Task3.特征选择
参考:https://www.jianshu.com/p/f3b92124cd2b
互信息
衡量两个随机变量之间的相关性,两个随机变量相关信息的多少。
随机变量就是随机试验结果的量的表示,可以理解为按照某个概率分布进行取值的变量,比如袋子里随机抽取一个小球就是一个随机变量,互信息就是对x和y所有可能
的取值的点互信息的加权和。
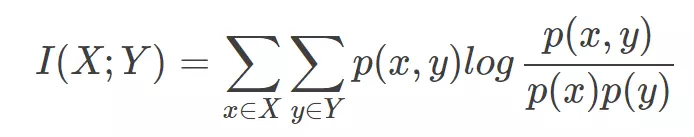
点的互信息PMI从互信息中衍生出来的
PMI用来衡量两个事物之间的相关性,公式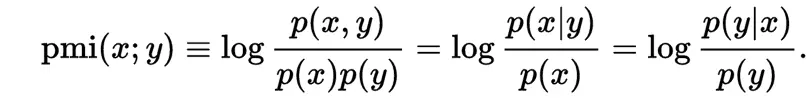
在概率论中,当p(x,y) = p(x) * p(y)我们说x于y相互独立。当概率加上log后,就变成了信息量。
例子:
衡量like这个词的极性(为正向情感还是负向情感),提前调一个正向情感的词如nice,算nice和like的PMI
PMI(like,nice) = log(p(like,nice)/p(like)p(nice))。PMI越大表示两个词的相关性就越大,nice的正向情感就越明显。
编程求解互信息:
from sklearn import metrics as mr
mr.mutual_info_score([1,2,3,4],[4,3,2,1])
tf-idf
tf:Term Frequency 词频
idf: Inverse Document Frequency逆文档频率
在开始,我们用词频来衡量一个词的重量程度,这一点是不科学的,如进行简历筛选时,大部分人都有的技能并不是HR想要寻找的,反而是那些出现频率低的。
所以就出现了idf。
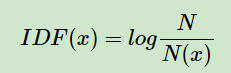
N代表语料库中文本的总数,N(x)代表语料库中包含x的文本数目。可见出现的频率越低,IDF值越大。
避免0概率事件,我们要进行平滑。

右边+1是为了避免该词在所有文本中都出现过,(N(x) = N ,log1=0)。
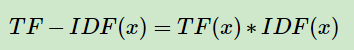
TF(x)指词在当前文本中的词频。
利用sklearn进行统计tfidf值
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'this is the first document',
'this is the second second document',
'and the third one',
'is this the first document'
]
tfidf = TfidfVectorizer()
res = tfidf.fit_transform(corpus)
print(res)
(0, 8) 0.4387767428592343
(0, 3) 0.4387767428592343
(0, 6) 0.35872873824808993
(0, 2) 0.5419765697264572
(0, 1) 0.4387767428592343
(1, 8) 0.27230146752334033
(1, 3) 0.27230146752334033
(1, 6) 0.2226242923251039
(1, 1) 0.27230146752334033
(1, 5) 0.8532257361452784
(2, 6) 0.2884767487500274
(2, 0) 0.5528053199908667
(2, 7) 0.5528053199908667
(2, 4) 0.5528053199908667
(3, 8) 0.4387767428592343
(3, 3) 0.4387767428592343
(3, 6) 0.35872873824808993
(3, 2) 0.5419765697264572
(3, 1) 0.4387767428592343
输出结果为:(文本id,词id)tfidf值
Task3.特征选择的更多相关文章
- 挑子学习笔记:特征选择——基于假设检验的Filter方法
转载请标明出处: http://www.cnblogs.com/tiaozistudy/p/hypothesis_testing_based_feature_selection.html Filter ...
- 用信息值进行特征选择(Information Value)
Posted by c cm on January 3, 2014 特征选择(feature selection)或者变量选择(variable selection)是在建模之前的重要一步.数据接口越 ...
- MIL 多示例学习 特征选择
一个主要的跟踪系统包含三个成分:1)外观模型,通过其可以估计目标的似然函数.2)运动模型,预测位置.3)搜索策略,寻找当前帧最有可能为目标的位置.MIL主要的贡献在第一条上. MIL与CT的不同在于后 ...
- 【转】[特征选择] An Introduction to Feature Selection 翻译
中文原文链接:http://www.cnblogs.com/AHappyCat/p/5318042.html 英文原文链接: An Introduction to Feature Selection ...
- 单因素特征选择--Univariate Feature Selection
An example showing univariate feature selection. Noisy (non informative) features are added to the i ...
- 主成分分析(PCA)特征选择算法详解
1. 问题 真实的训练数据总是存在各种各样的问题: 1. 比如拿到一个汽车的样本,里面既有以“千米/每小时”度量的最大速度特征,也有“英里/小时”的最大速度特征,显然这两个特征有一个多余. 2. 拿到 ...
- 干货:结合Scikit-learn介绍几种常用的特征选择方法
原文 http://dataunion.org/14072.html 主题 特征选择 scikit-learn 作者: Edwin Jarvis 特征选择(排序)对于数据科学家.机器学习从业者来说非 ...
- 【Machine Learning】wekaの特征选择简介
看过这篇博客的都应该明白,特征选择代码实现应该包括3个部分: 搜索算法: 评估函数: 数据: 因此,代码的一般形式为: AttributeSelection attsel = new Attribut ...
- weka特征选择(IG、chi-square)
一.说明 IG是information gain 的缩写,中文名称是信息增益,是选择特征的一个很有效的方法(特别是在使用svm分类时).这里不做详细介绍,有兴趣的可以googling一下. chi-s ...
随机推荐
- Linux内核调试方法总结之ptrace
ptrace [用途] 进程跟踪器,类似于gdb watch的调试方法 [原理][详细说明参考man ptrace帮助文档] ptrace系统调用主要是父进程用来观察和控制子进程的执行过程.检查并替换 ...
- RAM: Residual Attention Module for Single Image Super-Resolution
1. 摘要 注意力机制是深度神经网络的一个设计趋势,其在各种计算机视觉任务中都表现突出.但是,应用到图像超分辨领域的注意力模型大都没有考虑超分辨和其它高层计算机视觉问题的天然不同. 作者提出了一个新的 ...
- Git的资源地址
下载地址:https://git-scm.com/downloads 安装教程: https://baijiahao.baidu.com/s?id=1619087367741781687&wf ...
- IDEA-包层级结构显示(三)
IntelliJ IDEA包层级结构显示 如:A.B.C,在项目中希望以如下形式显示: A B C 效果: 再更换为A.B.C形式显示
- jQuery架构设计与实现(2.1.4版本)
市面上的jQuery书太多了,良莠不齐,看了那么多总觉得少点什么 对"干货",我不喜欢就事论事的写代码,我想把自己所学的知识点,代码技巧,设计思想,代码模式能很好的表达出来,所以考 ...
- docker--虚拟化
1 什么是虚拟化 1.1 概念 在计算机中,虚拟化(英语:Virtualization)是一种资源管理技术,是将计算机的各种 实体资源,如服务器.网络.内存及存储等,予以抽象.转换后呈现出来,打破实体 ...
- [Python3 练习] 002 温度转换2
题目:温度转换 II (1) 描述 温度的刻画有两个不同体系:摄氏度 (Celsius) 和华氏度 (Fabrenheit) 请编写程序将用户输入的华氏度转换为摄氏度,或将输入的摄氏度转换为华氏度 转 ...
- [Python3 填坑] 006 “杠零”,空字符的使用
目录 1. print( 坑的信息 ) 2. 开始填坑 2.1 \0 是空字符,输出时看不到它,但它占 1 个字符的长度 2.2 \0 "遇八进制失效" 2.3 \0 与 '' 不 ...
- 高性能JavaScript模板引擎实现原理详解
这篇文章主要介绍了JavaScript模板引擎实现原理详解,本文着重讲解artTemplate模板的实现原理,它采用预编译方式让性能有了质的飞跃,是其它知名模板引擎的25.32 倍,需要的朋友可以参考 ...
- 面试题思考:Stack和Heap的区别 栈和堆的区别
堆栈的概念: 堆栈是两种数据结构.堆栈都是一种数据项按序排列的数据结构,只能在一端(称为栈顶(top))对数据项进行插入和删除.在单片机应用中,堆栈是个特殊的存储区,主要功能是暂时存放数据和地址,通常 ...