SQL Server里强制参数化的痛苦
几天前,我写了篇SQL Server里简单参数化的痛苦。今天我想继续这个话题,谈下SQL Server里强制参数化(Forced Parameterization)。
强制参数化(Forced Parameterization)
在SQL Server里简单参数化有很多限制,如果你的SQL语句包含下列任意它不会发生:
- JOIN
- IN
- BULK INSERT
- UNION
- INTO
- DISTINCT
- TOP
- GROUP BY
- HAVING
- COMPUTE
- Sub Queries
如果你还想让SQL Server进行自动参数化,你可以启用在数据库层启用强制参数化:
-- Let's now activate Forced Parameterization on the AdventureWorks2012 database
ALTER DATABASE AdventureWorks2012 SET PARAMETERIZATION FORCED
GO
在这个情况下,SQL Server总会自动参数化你的SQL语句除掉以下情况:
- INSERT … EXECUTE
- Prepared SQL Statements
- RECOMPILE
- COMPUTE
为什么强制参数化总不是个好选择
现在让我们看下SQL Server里的强制参数化。对于AdventureWorks2012数据库,最后的代码已经将它启用强制参数化了。下一步我创建Sales.SalesOrderHeader表的副本,并将数据修正,这样的话在CustomerID列我们会有非线性的数据分布。另外我在那一列也创建了非聚集索引。
-- Create a copy from the Sales.SalesOrderHeader table
SELECT * INTO Sales.SalesOrderHeader2 FROM Sales.SalesOrderHeader
GO -- Create a Non-Clustered Index on the CustomerID column
CREATE NONCLUSTERED INDEX idx_CustomerID ON Sales.SalesOrderHeader2(CustomerID)
GO -- "Patch" the data in some way, so that the content of the column "CustomerID" is not evenly distributed across the whole table
UPDATE Sales.SalesOrderHeader2
SET CustomerID = 29675
WHERE SalesOrderID < 60000
GO
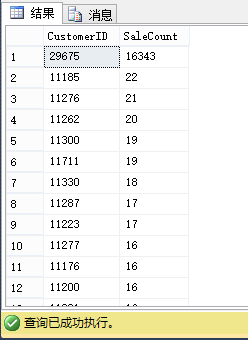
从下图你可以看到:ID为29675的客户有大量的订单,其它客户只有一些订单:
SELECT CustomerID,COUNT(SalesOrderID) SaleCount FROM Sales.SalesOrderHeader2
GROUP BY CustomerID ORDER BY 2 DESC
在下一步里我执行一个返回CustomerID为22943的所有记录——只有3条记录。因为查询在临界点前,SQL Server选择了有书签查找的执行计划。查询合计生成了3个逻辑读。因为我们对AdventureWorks2012数据库启用了强制参数化,对这个语句SQL Server也会自动参数化,因此执行计划会被后续的查询重用。
-- 3 Logical Reads
SELECT * FROM Sales.SalesOrderHeader2
WHERE CustomerID = 22943 -- Index Seek, returns 1 record
GO

我们再来运行另一个查询,返回所有CustomerID为29675的记录。在这个情况下查询返回16343条记录。当你再次看执行计划时,你会看到查询重用了刚才查询的执行计划。
SELECT * FROM Sales.SalesOrderHeader2
WHERE CustomerID = 29675
GO

这是对的,以为查询自动参数化,SQL Server在计划缓存里找已经缓存的计划。但是重用执行计划并不安全,因为现在我们进行了书签查找16343次——对每一行——反复执行。查询合计生成了16415个逻辑读。使用表扫描的话只要780个逻辑读。
这是强制参数化的副作用。SQL Server不管你执行计划的稳定性。SQL Server值自动参数化你的SQL语句,并反复重用缓存的执行计划。不管这个执行计划有糟糕。因为这是你强制SQL Server只要做的!没有启用强制参数化,SQL Server从不为你自动参数化SQL语句,因为那不安全。
性能问题的根源肯定是强制参数化。这里的根源是你的执行计划包含书签查找。因为书签查找你就没有计划稳定性。计划没有稳定性是说基于你输入参数值你会有不同的执行计划。在这个例子里有时你得到书签查找(临界点前),有时是表扫描(临界点后)。
在这个情况下,如果你修改下你的索引设计,为这个查询定义一个覆盖非聚集索引,性能问题也会消失。这样的话也不需要启用强制参数化,因为使用计划稳定性SQL Server会自动参数化你的SQL语句!
小结
在数据库级别启用强制参数化是个非常危险的事。不管你是否有计划稳定性,SQL Server总会自动参数化你的SQL语句,并反复重用你的执行计划。因此你要知道你的执行计划的详细情况,看看它们是否会引起性能相关的问题。
感谢关注!
参考文章:
https://www.sqlpassion.at/archive/2015/07/27/the-pain-of-forced-parameterization-in-sql-server/
SQL Server里强制参数化的痛苦的更多相关文章
- SQL Server里简单参数化的痛苦
在今天的文章里,我想谈下对于即席SQL语句(ad-hoc SQL statements),SQL Server使用的简单参数化(Simple Parameterization)的一些特性和副作用.首先 ...
- SQL Server里的闩锁介绍
在今天的文章里我想谈下SQL Server使用的更高级的,轻量级的同步对象:闩锁(Latch).闩锁是SQL Server存储引擎使用轻量级同步对象,用来保护多线程访问内存内结构.文章的第1部分我会介 ...
- SQL Server里ORDER BY的歧义性
在今天的文章里,我想谈下SQL Server里非常有争议和复杂的话题:ORDER BY子句的歧义性. 视图与ORDER BY 我们用一个非常简单的SELECT语句开始. -- A very simpl ...
- SQL Server里的自旋锁介绍
在上一篇文章里我讨论了SQL Server里的闩锁.在文章的最后我给你简单介绍了下自旋锁(Spinlock).基于那个基础,今天我会继续讨论SQL Server中的自旋锁,还有给你展示下如何对它们进行 ...
- SQL Server里在文件组间如何移动数据?
平常我不知道被问了几次这样的问题:“SQL Server里在文件组间如何移动数据?“你意识到这个问题:你只有一个主文件组的默认配置,后来围观了“SQL Server里的文件和文件组”后,你知道,有多 ...
- SQL Server里的文件和文件组
在今天的文章里,我想谈下SQL Server里非常重要的话题:SQL Server如何处理文件的文件组.当你用CREATE DATABASE命令创建一个简单的数据库时,SQL Server为你创建2个 ...
- 在SQL Server里我们为什么需要意向锁(Intent Locks)?
在1年前,我写了篇在SQL Server里为什么我们需要更新锁.今天我想继续这个讨论,谈下SQL Server里的意向锁,还有为什么需要它们. SQL Server里的锁层级 当我讨论SQL Serv ...
- 在SQL Server里为什么我们需要更新锁
今天我想讲解一个特别的问题,在我每次讲解SQL Server里的锁和阻塞(Locking & Blocking)都会碰到的问题:在SQL Server里,为什么我们需要更新锁?在我们讲解具体需 ...
- 在SQL Server里如何进行页级别的恢复
在今天的文章里我想谈下每个DBA应该知道的一个重要话题:在SQL Server里如何进行页级别还原操作.假设在SQL Server里你有一个损坏的页,你要从最近的数据库备份只还原有问题的页,而不是还原 ...
随机推荐
- Asp.Net实现FORM认证的一些使用技巧(转)
最近因为项目代码重构需要重新整理用户登录和权限控制的部分,现有的代码大体是参照了.NET的FORM认证,并结合了PORTAL KITS的登录控制,代码比较啰嗦,可维护性比较差.于是有了以下的几个需求( ...
- ASP.NET Web API模型验证以及异常处理方式
ASP.NET Web API的模型验证与ASP.NET MVC一样,都使用System.ComponentModel.DataAnnotations. 具体来说,比如有:[Required(Erro ...
- 软件设计之UML—UML的构成[上]
UML是一种通用的建模语言,其表达能力相当的强,不仅可以用于软件系统的建模,而且可用于业务建模以及其它非软件系统建模.UML综合了各种面向对象方法与表示法的优点,至提出之日起就受到了广泛的重视并得 ...
- 动态变化的OO设计
今天看到个题目:对象会动态的变化. 游戏精灵,有人和神仙,但是随着人的不断积分,会升级为神仙:神仙也可能会因为积分的减少而降级为人.这种情况怎么画出个类图来. 这是第一版的设计,正常思维.人和神仙都是 ...
- 分布式Hadoop安装(二)
二.集群环境安装Zookeeper 1. hadoop0,namenode机器下,配置zookeeper,先解压安装包. 使用命令:tar -zxvf zookeeper-3.4.4. ...
- 奇怪吸引子---WimolBanlue
奇怪吸引子是混沌学的重要组成理论,用于演化过程的终极状态,具有如下特征:终极性.稳定性.吸引性.吸引子是一个数学概念,描写运动的收敛类型.它是指这样的一个集合,当时间趋于无穷大时,在任何一个有界集上出 ...
- 利用 Python 只连接一次 MySQL
Github 地址 项目背景 最近做个项目,需要进行试驾分析,所谓"试驾",是指顾客在 4S 店指定人员的陪同下,沿着指定的路线驾驶车辆,从而了解这款汽车的行驶性能和操控性能.通常 ...
- Oracle Essbase入门系列(三)
数据库计算 Essbase中单元格的数据可以是外部输入或计算而得,单元格因而分为输入单元格和计算单元格.计算单元格的计算方法可以通过大纲中维度成员的合并计算符和公式脚本定义,此称为大纲计算定义. 例1 ...
- Visual Studio 2013 prerequisites
http://www.visualstudio.com/zh-cn/products/visual-studio-ultimate-with-msdn-vs#Fragment_SystemRequir ...
- System.Diagnostics.Debug和System.Diagnostics.Trace 【转】
在 .net 类库中有一个 system.diagnostics 命名空间,该命名空间提供了一些与系统进程.事件日志.和性能计数器进行交互的类库.当中包括了两个对开发人员而言十分有用的类——debug ...