OSS重磅推出OSS Select——使用SQL选取文件的内容
对象存储OSS(Object Storage Service)具有海量、可靠、安全、高性能、低成本的特点。OSS提供标准、低频、归档类型,覆盖多种数据从热到冷的存储需求,单个文件的大小从1字节到48.8TB,可以存储的文件个数无限制。OSS已成为互联网、企业级数据应用的基础设施。
通常,获取对象存储数据的通方式为:获取整个对象,或按指定的字节范围来获取数据。今天,我们重磅推出OSS Select,直接使用简单的SQL语句,从OSS的文件中选取所需要的内容。
OSS Select介绍
使用SQL选取OSS文件中的内容
OSS Select(公测中)让开发者可以直接使用SQL语句,从OSS文件中选取需要的内容。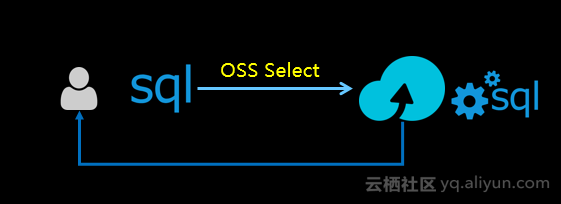
使用OSS Select,只获取应用程序所需的查询结果,并支持并发地分片查询,会大幅提升程序的性能,通常情况下能有400%的提升。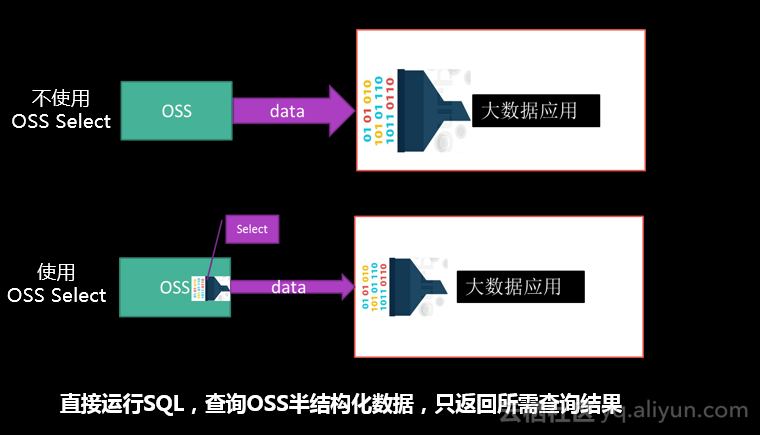
公测说明:
- 文件格式:公测期间支持未加密的CSV格式或者有分隔符的UTF8文本文件,参考RFC4180,
- 公测期间支持标准、低频类型的Object
- 支持RangeQuery(公测期间,RangeQuery模式下不支持Use Header Name)
- OSS Select公测期间免费
- 后续阿里云EMR、DataLakeAnalytics、MaxCompute、HybridDB等都会陆续支持OSS Select
使用示例(python)
# -*- coding: utf-8 -*-
import os
import oss2
def select_call_back(consumed_bytes, total_bytes = None):
print('Consumed Bytes:' + str(consumed_bytes) + '\n')
# 首先初始化AccessKeyId、AccessKeySecret、Endpoint等信息。
# 通过环境变量获取,或者把诸如“<你的AccessKeyId>”替换成真实的AccessKeyId等。
#
# 以杭州区域为例,Endpoint可以是:
# http://oss-cn-hangzhou.aliyuncs.com
# https://oss-cn-hangzhou.aliyuncs.com
# 分别以HTTP、HTTPS协议访问。
access_key_id = os.getenv('OSS_TEST_ACCESS_KEY_ID', '<你的AccessKeyId>')
access_key_secret = os.getenv('OSS_TEST_ACCESS_KEY_SECRET', '<你的AccessKeySecret>')
bucket_name = os.getenv('OSS_TEST_BUCKET', '<你的Bucket>')
endpoint = os.getenv('OSS_TEST_ENDPOINT', '<你的访问域名>')
# 确认上面的参数都填写正确了
for param in (access_key_id, access_key_secret, bucket_name, endpoint):
assert '<' not in param, '请设置参数:' + param
# 创建Bucket对象,所有Object相关的接口都可以通过Bucket对象来进行
bucket = oss2.Bucket(oss2.Auth(access_key_id, access_key_secret), endpoint, bucket_name)
#
csvfile = 'sample.csv'
resultfilename = 'python_select.csv'
csv_meta_params = {'FileHeaderInfo': 'None',
'RecordDelimiter': '\r\n'}
# LineRange(可选参数):表示指定查询行的范围
select_csv_params = {'FileHeaderInfo': 'None',
'LineRange':(100,1000)}
csv_header = bucket.get_csv_object_meta(key, csv_meta_params)
# 将查询结果输出到文件
result = bucket.select_csv_object_to_file(csvfile, resultfile,
"select _1, _3, _4 from ossobject where _4 > 40 and _1 like '%Tom%' ",
select_call_back, input_format)以上是一个简单的python示例,使用SQL查询OSS的对象,并将结果输出到文件汇总。
除了将查询结果输出到文件,还可以将查询结果直接返回
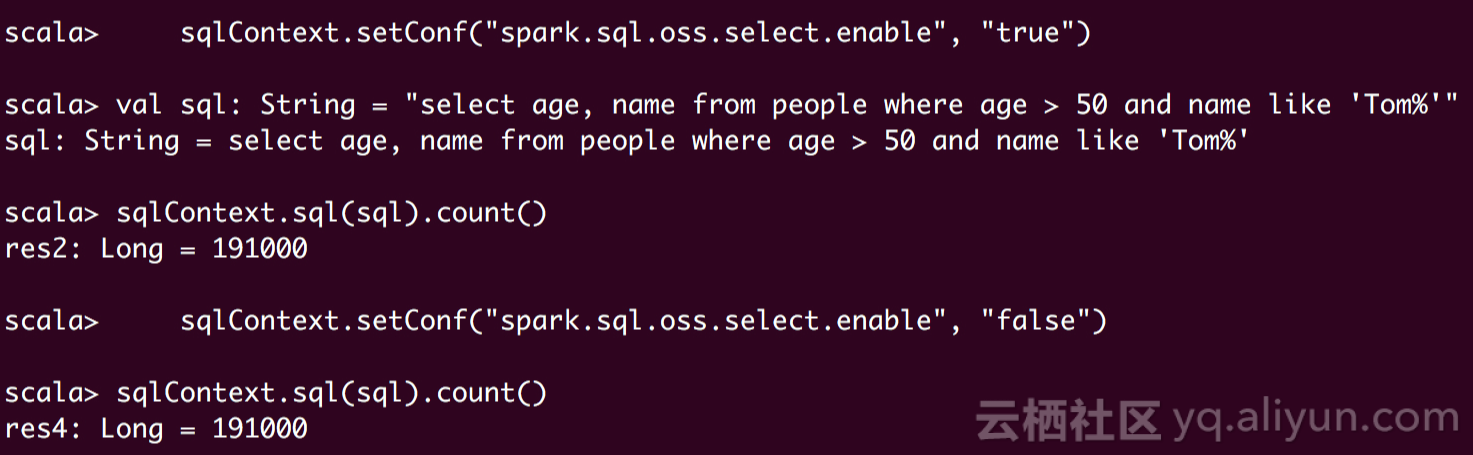
result = bucket.select_csv_object(csvfile, "select * from ossobject where _4 > 40 and _1 like '%Tom%' ", select_call_back, select_csv_params)
content_got = b''
for chunk in result:
content_got += chunk
print(content_got)查询结果:
测试示例
您可以使用OSS Select来加速您的各类应用。OSS Select团队,创建了一个Spark的示例,基于OSS Select,实现 Spark Data Source API。假设,您需要从大量的人员名单中,查询符合条件的人员信息。比如查询50岁以上,姓名中包含Tom的目标人员。
使用OSS Select提升应用程序性能
- 启用OSS Select,Spark借助OSS Select仅获取文件中所需要的数据;而禁用OSS Select,Spark获取整个文件
- 不使用OSS Select,查询需要78秒(1.3分钟)。而使用OSS Select,只需要11秒,程序性能提升6倍!

测试配置说明:
Spark测试集群配置:
| 数量 | 配置 | |
|---|---|---|
| master | 1 | 4core 8GB |
| workers | 2 | 4core 8GB |
Spark配置:
export SPARK_MASTER_IP=master
export SPARK_WORKER_MEMORY=6g
export SPARK_WORKER_CORES=3
export SPARK_WORKER_INSTANCES=1
export SPARK_EXECUTOR_CORES=1
export SPARK_EXECUTOR_MEMORY=2g数据量:
CSV数据量为7GB。
公测申请
阿里云企业认证用户可申请公测,获取试用资格和支持OSS Select测试版Python、Java SDK,点击立即申请
本文作者:whj.
OSS重磅推出OSS Select——使用SQL选取文件的内容的更多相关文章
- 你还可以再诡异点吗——SQL日志文件不断增长
前言 今天算是遇到了一个罕见的案例. SQL日志文件不断增长的各种实例不用多说,园子里有很多牛人有过介绍,如果我再阐述这些陈谷子芝麻,想必已会被无数次吐槽. 但这次我碰到的问题确实比较诡异,其解决方式 ...
- 初始MyBatis、SQL映射文件
MyBatis入门 1.MyBatis前身是iBatis,是Apache的一个开源项目,2010年这个项目迁移到了Google Code,改名为MyBatis,2013年迁移到GitHub.是一个基于 ...
- 二:SQL映射文件
二:SQL映射文件 1.SQL映射文件: (1)mapper:映射文件的根元素节点,只有一个属性namespace(命名空间) 作用:用于区分不同的mapper全局唯一 绑定dao接口即面向接口编程, ...
- Mybatis sql映射文件浅析 Mybatis简介(三)
简介 除了配置相关之外,另一个核心就是SQL映射,MyBatis 的真正强大也在于它的映射语句. Mybatis创建了一套规则以XML为载体映射SQL 之前提到过,各项配置信息将Mybatis应用的整 ...
- 了解一下SQL映射文件
1:SQL映射文件 MyBatis真正强大之处就在于SQL映射语句,相对于强大的功能,SQL映射文件的配置非常简单,与JDBC相比减少了50%的代码.下面是关于SQL映射文件的几个顶级元素配置 map ...
- Mybatis sql映射文件浅析 Mybatis简介(三) 简介
Mybatis sql映射文件浅析 Mybatis简介(三) 简介 除了配置相关之外,另一个核心就是SQL映射,MyBatis 的真正强大也在于它的映射语句. Mybatis创建了一套规则以XML ...
- mysql中如何在命令行中,执行一个SQL脚本文件?
需求描述: 在mysql数据库的使用中,有的时候,需要直接在shell的命令行中,执行某个SQL脚本文件, 比如,要初始化数据库,创建特定的存储过程,创建表等操作,这里进行一个基本的测试. 一般情况, ...
- SQL映射文件-----MySQL关系映射【1对1,1对多,多对多】
SSM框架下,mapper.xml 中 association 标签和 collection 标签的使用 当数据库中表与表之间有关联时,在对数据库进行操作时,就不只是针对某一张表了,需要联表查询 My ...
- SQL映射文件
SQL映射文件的几个顶级元素 mapper - namespace cache - 配置给定命名空间的缓存 cache-ref – 从其他命名空间引用缓存配置 resultMap –用来描述数据库结 ...
随机推荐
- sudo无需输入密码设置
注意这个是无需输入密码的设置,不是无需输入sudo 1 在终端输入: sudo gedit /etc/sudoers 2 在打开文件中的root ALL=(ALL:ALL) ALL下一行添加&qu ...
- QTP技术支持之QTP对象无法识别(转自582357212的个人空间,链接:http://www.51testing.com/html/64/305564-847787.html)
QTP自动化测试从业者,或者很多练习使用QTP开发自动化测试代码的人员遇到最多的问题恐怕就是对象无法识别了,对象无法识别原因有很多种,根据经常对QTP自动化测试脚本开发人员的技术Support,我总结 ...
- Week13 - 376. Wiggle Subsequence
Week13 - 376. Wiggle Subsequence A sequence of numbers is called a wiggle sequence if the difference ...
- 类StringBuffer
1字符串声明和创建 public StringBuffer() 无参构造函数 public StringBuffer(int capacity) 指定容量的字符串缓冲区对象 public String ...
- Android在WindowManagerService和ActivityManagerService中的Token
https://upload-images.jianshu.io/upload_images/5688445-6cf0575bb52ccb45.png 1. ActivityRecord中的token ...
- DS-二叉排序树的插入、查找和删除
2019-12-02(菜鸡开始学习了...) Data Structure 之 二叉排序树 二叉排序树是给定一个节点后,接下来插入的数如果比它大就会放到它的右孩子那边,比它小就会放到它的左孩子那边. ...
- SpringBoot 创建 console程序
1.在pom中添加依赖 <parent> <groupId>org.springframework.boot</groupId> <artifactId> ...
- Navicat批量导出mysql的DDL语句
工作中有的时候需要将某个库中的表.视图.函数.存储过程等创建语句导出,又不需要表中的数据.同时最好放在同一个文件里面,这样方便拷贝. 方法一:需要拷贝的创建语句条数不多,不至于让你拷到头脑发晕的地步, ...
- Spark-Core RDD概述
一.什么是RDD 1.RDD(Resilient Distributed DataSet)弹性分布式数据集 2.是Spark中最基本的数据抽象 3.在代码中是一个抽象类,它代表一个弹性的.不可变的.可 ...
- Mybatis中SqlSessionFactory和SqlSession学习和原理
源码git地址:https://github.com/mybatis/mybatis-3 目标结构: mybatis是数据持久化解决方案将用户从JDBC访问中解放出来,用户只需要定义需要操作的SQL语 ...