ML 04、模型评估与模型选择
机器学习算法 原理、实现与实践——模型评估与模型选择
1. 训练误差与测试误差
机器学习的目的是使学习到的模型不仅对已知数据而且对未知数据都能有很好的预测能力。
假设学习到的模型是$Y = \hat{f}(X)$,训练误差是模型$Y = \hat{f}(X)$关于训练数据集的平均损失:
$$R_{emp}(\hat{f}) = \frac{1}{N}\sum_{i=1}^NL(y_i,\hat{f}(x_i))$$
其中$N$是训练样本容量。
测试误差是模型$Y = \hat{f}(X)$关于测试数据集的平均损失:
$$e_{test}(\hat{f}) = \frac{1}{N’}\sum_{i=1}^NL(y_i,\hat{f}(x_i))$$
其中$N’$是测试样本容量。
当损失函数是0-1损失时,测试误差就变成了常见的测试数据集上的误差率(预测错误的个数除以测试数据的总个数)。
训练误差的大小,对判定给定问题是不是一个容易学习的问题是有意义的,但本质上不重要。测试误差反映了学习方法对未知数据集的预测能力,是学习中的重要概念。显然,给定两种学习方法,测试误差小的方法具有更好的预测能力,是更有效的方法。通常将学习方法对未知数据的预测能力称为泛化能力(generalization ability)。
2. 过拟合与模型选择
我们知道假设空间理论上有无限个模型,它们有着不同的复杂度(一般表现为参数个数的多少),我们希望选择或学习一个合适的模型。
如果一味提高对训练数据的预测能力,所选的模型的复杂度则往往会比真实模型更高。这种现象称为过拟合。过拟合是指学习时选择的模型所包含的参数过多,以致于出现这一模型对已知数据预测很好,但对未知数据预测很差的现象。
下面,以多项式函数拟合问题为例,说明过拟合与模型选择,这是一个回归问题。
现在给定一个训练数据集:
$$T=\{(x_1,y_1),(x_2,y_2),\dots,(x_n,y_n)\}$$
其中,$x_i\in R$是输入$x$的观测值,$y_i\in R$是相应的输出$y$的观测值。多项式函数拟合的任务是假设给定数据由M次多项式函数生成,选择最有可能产生这些数据的M次多项式函数,即在M次多项式函数中选择一个对已知数据以及未知数据都有很多预测能力的函数。
设M次多项式为:
$$f_M(x,w) = w_0+w_1x+w_2x^2+\dots+w_Mx^M = \sum_{j=0}^Mw_jx^j$$
对于上面这个问题,模型的复杂度即为多项式的次数;然后在给定的模型复杂度下,按照经验风险最小化策略,求解参数,即多项式的系数,具体地,求以下经验风险最小化:
$$L(w) = \frac{1}{2}\sum^N_{i=1}(f(x_i,w)-y_i)^2$$
这时,损失函数为平方损失,系数$\frac{1}{2}$是为了计算方便。
我们用$y = sin(x)$生成10个数据点,并适当的在$y$值上加了一些误差,下面我们分别用0~9次多项式对数据进行拟合。
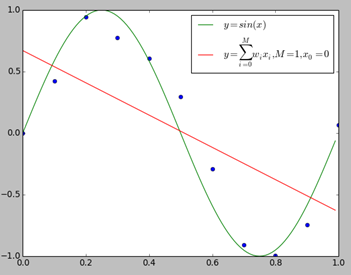
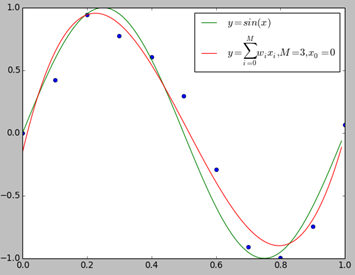
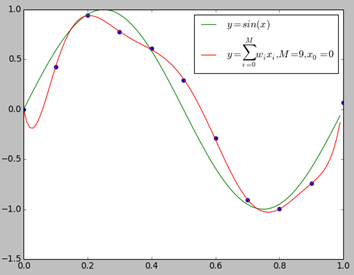
上图给出了$M=1,M=3,M=9$时多项式拟合的情况。当$M=1$时多项式曲线是一条直线,数据拟合效果很差。相反,如果$M=9$,多项式曲线通过每个数据点,训练误差为0。从对给定的训练数据拟合的角度来说,效果是最好的。但是因为训练数据本身存在噪声,这种拟合曲线对未知数据的预测能力往往并不是最好的,这时过拟合现象就会发生。
import numpy as np
import matplotlib.pyplot as plt
import random
x = np.linspace(0,1,10)
y = np.sin(2*np.pi*x)
for i in range(0,10):
y[i] = y[i] + random.uniform(-0.4,0.4)
p = np.polyfit(x,y,9)
t = np.linspace(0,1.0,100)
plt.plot(x,y,'o')
plt.plot(t,np.sin(np.pi*2*t),label='$y=sin(x)$');
plt.plot(t,np.polyval(p,t),label='$y = \sum_{i=0}^Mw_ix_i,M=9,x_0=0$');
plt.legend()
plt.show()
3. 正则化与交叉验证
3.1 正则化
前面文章在介绍机器学习策略的时候,已经提到过结构风险最小化的概念。结构风险最小化正是为了解决过拟合问题来提出来的策略,它在经验风险上加一个正则化项。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。比如,正则化项可以是模型参数的向量的范数。
正则化项可以取不同的形式。例如,回归问题中,损失函数是平方损失,正则化项可以是参数向量的$L_2$范数:
$$L(w) = \frac{1}{N}\sum_{i=1}^N(f(x_i;w)-y_i)^2+\frac{\lambda}{2}||w||^2$$
这里,$||w||$表示参数向量$w$的$L_2$范数。
正则化项也可以是参数向量的$L_1$范数:
$$L(w) = \frac{1}{N}\sum_{i=1}^N(f(x_i;w)-y_i)^2+\lambda||w||_1$$
这里,$||w||_1$表示参数向量$w$的$L_1$范数。
正则化符合奥卡姆剃刀(Occam’s razor)原理。奥卡姆剃刀应用在模型选择时想法是:在所有可能选择的模型中,能够很好地解释已知数据并且十分简单才是最好的模型,也就是应该选择的模型。从贝叶斯估计的角度来看,正则化项对应于模型的先验概率。可以假设复杂模型有较小的先验概率,简单的模型有较大的先验概率。
3.2 交叉验证
如果给定的样本数据充足,进行模型选择的一种简单方法是随机地将数据集切分成三部分,分别为训练集、验证集和测试集。训练集用来训练模型,验证集用于模型的选择,而测试集用于最终对学习方法的评估。在学习到的不同复杂度的模型中,选择对验证集有最小预测误差的模型。
但是在许多实际应用中数据是不充分的。为了选择好的模型,可以采用交叉验证方法。交叉验证的基本想法是重复地使用数据;把给定的数据进行切分,将切分的数据集组合为训练集与测试集,在此基础上反复地进行训练、测试以及模型选择。
1. 简单交叉验证
首先随机地将已给数据分为两部分,一部分作为训练集,另一部分作为测试集;然后用训练集在各种条件下训练模型,从而得到不同的模型;在测试集上评价各个模型的测试误差,选出测试误差最小的模型。
2. S折交叉验证
这种方法应用最多。首先随机地将已给的数据切分为S个互不相交的大小相同的子集;然后利用其中的S-1个子集的数据训练模型,然后用余下的子集测试模型;将这一过程对可能的S种选择重复进行;最后选出S次评测中平均测试误差最小的模型。
3. 留一交叉验证
S折交叉验证的特征情形是$S=N$,称为留一交叉验证,往往在数据缺乏的情况下使用。这里,N是给定数据集的容量。
4. 泛化能力
学习方法的泛化能力是指由该方法学习到的模型对未知数据的预测能力,是学习方法本质上重要的性质。现实中采用最多的办法是通过测试数据集的误差来评价学习方法的泛化能力。但是因为数据是有限的,并不能代表全体未知样本,所以很有可能按照这样评价到得的结果是不可靠的。
下面我们从理论上对学习方法的泛化能力进行分析。
首先给出泛化误差的定义。如果学习到的模型是$\hat{f}$,那么用这个模型对未知数据预测的误差即为泛化误差(generalization error)
$$R_{exp}(\hat{f}) = E_P[L(Y,\hat{f}(X))] = \int_{\mathcal{X}\times\mathcal{Y}}L(y,\hat{f}(x))P(x,y)dxdy$$
泛化误差反映了学习方法的泛化能力,如果一种方法学习的模型比另一种方法学习的模型具有更小的泛化误差,那么这种方法就更有效。事实上,泛化误差就是所学习到的模型的期望风险。
而我们知道数据的联合分布函数我们是不知道的,所以实际中,学习方法的泛化能力分析往往是通过研究泛化误差的概率上界进行的,简称泛化误差上界(generalization error bound)。具体来说,就是通过比较两种学习方法的泛化误差上界的大小来比较它们的优劣。
对二分类问题,当假设空间有有限个函数的集合$\mathcal{F}={f_1,f_2,\dots,f_d}$时,对任意一个函数$f\in\mathcal{F}$,至少以概率$1-\delta$,以下不等式成立:
$$R(f) \le \hat{R}(f)+\varepsilon(d,N,\delta)$$
其中,$\varepsilon(d,N,\delta)=\sqrt{\frac{1}{2N}(\log d+\log\frac{1}{\delta})}$
不等式左边$R(f)$是泛化误差,右端即为泛化误差的上界。$\hat{R}(f)$为训练误差。
ML 04、模型评估与模型选择的更多相关文章
- PLUTO平台是由美林数据技术股份有限公司下属西安交大美林数据挖掘研究中心自主研发的一款基于云计算技术架构的数据挖掘产品,产品设计严格遵循国际数据挖掘标准CRISP-DM(跨行业数据挖掘过程标准),具备完备的数据准备、模型构建、模型评估、模型管理、海量数据处理和高纬数据可视化分析能力。
http://www.meritdata.com.cn/article/90 PLUTO平台是由美林数据技术股份有限公司下属西安交大美林数据挖掘研究中心自主研发的一款基于云计算技术架构的数据挖掘产品, ...
- Scikit-learn:模型评估Model evaluation
http://blog.csdn.net/pipisorry/article/details/52250760 模型评估Model evaluation: quantifying the qualit ...
- 模型的性能评估(二) 用sklearn进行模型评估
在sklearn当中,可以在三个地方进行模型的评估 1:各个模型的均有提供的score方法来进行评估. 这种方法对于每一种学习器来说都是根据学习器本身的特点定制的,不可改变,这种方法比较简单.这种方法 ...
- python大战机器学习——模型评估、选择与验证
1.损失函数和风险函数 (1)损失函数:常见的有 0-1损失函数 绝对损失函数 平方损失函数 对数损失函数 (2)风险函数:损失函数的期望 经验风险:模型在数据集T上的平均损失 根据大 ...
- SparkML之推荐引擎(二)---推荐模型评估
本文内容和代码是接着上篇文章来写的,推荐先看一下哈~ 我们上一篇文章是写了电影推荐的实现,但是推荐内容是否合理呢,这就需要我们对模型进行评估 针对推荐模型,这里根据 均方差 和 K值平均准确率 来对模 ...
- ML.NET 示例:图像分类模型训练-首选API(基于原生TensorFlow迁移学习)
ML.NET 版本 API 类型 状态 应用程序类型 数据类型 场景 机器学习任务 算法 Microsoft.ML 1.5.0 动态API 最新 控制台应用程序和Web应用程序 图片文件 图像分类 基 ...
- 笔记︱风控分类模型种类(决策、排序)比较与模型评估体系(ROC/gini/KS/lift)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本笔记源于CDA-DSC课程,由常国珍老师主讲 ...
- sklearn中的模型评估-构建评估函数
1.介绍 有三种不同的方法来评估一个模型的预测质量: estimator的score方法:sklearn中的estimator都具有一个score方法,它提供了一个缺省的评估法则来解决问题. Scor ...
- 评价指标的局限性、ROC曲线、余弦距离、A/B测试、模型评估的方法、超参数调优、过拟合与欠拟合
1.评价指标的局限性 问题1 准确性的局限性 准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷.比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率.所以,当 ...
随机推荐
- linux crontab介绍
第1列分钟1-59第2列小时1-23(0表示子夜)第3列日1-31第4列月1-12第5列星期0-6(0表示星期天)第6列要运行的命令 下面是crontab的格式:分 时 日 月 星期 要运行的命令 这 ...
- 安装lnmp后,忘记phpmyadmin的root密码,怎么办
如果忘记MySQL root密码,如何重设密码?执行如下命令:wget http://soft.vpser.net/lnmp/ext/reset_mysql_root_password.sh;sh r ...
- 利用ADSL拨号上网方式如何搭建服务器
序:搭建服务器需要两个条件硬件服务器和固定公网IP,随便一台个人电脑都可以作为硬件服务器,就剩下一个问题,如何获得一个固定公网IP. 第一章 扫盲:ADSL拨号上网方式,本地IP与公网IP的区别 一. ...
- NOIP2011 聪明的质监员
描述 小T 是一名质量监督员,最近负责检验一批矿产的质量.这批矿产共有 n 个矿石,从 1到n 逐一编号,每个矿石都有自己的重量 wi 以及价值vi .检验矿产的流程是: 1 .给定m 个区间[Li ...
- 给WordPress Page页面添加摘要输入框
默认情况下 WordPress Page 编辑页面没有摘要(Excerpt)输入框,所以对 WordPress 进行 SEO 的时候比较麻烦. 这个时候我们就可以通过以下代码给我 WordPress ...
- 第9章 使用ssh服务管理远程主机。
章节简述: 学习使用nmtui命令配置网卡参数.手工将多块网卡做绑定.使用nmcli命令查看网卡信息和使用ss命令查看网络及端口状态. 完整演示sshd服务配置方法并详细讲述每个参数的作用,实战基于密 ...
- JdbcTemplate三种常用回调方法
JdbcTemplate针对数据查询提供了多个重载的模板方法,你可以根据需要选用不同的模板方法. 如果你的查询很简单,仅仅是传入相应SQL或者相关参数,然后取得一个单一的结果,那么你可以选择如下一组便 ...
- [OpenJudge 3061]Flip The Card
[OpenJudge 3061]Flip The Card 试题描述 There are N× Ncards, which form an N× Nmatrix. The cards can be p ...
- hiho一下 第九十六周 数论五·欧拉函数
题目1 : 数论五·欧拉函数 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 小Hi和小Ho有时候会用密码写信来互相联系,他们用了一个很大的数当做密钥.小Hi和小Ho约定 ...
- Bulb Switcher
There are n bulbs that are initially off. You first turn on all the bulbs. Then, you turn off every ...