimeout 5s
##客户端空闲超时时间为 60秒 则HA 发起重连机制
clitimeout 60s
##服务器端链接超时时间为 15秒 则HA 发起重连机制
srvtimeout 15s
#front-end IP for consumers and producters
listen rabbitmq_cluster
bind 0.0.0.0:
#配置TCP模式
mode tcp
#balance url_param userid
#balance url_param session_id check_post
#balance hdr(User-Agent)
#balance hdr(host)
#balance hdr(Host) use_domain_only
#balance rdp-cookie
#balance leastconn
#balance source //ip
#简单的轮询
balance roundrobin
#rabbitmq集群节点配置 #inter 每隔五秒对mq集群做健康检查, 2次正确证明服务器可用,2次失败证明服务器不可用,并且配置主备机制
server bhz76 192.168.11.76: check inter rise fall
server bhz77 192.168.11.77: check inter rise fall
server bhz78 192.168.11.78: check inter rise fall
#配置haproxy web监控,查看统计信息
listen stats
bind 192.168.11.79:
mode http
option httplog
stats enable
#设置haproxy监控地址为http://localhost:8100/rabbitmq-stats
stats uri /rabbitmq-stats
stats refresh 5s
4、启动haproxy
/usr/local/haproxy/sbin/haproxy -f /etc/haproxy/haproxy.cfg //查看haproxy进程状态 ps -ef | grep haproxy
5、访问haproxy
PS:访问如下地址可以对rmq节点进行监控:http://192.168.1.27:8100/rabbitmq-stats
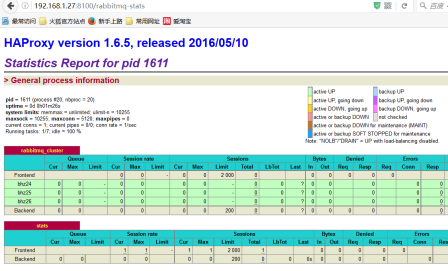
6、关闭haproxy
killall haproxy ps -ef | grep haproxy
2.6 安装KeepAlived
1、Keepalived简介
Keepalived,它是一个高性能的服务器高可用或热备解决方案,Keepalived主要来防止服务器单点故障的发生问题,可以通过其与Nginx、Haproxy等反向代理的负载均衡服务器配合实现web服务端的高可用。Keepalived以VRRP协议为实现基础,用VRRP协议来实现高可用性(HA).VRRP(Virtual Router Redundancy Protocol)协议是用于实现路由器冗余的协议,VRRP协议将两台或多台路由器设备虚拟成一个设备,对外提供虚拟路由器IP(一个或多个)。
2、Keepalived安装
PS:下载地址:http://www.keepalived.org/download.html
//安装所需软件包 yum install -y openssl openssl-devel //下载 wget http://www.keepalived.org/software/keepalived-1.2.18.tar.gz //解压、编译、安装 tar -zxvf keepalived-1.2..tar.gz -C /usr/local/ cd keepalived-1.2./ && ./configure --prefix=/usr/local/keepalived make && make install //将keepalived安装成Linux系统服务,因为没有使用keepalived的默认安装路径(默认路径:/usr/local),安装完成之后,需要做一些修改工作 //首先创建文件夹,将keepalived配置文件进行复制: mkdir /etc/keepalived cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/ //然后复制keepalived脚本文件: cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/ cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/ ln -s /usr/local/sbin/keepalived /usr/sbin/ ln -s /usr/local/keepalived/sbin/keepalived /sbin/ //可以设置开机启动:chkconfig keepalived on,到此我们安装完毕! chkconfig keepalived on
3、Keepalived配置
PS:修改keepalived.conf配置文件
vim /etc/keepalived/keepalived.conf
PS: 79节点(Master)配置如下
! Configuration File for keepalived
global_defs {
router_id bhz79 ##标识节点的字符串,通常为hostname
}
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh" ##执行脚本位置
interval ##检测时间间隔
weight - ##如果条件成立则权重减20
}
vrrp_instance VI_1 {
state MASTER ## 主节点为MASTER,备份节点为BACKUP
interface eth0 ## 绑定虚拟IP的网络接口(网卡),与本机IP地址所在的网络接口相同(我这里是eth0)
virtual_router_id ## 虚拟路由ID号(主备节点一定要相同)
mcast_src_ip 192.168.11.79 ## 本机ip地址
priority ##优先级配置(-254的值)
nopreempt
advert_int ## 组播信息发送间隔,俩个节点必须配置一致,默认1s
authentication { ## 认证匹配
auth_type PASS
auth_pass bhz
}
track_script {
chk_haproxy
}
virtual_ipaddress {
192.168.11.70 ## 虚拟ip,可以指定多个
}
}
PS: 80节点(backup)配置如下
! Configuration File for keepalived
global_defs {
router_id bhz80 ##标识节点的字符串,通常为hostname
}
vrrp_script chk_haproxy {
script "/etc/keepalived/haproxy_check.sh" ##执行脚本位置
interval ##检测时间间隔
weight - ##如果条件成立则权重减20
}
vrrp_instance VI_1 {
state BACKUP ## 主节点为MASTER,备份节点为BACKUP
interface eno16777736 ## 绑定虚拟IP的网络接口(网卡),与本机IP地址所在的网络接口相同(我这里是eno16777736)
virtual_router_id ## 虚拟路由ID号(主备节点一定要相同)
mcast_src_ip 192.168.11.80 ## 本机ip地址
priority ##优先级配置(-254的值)
nopreempt
advert_int ## 组播信息发送间隔,俩个节点必须配置一致,默认1s
authentication { ## 认证匹配
auth_type PASS
auth_pass bhz
}
track_script {
chk_haproxy
}
virtual_ipaddress {
192.168.1.70 ## 虚拟ip,可以指定多个
}
}
4、执行脚本编写
PS:添加文件位置为/etc/keepalived/haproxy_check.sh(79、80两个节点文件内容一致即可)
#!/bin/bash
COUNT=`ps -C haproxy --no-header |wc -l`
if [ $COUNT -eq ];then
/usr/local/haproxy/sbin/haproxy -f /etc/haproxy/haproxy.cfg
sleep
if [ `ps -C haproxy --no-header |wc -l` -eq ];then
killall keepalived
fi
fi
5、执行脚本赋权
PS:haproxy_check.sh脚本授权,赋予可执行权限.
chmod +x /etc/keepalived/haproxy_check.sh
6、启动keepalived
PS:当我们启动俩个haproxy节点以后,我们可以启动keepalived服务程序:
//启动两台机器的keepalived service keepalived start | stop | status | restart //查看状态 ps -ef | grep haproxy ps -ef | grep keepalived
7、高可用测试
PS:vip在27节点上
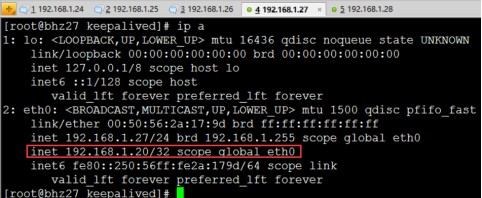
PS:27节点宕机测试:停掉27的keepalived服务即可。

PS:查看28节点状态:我们发现VIP漂移到了28节点上,那么28节点的haproxy可以继续对外提供服务!

2.7 集群配置文件
创建如下配置文件位于:/etc/rabbitmq目录下(这个目录需要自己创建)
环境变量配置文件:rabbitmq-env.conf
配置信息配置文件:rabbitmq.config(可以不创建和配置,修改)
rabbitmq-env.conf配置文件:
---------------------------------------关键参数配置-------------------------------------------
RABBITMQ_NODE_IP_ADDRESS=本机IP地址
RABBITMQ_NODE_PORT=5672
RABBITMQ_LOG_BASE=/var/lib/rabbitmq/log
RABBITMQ_MNESIA_BASE=/var/lib/rabbitmq/mnesia
配置参考参数如下:
RABBITMQ_NODENAME=FZTEC-240088 节点名称
RABBITMQ_NODE_IP_ADDRESS=127.0.0.1 监听IP
RABBITMQ_NODE_PORT=5672 监听端口
RABBITMQ_LOG_BASE=/data/rabbitmq/log 日志目录
RABBITMQ_PLUGINS_DIR=/data/rabbitmq/plugins 插件目录
RABBITMQ_MNESIA_BASE=/data/rabbitmq/mnesia 后端存储目录
更详细的配置参见: http://www.rabbitmq.com/configure.html#configuration-file
配置文件信息修改:
/usr/lib/rabbitmq/lib/rabbitmq_server-3.6.4/ebin/rabbit.app和rabbitmq.config配置文件配置任意一个即可,我们进行配置如下:
vim /usr/lib/rabbitmq/lib/rabbitmq_server-3.6.4/ebin/rabbit.app
-------------------------------------关键参数配置----------------------------------------
tcp_listerners 设置rabbimq的监听端口,默认为[5672]。
disk_free_limit 磁盘低水位线,若磁盘容量低于指定值则停止接收数据,默认值为{mem_relative, 1.0},即与内存相关联1:1,也可定制为多少byte.
vm_memory_high_watermark,设置内存低水位线,若低于该水位线,则开启流控机制,默认值是0.4,即内存总量的40%。
hipe_compile 将部分rabbimq代码用High Performance Erlang compiler编译,可提升性能,该参数是实验性,若出现erlang vm segfaults,应关掉。
force_fine_statistics, 该参数属于rabbimq_management,若为true则进行精细化的统计,但会影响性能
------------------------------------------------------------------------------------------
更详细的配置参见:http://www.rabbitmq.com/configure.html
3 Stream调研
3.1 Stream简介
Spring Cloud Stream是创建消息驱动微服务应用的框架。Spring Cloud Stream是基于spring boot创建,用来建立单独的/工业级spring应用,使用spring integration提供与消息代理之间的连接。
本文提供不同代理中的中间件配置,介绍了持久化发布订阅机制,以及消费组以及分割的概念。
将注解@EnableBinding加到应用上就可以实现与消息代理的连接,@StreamListener注解加到方法上,使之可以接收处理流的事件。
3.2 官方参考文档
原版:
http://docs.spring.io/spring-cloud-stream/docs/current-SNAPSHOT/reference/htmlsingle/#_main_concepts
翻译:
http://blog.csdn.net/phyllisy/article/details/51352868
3.3 API操作手册
3.3.1 生产者示例
PS:生产者yml配置
spring:
cloud:
stream:
instanceCount:
bindings:
output_channel: #输出 生产者
group: queue- #指定相同的exchange-1和不同的queue 表示广播模式 #指定相同的exchange和相同的queue表示集群负载均衡模式
destination: exchange- # kafka:发布订阅模型里面的topic rabbitmq: exchange的概念(但是exchange的类型那里设置呢?)
binder: rabbit_cluster
binders:
rabbit_cluster:
type: rabbit
environment:
spring:
rabbitmq:
host: 192.168.1.27
port:
username: guest
password: guest
virtual-host: /
PS: Barista接口为自定义管道
package bhz.spring.cloud.stream;
import org.springframework.cloud.stream.annotation.Input;
import org.springframework.cloud.stream.annotation.Output;
import org.springframework.messaging.MessageChannel;
import org.springframework.messaging.SubscribableChannel;
/**
* <B>中文类名:</B><BR>
* <B>概要说明:</B><BR>
* 这里的Barista接口是定义来作为后面类的参数,这一接口定义来通道类型和通道名称。
* 通道名称是作为配置用,通道类型则决定了app会使用这一通道进行发送消息还是从中接收消息。
* @author bhz(Alienware)
* @since 2015年11月22日
*/
public interface Barista {
String INPUT_CHANNEL = "input_channel";
String OUTPUT_CHANNEL = "output_channel";
//注解@Input声明了它是一个输入类型的通道,名字是Barista.INPUT_CHANNEL,也就是position3的input_channel。这一名字与上述配置app2的配置文件中position1应该一致,表明注入了一个名字叫做input_channel的通道,它的类型是input,订阅的主题是position2处声明的mydest这个主题
@Input(Barista.INPUT_CHANNEL)
SubscribableChannel loginput();
//注解@Output声明了它是一个输出类型的通道,名字是output_channel。这一名字与app1中通道名一致,表明注入了一个名字为output_channel的通道,类型是output,发布的主题名为mydest。
@Output(Barista.OUTPUT_CHANNEL)
MessageChannel logoutput();
}
PS: 生产者消息投递
package bhz.spring.cloud.stream;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.stereotype.Service;
@Service
public class RabbitmqSender {
@Autowired
private Barista source;
// 发送消息
public String sendMessage(Object message){
try{
source.logoutput().send(MessageBuilder.withPayload(message).build());
System.out.println("发送数据:" + message);
}catch (Exception e){
e.printStackTrace();
}
return null;
}
}
PS: Spring Boot应用入口
package bhz.spring.cloud.stream;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.stream.annotation.EnableBinding;
@SpringBootApplication
@EnableBinding(Barista.class)
public class ProducerApplication {
public static void main(String[] args) {
SpringApplication.run(ProducerApplication.class, args);
}
}
3.3.2 消费者示例
PS:消费者yml配置
spring:
cloud:
stream:
instanceCount:
bindings:
input_channel: #输出 生产者
destination: exchange- # kafka:发布订阅模型里面的topic rabbitmq: exchange的概念(但是exchange的类型那里设置呢?)
group: queue- #指定相同的exchange-1和不同的queue 表示广播模式 #指定相同的exchange和相同的queue表示集群负载均衡模式
binder: rabbit_cluster
consumer:
concurrency:
rabbit:
bindings:
input_channel:
consumer:
transacted: true
txSize:
acknowledgeMode: MANUAL
durableSubscription: true
maxConcurrency:
recoveryInterval:
binders:
rabbit_cluster:
type: rabbit
environment:
spring:
rabbitmq:
host: 192.168.1.27
port:
username: guest
password: guest
virtual-host: /
PS: Barista接口为自定义管道
package bhz.spring.cloud.stream;
import org.springframework.cloud.stream.annotation.Input;
import org.springframework.cloud.stream.annotation.Output;
import org.springframework.messaging.MessageChannel;
import org.springframework.messaging.SubscribableChannel;
/**
* <B>中文类名:</B><BR>
* <B>概要说明:</B><BR>
* 这里的Barista接口是定义来作为后面类的参数,这一接口定义来通道类型和通道名称。
* 通道名称是作为配置用,通道类型则决定了app会使用这一通道进行发送消息还是从中接收消息。
* @author bhz(Alienware)
* @since 2015年11月22日
*/
public interface Barista {
String INPUT_CHANNEL = "input_channel";
String OUTPUT_CHANNEL = "output_channel";
//注解@Input声明了它是一个输入类型的通道,名字是Barista.INPUT_CHANNEL,也就是position3的input_channel。这一名字与上述配置app2的配置文件中position1应该一致,表明注入了一个名字叫做input_channel的通道,它的类型是input,订阅的主题是position2处声明的mydest这个主题
@Input(Barista.INPUT_CHANNEL)
SubscribableChannel loginput();
//注解@Output声明了它是一个输出类型的通道,名字是output_channel。这一名字与app1中通道名一致,表明注入了一个名字为output_channel的通道,类型是output,发布的主题名为mydest。
@Output(Barista.OUTPUT_CHANNEL)
MessageChannel logoutput();
}
PS: 消费者消息获取
package bhz.spring.cloud.stream;
import java.io.IOException;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.amqp.rabbit.support.CorrelationData;
import org.springframework.amqp.support.AmqpHeaders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.binding.ChannelBindingService;
import org.springframework.cloud.stream.config.ChannelBindingServiceConfiguration;
import org.springframework.cloud.stream.endpoint.ChannelsEndpoint;
import org.springframework.integration.channel.PublishSubscribeChannel;
import org.springframework.integration.channel.RendezvousChannel;
import org.springframework.messaging.Message;
import org.springframework.messaging.MessageChannel;
import org.springframework.messaging.SubscribableChannel;
import org.springframework.messaging.core.MessageReceivingOperations;
import org.springframework.messaging.core.MessageRequestReplyOperations;
import org.springframework.messaging.support.ChannelInterceptor;
import org.springframework.stereotype.Service;
import com.rabbitmq.client.Channel;
@EnableBinding(Barista.class)
@Service
public class RabbitmqReceiver {
@Autowired
private Barista source;
@StreamListener(Barista.INPUT_CHANNEL)
public void receiver( Message message) {
//广播通道
//PublishSubscribeChannel psc = new PublishSubscribeChannel();
//确认通道
//RendezvousChannel rc = new RendezvousChannel();
Channel channel = (com.rabbitmq.client.Channel) message.getHeaders().get(AmqpHeaders.CHANNEL);
Long deliveryTag = (Long) message.getHeaders().get(AmqpHeaders.DELIVERY_TAG);
System.out.println("Input Stream 1 接受数据:" + message);
try {
channel.basicAck(deliveryTag, false);
} catch (IOException e) {
e.printStackTrace();
}
}
}
PS: Spring Boot应用入口
package bhz.spring.cloud.stream;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@SpringBootApplication
@EnableBinding(Barista.class)
@EnableTransactionManagement
public class ConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(ConsumerApplication.class, args);
}
}
4.1 延迟队列插件4 制定扩展
#step1:upload the ‘rabbitmq_delayed_message_exchange-0.0.1.ez’ file:
https://github.com/rabbitmq/rabbitmq-delayed-message-exchange
http://www.rabbitmq.com/community-plugins.html
https://bintray.com/rabbitmq/community-plugins/rabbitmq_delayed_message_exchange/v3.6.x#files/
#step2:PUT Directory:
/usr/lib/rabbitmq/lib/rabbitmq_server-3.6.4/plugins
#step3:Then run the following command:
Start the rabbitmq cluster for command ## rabbitmq-server -detached
rabbitmq-plugins enable rabbitmq_delayed_message_exchange

访问地址:http://192.168.1.21:15672/#/exchanges,添加延迟队列

RabbitMq--4--集群(转载)的更多相关文章
- RabbitMQ入门教程(十四):RabbitMQ单机集群搭建
原文:RabbitMQ入门教程(十四):RabbitMQ单机集群搭建 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://b ...
- Rabbitmq关于集群节点功能的读书笔记
消息和队列可以指定是否持久化,如果指定持久化则会保存到硬盘上 ,不然只在内存里 普通集群模式下持久化的队列不能重建了 内存节点和磁盘节点的区别就是将元数据放在了内存还是硬盘,仅此而已,当在集群中声明队 ...
- 关于RabbitMQ分布式集群架构
RabbitMQ分布式集群架构和高可用性(HA) (一) 功能和原理 设计集群的目的 允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行 通过增加更多的节点来扩展消息通信的吞吐量 1 集群配 ...
- RabbitMQ之集群搭建
1.RabbitMQ集群模式RabbitMQ集群中节点包括内存节点(RAM).磁盘节点(Disk,消息持久化),集群中至少有一个Disk节点. 2.普通模式(默认) 对于普通模式,集群中 ...
- RabbitMQ (十三) 集群+单机搭建(window)
拜读了网上很多前辈的文章,对RabbitMQ的集群有了一点点认识. 好多文章都说到,RabbitMQ的集群分为普通集群和镜像集群,有的还加了两种:单机集群和主从集群. 我看来看去,看了半天,怎么感觉, ...
- 11.RabbitMQ单机集群
RabbitMQ集群设计用于完成两个目标:允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行,以及通过添加更多的节点来扩展消息通信的吞吐量. RabbitMQ会始终记录以下四种类型的内部元数 ...
- 部署rabbitMQ镜像集群实战测试
部署rabbitMQ镜像集群 版本信息 rabbit MQ: 3.8.5 Erlang: 官方建议最低21.3 推荐22.x 这里用的是23 环境准备 主机规划 主机 节点 172.16.14.3 磁 ...
- 安装rabbitmq以及集群配置
前言: (一些有用没用的唠叨,反正看了也不少肉,跳过也没啥) 情况是这样的:虚拟机.CentOS 6.5.免编译包安装rabbitmq集群,可不用连外网. 我原计划是安装在虚拟机上wyt1/wyt2/ ...
- RabbitMQ分布式集群架构和高可用性(HA)
(一) 功能和原理 设计集群的目的 允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行 通过增加更多的节点来扩展消息通信的吞吐量 1 集群配置方式 RabbitMQ可以通过三种方法来部署分布 ...
- Windows & RabbitMQ:集群(clustering) & 高可用(HA)
描述:我们需要配置三台服务器:ServerA, ServerB, ServerC 注意事项: 所有的服务器的Erlang版本,RabbitMQ版本必须一样 服务器名大小写敏感 Step 1:安装Rab ...
随机推荐
- 请列举出JS对象的几种创建方式?
javascript创建对象简单的说,无非就是使用内置对象或各种自定义对象,当然还可以用JSON:但写法有很多种,也能混合使用. 1.对象字面量的方式 var person={firstname:&q ...
- iOS crash log 解析
iOS开发中,经常遇到App在开发及测试时不会有问题,但是装在别人的设备中会出现各种不定时的莫名的 crash,因为iOS设备会保存应用的大部分的 crash Log,所以可以通过 crash Log ...
- django报错
报错: SyntaxError Generator expression must be parenthesized 问题原因: 由于django 1.11版本和python3.7版本不兼容, 2.0 ...
- Codeforces Round #420 (Div. 2) - C
题目链接:http://codeforces.com/contest/821/problem/C 题意:起初有一个栈,给定2*n个命令,其中n个命令是往栈加入元素,另外n个命令是从栈中取出元素.你可以 ...
- HTML5:新元素来实现一下网页布局
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- jsonp跨域获取数据实现百度搜索
本菜鸡最近在写某个页面请求数据时,报了如下的错误. Failed to load https://...:No 'Access-Control-Allow-Origin' header is pres ...
- error和exception的不同与相同
Exception和Error的区别 两者的“异”&各自的概念: 1.error:error 是指在正常情况下,不大可能出现的情况,绝大部分的 Error 都会导致程序处于非正常的.不可恢复状 ...
- CF1111C Creative Snap 线段树
用线段树模拟一下就好了~ code: #include <cstdio> #include <algorithm> #define lson ls[x] #define rso ...
- 【8.0.0_r4】AMS架构与流程分析
AMS主要用来管理应用程序的生命周期,以及其核心组件,包括Activity,Service,Provider,Broadcast,Task等 之前整体架构如下图(O上已经废弃) 新的架构比较直接,简化 ...
- sql200安装问题
解决方法: 首先把安装目录和C:\Program Files下的Microsoft SQL Server文件夹删了,删除在current_user和local_machine\software\mic ...