tensorflow实现迁移学习
此例程出自《TensorFlow实战Google深度学习框架》6.5.2小节 卷积神经网络迁移学习。
数据集来自http://download.tensorflow.org/example_images/flower_photos.tgz ,及谷歌提供的Inception-v3模型https://storage.googleapis.com/download.tensorflow.org/models/inception_dec_2015.zip 。 自行下载和解压。
解压后的文件夹包含5个子文件夹,每个子文件夹的名称为一种花的名称,代表了不同的类别。
工程目录:
-transfer_learning
-flower_data //存放原始图片的文件夹,有5个子文件夹, 每个子文件夹的名称为一种花的名称
-daisy //daisy类花图片的文件夹
-dandelion
-roses
-sunflowers
-tulips
-LICENSE.txt
-model //存放模型的文件夹
-imagenet_comp_graph_label_strings.txt
-LICENSE
-tensorflow_inception_graph.pb //模型文件
-tmp
-bottleneck //保存模型瓶颈层的特征结果
-daisy //daisy类花特征的文件夹
-dandelion
-roses
-sunflowers
-tulips
-transfer_flower.py //所有的程序都在这里了
transfer_flower.py
# -*- coding: utf-8 -*- import glob
import os.path
import random
import numpy as np
import tensorflow as tf
from tensorflow.python.platform import gfile # Inception-v3模型瓶颈层的节点个数
BOTTLENECK_TENSOR_SIZE = 2048 # Inception-v3模型中代表瓶颈层结果的张量名称。
# 在谷歌提出的Inception-v3模型中,这个张量名称就是'pool_3/_reshape:0'。
# 在训练模型时,可以通过tensor.name来获取张量的名称。
BOTTLENECK_TENSOR_NAME = 'pool_3/_reshape:0' # 图像输入张量所对应的名称。
JPEG_DATA_TENSOR_NAME = 'DecodeJpeg/contents:0' # 下载的谷歌训练好的Inception-v3模型文件目录
MODEL_DIR = 'model/' # 下载的谷歌训练好的Inception-v3模型文件名
MODEL_FILE = 'tensorflow_inception_graph.pb' # 因为一个训练数据会被使用多次,所以可以将原始图像通过Inception-v3模型计算得到的特征向量保存在文件中,免去重复的计算。
# 下面的变量定义了这些文件的存放地址。
CACHE_DIR = 'tmp/bottleneck/' # 图片数据文件夹。
# 在这个文件夹中每一个子文件夹代表一个需要区分的类别,每个子文件夹中存放了对应类别的图片。
INPUT_DATA = 'flower_data/' # 验证的数据百分比
VALIDATION_PERCENTAGE = 10
# 测试的数据百分比
TEST_PERCENTAGE = 10 # 定义神经网络的设置
LEARNING_RATE = 0.01
STEPS = 4000
BATCH = 100 # 这个函数从数据文件夹中读取所有的图片列表并按训练、验证、测试数据分开。
# testing_percentage和validation_percentage参数指定了测试数据集和验证数据集的大小。
def create_image_lists(testing_percentage, validation_percentage):
# 得到的所有图片都存在result这个字典(dictionary)里。
# 这个字典的key为类别的名称,value也是一个字典,字典里存储了所有的图片名称。
result = {}
# 获取当前目录下所有的子目录
sub_dirs = [x[0] for x in os.walk(INPUT_DATA)]
# 得到的第一个目录是当前目录,不需要考虑
is_root_dir = True
for sub_dir in sub_dirs:
if is_root_dir:
is_root_dir = False
continue # 获取当前目录下所有的有效图片文件。
extensions = ['jpg', 'jpeg', 'JPG', 'JPEG']
file_list = []
dir_name = os.path.basename(sub_dir)
for extension in extensions:
file_glob = os.path.join(INPUT_DATA, dir_name, '*.'+extension)
file_list.extend(glob.glob(file_glob))
if not file_list:
continue # 通过目录名获取类别的名称。
label_name = dir_name.lower()
# 初始化当前类别的训练数据集、测试数据集和验证数据集
training_images = []
testing_images = []
validation_images = []
for file_name in file_list:
base_name = os.path.basename(file_name)
# 随机将数据分到训练数据集、测试数据集和验证数据集。
chance = np.random.randint(100)
if chance < validation_percentage:
validation_images.append(base_name)
elif chance < (testing_percentage + validation_percentage):
testing_images.append(base_name)
else:
training_images.append(base_name) # 将当前类别的数据放入结果字典。
result[label_name] = {
'dir': dir_name,
'training': training_images,
'testing': testing_images,
'validation': validation_images
}
# 返回整理好的所有数据
return result # 这个函数通过类别名称、所属数据集和图片编号获取一张图片的地址。
# image_lists参数给出了所有图片信息。
# image_dir参数给出了根目录。存放图片数据的根目录和存放图片特征向量的根目录地址不同。
# label_name参数给定了类别的名称。
# index参数给定了需要获取的图片的编号。
# category参数指定了需要获取的图片是在训练数据集、测试数据集还是验证数据集。
def get_image_path(image_lists, image_dir, label_name, index, category):
# 获取给定类别中所有图片的信息。
label_lists = image_lists[label_name]
# 根据所属数据集的名称获取集合中的全部图片信息。
category_list = label_lists[category]
mod_index = index % len(category_list)
# 获取图片的文件名。
base_name = category_list[mod_index]
sub_dir = label_lists['dir']
# 最终的地址为数据根目录的地址 + 类别的文件夹 + 图片的名称
full_path = os.path.join(image_dir, sub_dir, base_name)
return full_path # 这个函数通过类别名称、所属数据集和图片编号获取经过Inception-v3模型处理之后的特征向量文件地址。
def get_bottlenect_path(image_lists, label_name, index, category):
return get_image_path(image_lists, CACHE_DIR, label_name, index, category) + '.txt'; # 这个函数使用加载的训练好的Inception-v3模型处理一张图片,得到这个图片的特征向量。
def run_bottleneck_on_image(sess, image_data, image_data_tensor, bottleneck_tensor):
# 这个过程实际上就是将当前图片作为输入计算瓶颈张量的值。这个瓶颈张量的值就是这张图片的新的特征向量。
bottleneck_values = sess.run(bottleneck_tensor, {image_data_tensor: image_data})
# 经过卷积神经网络处理的结果是一个四维数组,需要将这个结果压缩成一个特征向量(一维数组)
bottleneck_values = np.squeeze(bottleneck_values)
return bottleneck_values # 这个函数获取一张图片经过Inception-v3模型处理之后的特征向量。
# 这个函数会先试图寻找已经计算且保存下来的特征向量,如果找不到则先计算这个特征向量,然后保存到文件。
def get_or_create_bottleneck(sess, image_lists, label_name, index, category, jpeg_data_tensor, bottleneck_tensor):
# 获取一张图片对应的特征向量文件的路径。
label_lists = image_lists[label_name]
sub_dir = label_lists['dir']
sub_dir_path = os.path.join(CACHE_DIR, sub_dir)
if not os.path.exists(sub_dir_path):
os.makedirs(sub_dir_path)
bottleneck_path = get_bottlenect_path(image_lists, label_name, index, category)
# 如果这个特征向量文件不存在,则通过Inception-v3模型来计算特征向量,并将计算的结果存入文件。
if not os.path.exists(bottleneck_path):
# 获取原始的图片路径
image_path = get_image_path(image_lists, INPUT_DATA, label_name, index, category)
# 获取图片内容。
image_data = gfile.FastGFile(image_path, 'rb').read()
# print(len(image_data))
# 由于输入的图片大小不一致,此处得到的image_data大小也不一致(已验证),但却都能通过加载的inception-v3模型生成一个2048的特征向量。具体原理不详。
# 通过Inception-v3模型计算特征向量
bottleneck_values = run_bottleneck_on_image(sess, image_data, jpeg_data_tensor, bottleneck_tensor)
# 将计算得到的特征向量存入文件
bottleneck_string = ','.join(str(x) for x in bottleneck_values)
with open(bottleneck_path, 'w') as bottleneck_file:
bottleneck_file.write(bottleneck_string)
else:
# 直接从文件中获取图片相应的特征向量。
with open(bottleneck_path, 'r') as bottleneck_file:
bottleneck_string = bottleneck_file.read()
bottleneck_values = [float(x) for x in bottleneck_string.split(',')]
# 返回得到的特征向量
return bottleneck_values # 这个函数随机获取一个batch的图片作为训练数据。
def get_random_cached_bottlenecks(sess, n_classes, image_lists, how_many, category,
jpeg_data_tensor, bottleneck_tensor):
bottlenecks = []
ground_truths = []
for _ in range(how_many):
# 随机一个类别和图片的编号加入当前的训练数据。
label_index = random.randrange(n_classes)
label_name = list(image_lists.keys())[label_index]
image_index = random.randrange(65536)
bottleneck = get_or_create_bottleneck(sess, image_lists, label_name, image_index, category,
jpeg_data_tensor, bottleneck_tensor)
ground_truth = np.zeros(n_classes, dtype=np.float32)
ground_truth[label_index] = 1.0
bottlenecks.append(bottleneck)
ground_truths.append(ground_truth)
return bottlenecks, ground_truths # 这个函数获取全部的测试数据。在最终测试的时候需要在所有的测试数据上计算正确率。
def get_test_bottlenecks(sess, image_lists, n_classes, jpeg_data_tensor, bottleneck_tensor):
bottlenecks = []
ground_truths = []
label_name_list = list(image_lists.keys())
# 枚举所有的类别和每个类别中的测试图片。
for label_index, label_name in enumerate(label_name_list):
category = 'testing'
for index, unused_base_name in enumerate(image_lists[label_name][category]):
# 通过Inception-v3模型计算图片对应的特征向量,并将其加入最终数据的列表。
bottleneck = get_or_create_bottleneck(sess, image_lists, label_name, index, category,
jpeg_data_tensor, bottleneck_tensor)
ground_truth = np.zeros(n_classes, dtype = np.float32)
ground_truth[label_index] = 1.0
bottlenecks.append(bottleneck)
ground_truths.append(ground_truth)
return bottlenecks, ground_truths def main(_):
# 读取所有图片。
image_lists = create_image_lists(TEST_PERCENTAGE, VALIDATION_PERCENTAGE)
n_classes = len(image_lists.keys())
# 读取已经训练好的Inception-v3模型。
# 谷歌训练好的模型保存在了GraphDef Protocol Buffer中,里面保存了每一个节点取值的计算方法以及变量的取值。
# TensorFlow模型持久化的问题在第5章中有详细的介绍。
with gfile.FastGFile(os.path.join(MODEL_DIR, MODEL_FILE), 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
# 加载读取的Inception-v3模型,并返回数据输入所对应的张量以及计算瓶颈层结果所对应的张量。
bottleneck_tensor, jpeg_data_tensor = tf.import_graph_def(graph_def, return_elements=[BOTTLENECK_TENSOR_NAME, JPEG_DATA_TENSOR_NAME])
# 定义新的神经网络输入,这个输入就是新的图片经过Inception-v3模型前向传播到达瓶颈层时的结点取值。
# 可以将这个过程类似的理解为一种特征提取。
bottleneck_input = tf.placeholder(tf.float32, [None, BOTTLENECK_TENSOR_SIZE], name='BottleneckInputPlaceholder')
# 定义新的标准答案输入
ground_truth_input = tf.placeholder(tf.float32, [None, n_classes], name='GroundTruthInput')
# 定义一层全连接层来解决新的图片分类问题。
# 因为训练好的Inception-v3模型已经将原始的图片抽象为了更加容易分类的特征向量了,所以不需要再训练那么复杂的神经网络来完成这个新的分类任务。
with tf.name_scope('final_training_ops'):
weights = tf.Variable(tf.truncated_normal([BOTTLENECK_TENSOR_SIZE, n_classes], stddev=0.001))
biases = tf.Variable(tf.zeros([n_classes]))
logits = tf.matmul(bottleneck_input, weights) + biases
final_tensor = tf.nn.softmax(logits)
# 定义交叉熵损失函数
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=ground_truth_input)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
train_step = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(cross_entropy_mean)
# 计算正确率
with tf.name_scope('evaluation'):
correct_prediction = tf.equal(tf.argmax(final_tensor, 1), tf.argmax(ground_truth_input, 1))
evaluation_step = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) with tf.Session() as sess:
tf.global_variables_initializer().run()
# 训练过程
for i in range(STEPS):
# 每次获取一个batch的训练数据
train_bottlenecks, train_ground_truth = get_random_cached_bottlenecks(
sess, n_classes, image_lists, BATCH, 'training', jpeg_data_tensor, bottleneck_tensor)
sess.run(train_step, feed_dict={bottleneck_input: train_bottlenecks, ground_truth_input: train_ground_truth})
# 在验证集上测试正确率。
if i%100 == 0 or i+1 == STEPS:
validation_bottlenecks, validation_ground_truth = get_random_cached_bottlenecks(
sess, n_classes, image_lists, BATCH, 'validation', jpeg_data_tensor, bottleneck_tensor)
validation_accuracy = sess.run(evaluation_step, feed_dict={
bottleneck_input:validation_bottlenecks, ground_truth_input: validation_ground_truth})
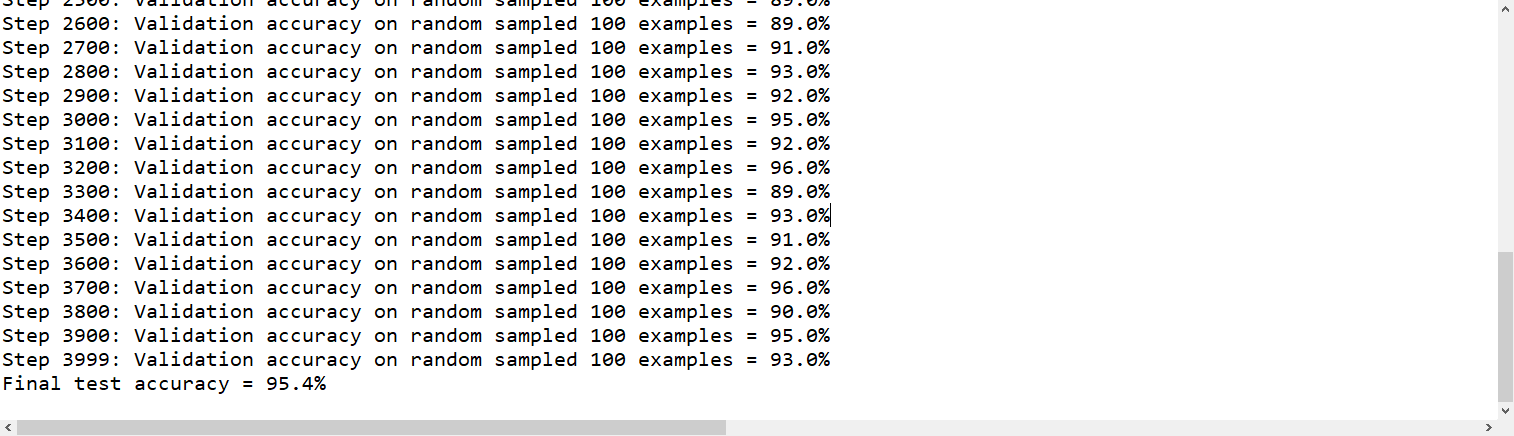
print('Step %d: Validation accuracy on random sampled %d examples = %.1f%%'
% (i, BATCH, validation_accuracy*100))
# 在最后的测试数据上测试正确率
test_bottlenecks, test_ground_truth = get_test_bottlenecks(sess, image_lists, n_classes,
jpeg_data_tensor, bottleneck_tensor)
test_accuracy = sess.run(evaluation_step, feed_dict={bottleneck_input: test_bottlenecks,
ground_truth_input: test_ground_truth})
print('Final test accuracy = %.1f%%' % (test_accuracy * 100)) if __name__ == '__main__':
tf.app.run()
2.代码疑问
不知道大家有注意到没有,数据集里给的是不同大小的图片,而程序里却可以直接送入Inception-v3模型,从而得到同样尺寸的结果特征向量。我在书籍的github上问了这个问题,得到的回复是:Inception-v3模型中包含了图像预处理和大小调整的部分。目前并没有往下继续考究。原问题详见:caicloud/tensorflow-tutorial第6章迁移学习例程疑问
转自:http://blog.csdn.net/nnnnnnnnnnnny/article/details/70244232
tensorflow实现迁移学习的更多相关文章
- 『TensorFlow』迁移学习
完全版见github:TransforLearning 零.迁移学习 将一个领域的已经成熟的知识应用到其他的场景中称为迁移学习.用神经网络的角度来表述,就是一层层网络中每个节点的权重从一个训练好的网络 ...
- TensorFlow keras 迁移学习
数据的读取 import tensorflow as tf from tensorflow.python import keras from tensorflow.python.keras.prepr ...
- 吴裕雄--天生自然python Google深度学习框架:Tensorflow实现迁移学习
import glob import os.path import numpy as np import tensorflow as tf from tensorflow.python.platfor ...
- ML.NET 示例:图像分类模型训练-首选API(基于原生TensorFlow迁移学习)
ML.NET 版本 API 类型 状态 应用程序类型 数据类型 场景 机器学习任务 算法 Microsoft.ML 1.5.0 动态API 最新 控制台应用程序和Web应用程序 图片文件 图像分类 基 ...
- 用tensorflow迁移学习猫狗分类
笔者这几天在跟着莫烦学习TensorFlow,正好到迁移学习(至于什么是迁移学习,看这篇),莫烦老师做的是预测猫和老虎尺寸大小的学习.作为一个有为的学生,笔者当然不能再预测猫啊狗啊的大小啦,正好之前正 ...
- TensorFlow从1到2(九)迁移学习
迁移学习基本概念 迁移学习是这两年比较火的一个话题,主要原因是在当前的机器学习中,样本数据的获取是成本最高的一块.而迁移学习可以有效的把原有的学习经验(对于模型就是模型本身及其训练好的权重值)带入到新 ...
- TensorFlow迁移学习的识别花试验
最近学习了TensorFlow,发现一个模型叫vgg16,然后搭建环境跑了一下,觉得十分神奇,而且准确率十分的高.又上了一节选修课,关于人工智能,老师让做一个关于人工智能的试验,于是觉得vgg16很不 ...
- 第二十四节,TensorFlow下slim库函数的使用以及使用VGG网络进行预训练、迁移学习(附代码)
在介绍这一节之前,需要你对slim模型库有一些基本了解,具体可以参考第二十二节,TensorFlow中的图片分类模型库slim的使用.数据集处理,这一节我们会详细介绍slim模型库下面的一些函数的使用 ...
- 1 如何使用pb文件保存和恢复模型进行迁移学习(学习Tensorflow 实战google深度学习框架)
学习过程是Tensorflow 实战google深度学习框架一书的第六章的迁移学习环节. 具体见我提出的问题:https://www.tensorflowers.cn/t/5314 参考https:/ ...
随机推荐
- 简单了解journalctl
journalctl 命令 journalctl是什么以及作用? journalctl 用来查询 systemd-journald 服务收集到的日志.systemd-journald 服务是 syst ...
- 07 Python之字典和集合
1. 什么是字典 字典是用{}表示,以key:value的形式来保存数据的,其查找效率比较高 坑: 字典存储数据时是用哈希值来存储的,算法不能变(python的) 数据必须是可哈希的(不可变的),字典 ...
- ECharts模拟百度迁徙实例
本实例原始信息: 作者:anix 演示地址:Echarts模拟迁徙 源码地址:GitHub-ananix-qianxi 前言 "百度地图春节人口迁徙大数据"(简称"百度迁 ...
- mybatis的if
<select id="findList" resultType="BndExport"> SELECT <include refid=&qu ...
- python、第五篇:数据备份、pymysql模块
一 IDE工具介绍 生产环境还是推荐使用mysql命令行,但为了方便我们测试,可以使用IDE工具 下载链接:https://pan.baidu.com/s/1bpo5mqj 掌握: #1. 测试+链接 ...
- 紫书 例题 10-11 UVa 11181(概率计算)
这道题不能凭感觉做了.要套公式 r个人买了东西叫事件E, 第i个人买东西的概率叫做事件Ei 求得是P(E|Ei), 则P(E|Ei)= P(E|Ei)/ P(E) 那么P(E)可以枚举求得, 用递归求 ...
- spring ObjectFactory
AspectJAwareAdvisorAutoProxyCreator implements PostProcessor postProcessorAfterInitialization(Object ...
- Java I/O(一)流和文件类File的概述、FileInputStream和FileInputStream
一.流概述 & InputStream.OutputStream 流包括输入流和输出流,即I/O(Input和Output),具体结构如下: I/O类都被放在java.io包中,所有的输入流类 ...
- Android 热修复 Tinker platform 中的坑,以及详细步骤(二)
操作流程: 一.注册平台账号: http://www.tinkerpatch.com 二.查看操作文档: http://www.tinkerpatch.com/Docs/SDK 参考文档: https ...
- 2019春Python程序设计练习4(4.9-4.15)
1-1 如下代码可以实现当输入6的时候输出x>5,输入4的时候输出 3<x<=5,输入1的时候输出x<=3 x = int(input()) if x>5: print( ...