别再滥用scrapy CrawlSpider中的follow=True
对于刚接触scrapy的同学来说, crawlspider中的rule是比较难理解的, 很可能驾驭不住. 而且笔者在YouTube中看到许多公开的演讲都都错用了follow这一选项, 所以今天就来仔细谈一谈.
首先我们看scrapy中的follow是如何实现的:
# 为了方便理解, 去除了不必要代码
def _requests_to_follow(self, response):
"""遍历rules, 使用rule提取response中的链接
每个rule中提取的链接都会被添加到集合中
相同的链接只会被提取一次, 也就是范围大的rule 会覆盖范围小的rule
使用提取到的链接发送请求, 得到response
"""
seen = set()
for n, rule in enumerate(self._rules):
links = [lnk for lnk in rule.link_extractor.extract_links(response)
if lnk not in seen]
for link in links:
seen.add(link)
r = Request(url=link.url, callback=self._response_downloaded)
yield r
def _response_downloaded(self, response):
rule = self._rules[response.meta['rule']]
return self._parse_response(response, rule.callback, rule.cb_kwargs, rule.follow)
首先, 在我们的定义中rules是一系列Rule对象的集合, 示例如下:
rules = (
Rule(LinkExtractor(allow=('category\.php', ), deny=('subsection\.php', ))),
Rule(LinkExtractor(allow=('item\.php', )), callback='parse_item'),
)
在源代码中, 我们可以看到:
- 遍历所有的Rule对象, 并使用其link_extractor属性提取链接
- 对于提取到的链接, 我们把它加入到一个集合中
- 使用链接发送一个请求, 并且callback的最终结果是self._parse_response
上述操作表明, 当我们follow一个链接时, 我们其实是用rules把这个链接返回的response再提取一遍.
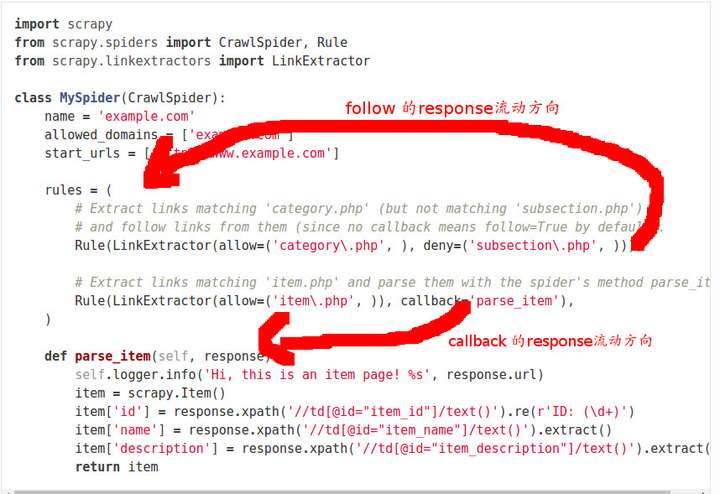
当我们需要对response进行进一步提取的时候我们才使用follow, 它会把response用rules过滤一遍, 产生新的response.
当我们的response包含有我们需要的信息是, 直接用callback提取信息.
不要滥用follow, 因为我们提取出来的链接都会被下载, 造成了不必要的请求.
其实源代码中还解释了文档中提到的关于rules顺序的问题:
Each Rule defines a certain behaviour for crawling the site. Rules objects are described below. If multiple rules match the same link, the first one will be used, according to the order they’re defined in this attribute.
多个Rule匹配同一个链接, 只有第一个Rule会被使用, 用源代码来解释就是我们匹配到了链接已经添加到set中去重了, 所以之后的匹配都无法添加. 所以我们在使用rules时, 如果两个Rule有交集, 要注意顺序.
别再滥用scrapy CrawlSpider中的follow=True的更多相关文章
- Scrapy框架中的CrawlSpider
小思考:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法二: ...
- scrapy CrawlSpider解析
CrawlSpider继承自Spider, CrawlSpider主要用于有规则的url进行爬取. 先来说说它们的设计区别: SpiderSpider 类的设计原则是只爬取 start_urls 中的 ...
- scrapy -->CrawlSpider 介绍
scrapy -->CrawlSpider 介绍 1.首先,通过crawl 模板新建爬虫: scrapy genspider -t crawl lagou www.lagou.com 创建出来的 ...
- Python+Scrapy+Crawlspider 爬取数据且存入MySQL数据库
1.Scrapy使用流程 1-1.使用Terminal终端创建工程,输入指令:scrapy startproject ProName 1-2.进入工程目录:cd ProName 1-3.创建爬虫文件( ...
- 再谈SQL Server中日志的的作用
简介 之前我已经写了一个关于SQL Server日志的简单系列文章.本篇文章会进一步挖掘日志背后的一些概念,原理以及作用.如果您没有看过我之前的文章,请参阅: 浅谈SQL Server ...
- 用python随机生成数据,再插入到postgresql中
用python随机生成学生姓名,三科成绩和班级数据,再插入到postgresql中. 模块用psycopg2 random import random import psycopg2 fname=[' ...
- C++ Primer 学习笔记_43_STL实践与分析(17)--再谈迭代器【中】
STL实践与分析 --再谈迭代器[中] 二.iostream迭代[续] 3.ostream_iterator对象和ostream_iterator对象的使用 能够使用ostream_iterator对 ...
- Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- 一定要 先删除 sc表 中的 某元组 行,,, 再删除 course表中的 元组行
一定要 先删除 sc表 中的 某元组 行,,, 再删除 course表中的 元组行 course表 SC表 删除 course表中的 元组行,,出现错误 sc ---->参 ...
随机推荐
- Word2Vec词向量(一)
一.词向量基础(一)来源背景 word2vec是google在2013年推出的一个NLP工具,它的特点是将所有的词向量化,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系.虽然源码是 ...
- OpenCV实现SIFT图像拼接源代码
OpenCV实现SIFT和KDtree和RANSAC图像拼接源代码,此源代码由Opencv2.4.13.6和VC++实现,代码本人已经调试过,完美运行,效果如附图.Opencv2.4.13.6下载地址 ...
- Caused by: redis.clients.jedis.exceptions.JedisDataException: WRONGTYPE Operation against a key holding the wrong kind of value
对错误类型key的操作,也就是说redis中没有你当前操作的这个key,而你用这个key去执行某些操作!检查key是否正确
- 在easyUI开发中,出现jquery.easyui.min.js函数库问题
easyUI是jquery的一个插件,是民间的插件.easyUI使用起来很方便,里面有网页制作的最重要的三大方块:javascript代码.html代码和Css样式.我们在导入easyUI库后,可以直 ...
- c# dll使用注意
1.dll路径最好不要用到中文,会报:尝试读取或写入受保护的内存.这通常指示其他内存已损坏.
- VFS dup ,dup2
Linux支持各种各样的文件系统格式,如ext2.ext3.reiserfs.FAT.NTFS.iso9660等等,不同的磁盘分区.光盘或其它存储设备都有不同的文件系统格式,然而这些文件系统都可以mo ...
- HDU 1798 Tell me the area
http://acm.hdu.edu.cn/showproblem.php?pid=1798 Problem Description There are two circles in the ...
- 关于aspnet_regsql使用方法
aspnet_regsql命令解释 说明该向导主要用于配置SQL Server数据库,如membership,profiles等信息,如果要配置SqlCacheDependency,则需要以命令行的方 ...
- C++关于堆的函数
建立堆 make_heap(_First, _Last, _Comp) 默认是建立最大堆的.对int类型,可以在第三个参数传入greater<int>()得到最小堆. 在堆中添加数据 ...
- P4109 [HEOI2015]定价
题目描述 在市场上有很多商品的定价类似于 999 元.4999 元.8999 元这样.它们和 1000 元.5000 元和 9000 元并没有什么本质区别,但是在心理学上会让人感觉便宜很多,因此也是商 ...