MySQL知识集合
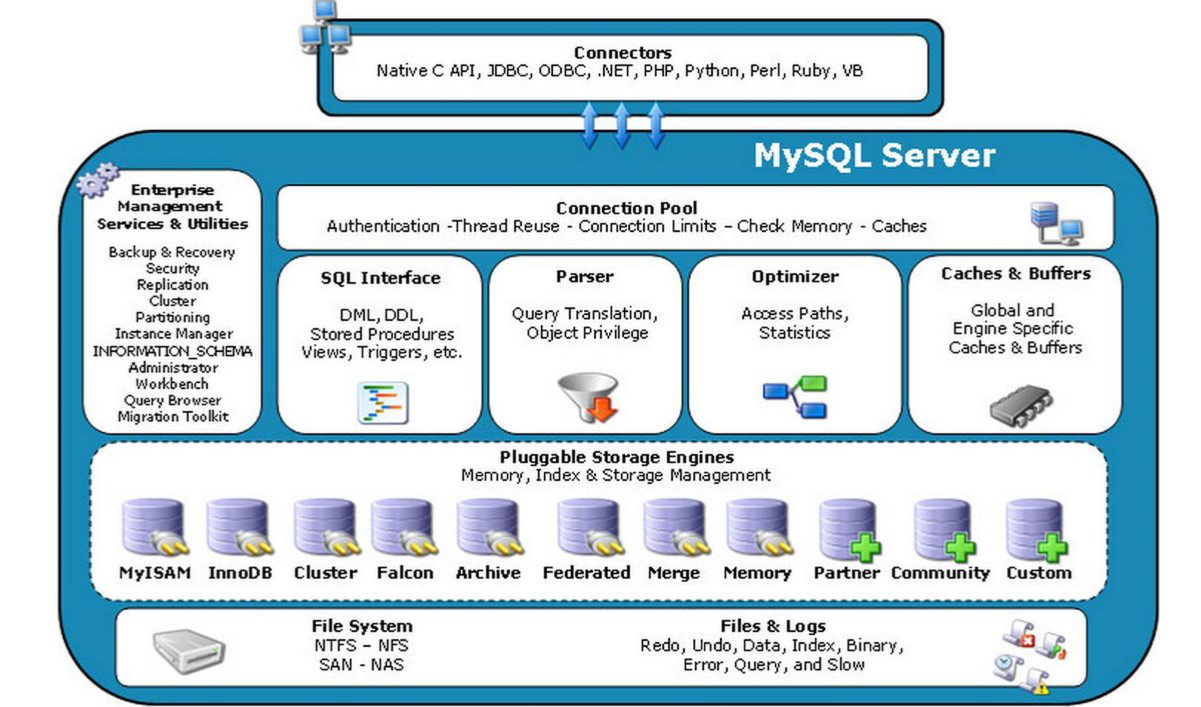
2、MySQL文件结构
3:索引
1、概念
- 以“%(表示任意0个或多个字符)”开头的like语句,模糊匹配
- OR 语句前后没有同时使用索引
- 数据类型出现隐式转换
- 对于多列索引,必须满足 最左匹配原则
- 经常做查询选择的字段
- 经常做表连接的字段
- 经常出现在 order by ,group by, distinct 字段
- 查看表中已经存在的index:show index from table_name;
- 使用create index 语句对表增加索引。
4、锁的类型、锁的粒度、锁的实现?
5、什么是事务?没事务会责会怎么样
- 原子性(automicity):事务种的所有sql,要么全执行,要么全部不执行。
- 一致性(comsistency):转账前,A和B的全部账户共500+500.转装后 400+600
- 隔离性(isolation):在A向B转账的整个过程中,只要事务还没有提交(commit),查询A账户和B账户的钱数量不会变化。
- 持久性(durability):一旦转账成功(事务提交),两个账户的钱就会真的发生变化
6、什么是脏读?幻读?不可重复读?什么是事务的隔离级别?Mysql的默认隔离级别是?
- 脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据。
- 不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
- 幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。也就是可以插入新的行记录。
- Read uncommitted(读未提交):就是一个事务可以读取另一个未提交事务的数据。会造成脏读,不可重复读。
- Read committed(读已提交):就是一个事务要等另一个事务提交后才能读取数据。但还是不可重复读。
- Repeatable read(可重复读):就是在开始读取数据(事务开启)时,不再允许修改操作??
- Serializable (串行化):Serializable 是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。
7、什么是死锁?怎么解决?
8、多版本并发控制
9、char和varchar的区别?
- varchar是变长,char是定长
- varchar占用空间更多,会多出一个字节来储存字符长度,超过255个字符使用两个字节
- char无碎片,varchar经常更新会造成碎片
10、MySQL性能优化
- 表结构优化:数据类型的选择通常更小的最好,尽量避免NULL,表字段不宜太多,有时候反范式设计会带来性能的提升。
- 经常查询的列建立索引
- 索引列的基数越大,数据区分度越高,索引的效果越好。
- 对于字符串进行索引,应该制定一个前缀长度,可以节省大量的索引空间。
- 根据情况创建联合索引,联合索引可以提高查询效率。
- 避免创建过多的索引,索引会额外占用磁盘空间,降低写操作效率。
- 访问数据太多导致查询性能下降
- 确定应用程序是否在检索大量超过需要的数据,可能是太多行或列
- 确认MySQL服务器是否在分析大量不必要的数据行
- 避免犯如下SQL语句错误
- 查询不需要的数据。解决办法:使用limit解决
- 多表关联返回全部列。解决办法:指定列名
- 总是返回全部列。解决办法:避免使用SELECT *
- 重复查询相同的数据。解决办法:可以缓存数据,下次直接读取缓存
- 是否在扫描额外的记录。解决办法:
- 使用explain进行分析,如果发现查询需要扫描大量的数据,但只返回少数的行,可以通过如下技巧去优化:
- 使用索引覆盖扫描,把所有的列都放到索引中,这样存储引擎不需要回表获取对应行就可以返回结果。
- 改变数据库和表的结构,修改数据表范式
- 重写SQL语句,让优化器可以以更优的方式执行查询。
- 确定ON或者USING子句中是否有索引。
- 确保GROUP BY和ORDER BY只有一个表中的列,这样MySQL才有可能使用索引。
- LIMIT偏移量大的时候,查询效率较低
- 可以记录上次查询的最大ID,下次查询时直接根据该ID来查询
11、IN和exists的使用?
- select * from A where cc in (select cc from B),用到了A表上cc列的索引;
- select * from A where exists(select cc from B where cc=A.cc) ,用到了B表上cc列的索引。
12、什么是交叉链接、内链接、外链接?
13、SQL语句关键字的执行顺序
- FROM:对FROM子句中的左表和又表执行笛卡尔积,产生虚拟表VT1。
- ON:对虚拟表T1应用ON筛选,只有那些符合条件的行才被插入虚拟表VT2。
- JOIN:如果指定了OUTER JOIN ,那么保留表中未匹配的行作为外部行添加到虚拟表VT2中,产生虚拟表VT3,。如果FROM子句包含两个以上表,则对上一个连接生成的VT3和下一个表重复执行步骤1-步骤3,直到处理完表为止。
- WHERE:对虚拟表VT3应用WHERE条件筛选,只有符合条件的行才被插入到虚拟表VT4中。
- GROUP BY:根据GROUP BY子句中的列,对VT4中的记录进行分组操作,产生虚拟表VT5。
- CUBE|ROLLUP:对虚拟表VT5进行CUBE或ROLLUP操作,产生虚拟表VT6。
- HAVING:对虚拟表VT6应用HAVING过滤器,只有符合条件的记录才被插入虚拟表VT7。
- SELECT:第二次执行SELECT操作,选择指定的列,插入到虚拟表VT8中。
- DISTINCT:去除重复的数据,产生虚拟表VT9。
- ORDER BY:将虚拟表VT9中的记录按照字段进行排序操作产生虚拟表VT10.
- LIMIT:取出指定行的记录,产生虚拟表VT11,并返回给查询用户。
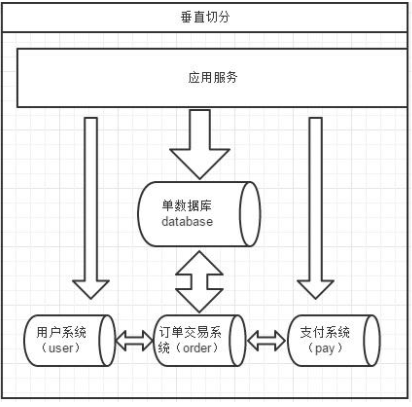
14、垂直切分和水平切分

MySQL知识集合的更多相关文章
- MySQL知识树-查询语句
在日常的web应用开发过程中,一般会涉及到数据库方面的操作,其中查询又是占绝大部分的.我们不仅要会写查询,最好能系统的学习下与查询相关的知识点,这篇随笔我们就来一起看看MySQL查询知识相关的树是什么 ...
- 两个容易被忽略的mysql知识
原文:两个容易被忽略的mysql知识 为什么标题要起这个名字呢?commen sence指的是那些大家都应该知道的事情,但往往大家又会会略这些东西,或者对这些东西一知半解,今天我总结下自己在mysql ...
- 【MySQL】MySQL知识图谱
MySQL 文章目录 MySQL 表 锁 索引 连接管理 事务 日志系统 简单记录 极客时间 - MySQL实战45讲 MySQL知识图谱 表 表 引擎选择 编码问题 表空间管理 字段设计 备份和恢复 ...
- [mysql]知识补充
知识概况 视图 函数 存储过程 事务 索引 触发器 [视图] 视图是一个虚拟表,可以实现查询功能,不能进行增删改 本质:根据sql语句获取动态的数据集,并为其命名 1.创建视图 --create vi ...
- Mysql函数集合
Mysql提供了很多函数 提供的常用函数集合 一.数学函数 ABS(x) 返回x的绝对值 BIN(x) 返回x的二进制(OCT返回八进制,HEX返回十六进制) CEILING(x) 返回大于x的最小整 ...
- mysql知识初篇(一)
mysql介绍 (1) mysql数据库是瑞典AB开发. (2) mysql--> sun --> oracle. (3) mysql数据库的特点. 1. 开源. 2. 免费. 3. 跨平 ...
- mysql 面向集合查询
面向集合的思想 SQL是为查询和管理关系型数据库中的数据而专门设计的一种标准语言.我们通常认为的关系型是说的数据库中表与表的关系,这个理解是有问题的,这里的关系其实是数学术语上的关系.为什么这么说?因 ...
- mysql知识汇总
一.数据类型介绍 数据类型 字节长度 范围或用法 bigint 8 无符号[0,2^64-1],有符号[-2^63 ,2^63 -1] binary(M) M 类似Char的二进制存储,只包含byte ...
- 一些值得收藏的MySQL知识链接
https://yq.aliyun.com/articles/5533(死锁分析的很好的一篇文章) http://hedengcheng.com/?spm=5176.100239.blogcont55 ...
随机推荐
- Wannafly挑战赛22 B 字符路径 ( 拓扑排序+dp )
链接:https://ac.nowcoder.com/acm/contest/160/B 来源:牛客网 题目描述 给一个含n个点m条边的有向无环图(允许重边,点用1到n的整数表示),每条边上有一个字符 ...
- Zen Cart 138 在PHP5.3环境下出现的Fatal error: Cannot redeclare date_diff()
Zen Cart 138 在PHP5.3环境下出现的Fatal error: Cannot redeclare date_diff() in includes/functions/functions_ ...
- Vue基础第一章
Vue的简单示例 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> < ...
- JAVA并发编程的艺术 JMM内存模型
锁的升级和对比 java1.6为了减少获得锁和释放锁带来的性能消耗,引入了"偏向锁"和"轻量级锁". 偏向锁 偏向锁为了解决大部分情况下只有一个线程持有锁的情况 ...
- 【洛谷P2647】最大收益
题目大意 现在你面前有n个物品,编号分别为1,2,3,--,n.你可以在这当中任意选择任意多个物品.其中第i个物品有两个属性Wi和Ri,当你选择了第i个物品后,你就可以获得Wi的收益:但是,你选择该物 ...
- 【NOIP2014模拟8.25】地砖铺设
题目 在游戏厅大赚了一笔的Randy 终于赢到了他想要的家具.乘此机会,他想把自己的房间好好整理一 下. 在百货公司,可以买到各种各样正方形的地砖,为了美观起见,Randy 不希望同样颜色的正方形地 ...
- hdu 6377 : 度度熊看球赛
题目链接 题解: 将原问题转换为 对于全部 (2n)! 种情况,每种情况对ans的贡献为 D^k,其中k表示该情况下有k对情侣座位相邻. 预处理好共有 i (1<=i<=N)对情侣时,出现 ...
- C#.Net集成Bartender条码打印,VS调试运行可以打印,发布到IIS运行打印报错
C#.Net集成Bartender条码打印,VS调试运行可以打印,发布到IIS运行打印报错 问题原因: 问题出现在iis账户权限. 解决方法: iis默认是用network service这个账户去执 ...
- asp.net mvc 异步控制器
参考:https://blog.csdn.net/niewq/article/details/20490707 https://www.cnblogs.com/visonme/p/5537190.ht ...
- sh_03_程序计数
sh_03_程序计数 # 打印 5 遍 Hello Python # 1. 定义一个整数变量,记录循环次数 i = 0 # 2. 开始循环 while i < 3: # 1> 希望在循环内 ...