爬虫实战【4】Python获取猫眼电影最受期待榜的50部电影
前面几天介绍的都是博客园的内容,今天我们切换一下,了解一下大家都感兴趣的信息,比如最近有啥电影是万众期待的?
猫眼电影是了解这些信息的好地方,在猫眼电影中有5个榜单,其中最受期待榜就是我们今天要爬取的对象。这个榜单的数据来源于猫眼电影库,按照之前30天的想看总数量从高到低排列,取前50名。
我们先看一下这个表单中包含什么内容:
【插入图片,6猫眼榜单示例】
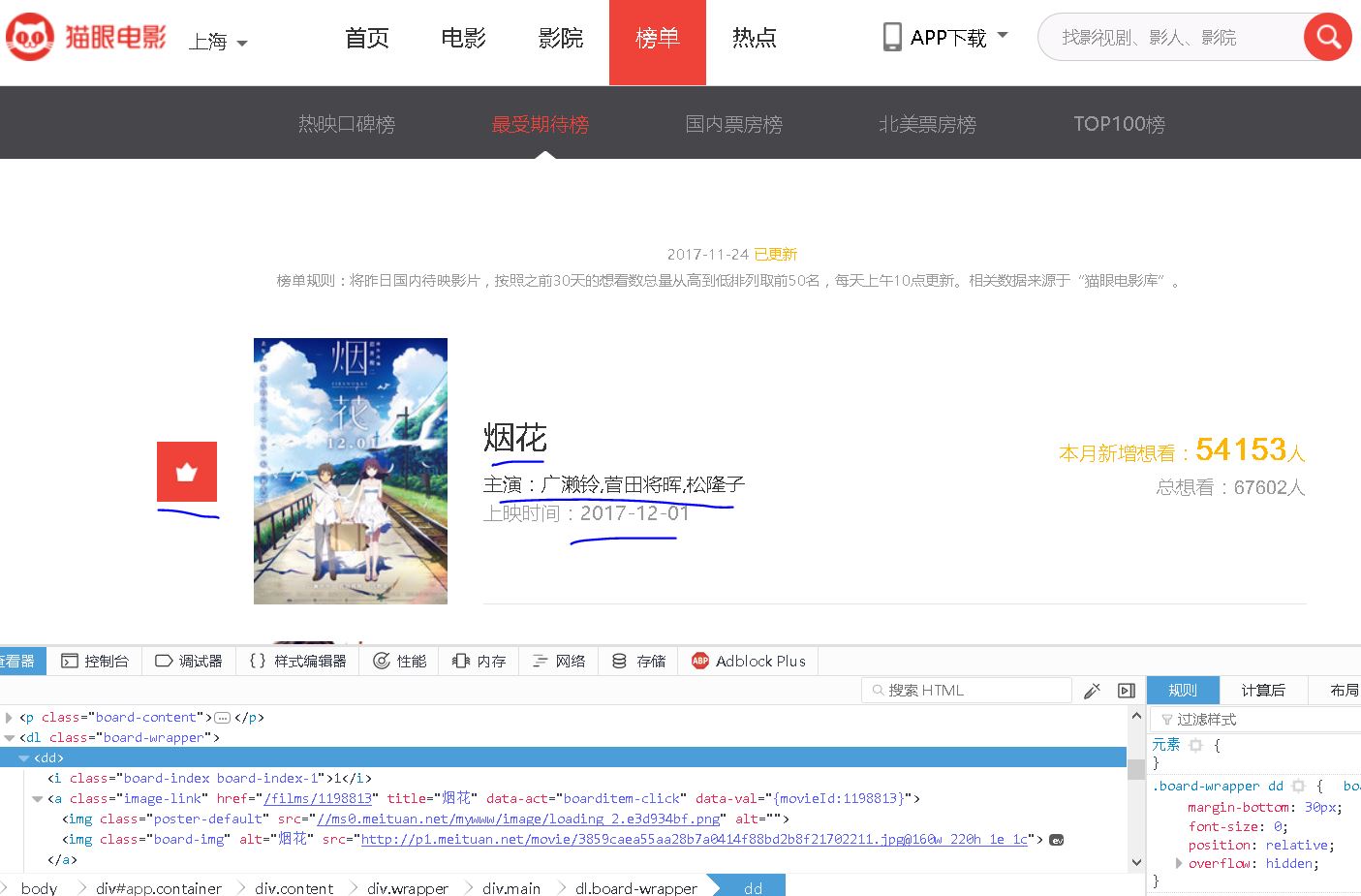
具体的信息有”排名,电影海报,电影名称,主演,上映时间“以及想看人数,今天我们主要关注前面5个信息的收集。
之前我们用正则表达式,在网页源代码中匹配了某一篇文章的标题,大家可能还有印象,这次我们还要用正则表达式来一次爬取多个内容。
另外,也尝试一下requests库。
第一步 如何获取网页的源码?
我们先分析一下这个榜单页面,跟之前博客园的大概是类似的。
url=http://maoyan.com/board/6?offset=0
上面是第一页的榜单地址,我们一眼就关注到了offset这个值,毫无疑问,后面的页面都是将offset改变就能获取到了。
来看一下第二页:
http://maoyan.com/board/6?offset=10
不一样的地方,offset每次增加了10,而不是之前博客园中的1.
无所谓,都是小case。
来来来,我们使用requests来爬一下第一页的源码看看。
import requests
#初始的代码
def get_html(url):
response=requests.get(url)
if response.status_code==200:
html=response.content.decode('utf-8')
return html
else:
return None
requests的get方法返回了一个response对象,我们根据这个response的状态码status_code就可以判断是否返回正常,200一般是OK的。
然后要对返回的内容解码,decode为utf-8的格式。
打印一下,看看得到什么结果。
【插入图片,1显示请求错误】
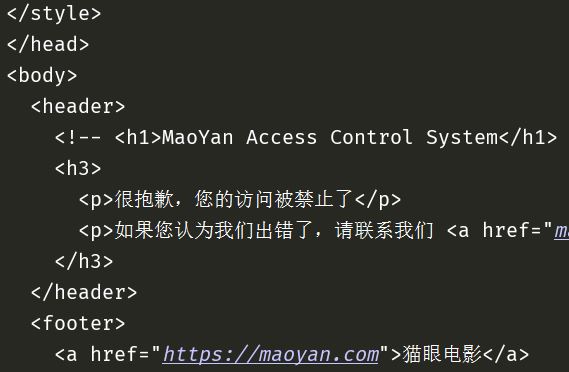
竟然失败了,被禁止访问了。
估计是猫眼设置了反爬虫,不过应该比较容易解决,我们看一下get方法的请求头信息。(在FireFox里面按F12,打开调试,点击网络,先把已经加载的内容删除,刷新一下页面,我们只看html格式的返回,如下图所示。
【插入图片,2user-agent】
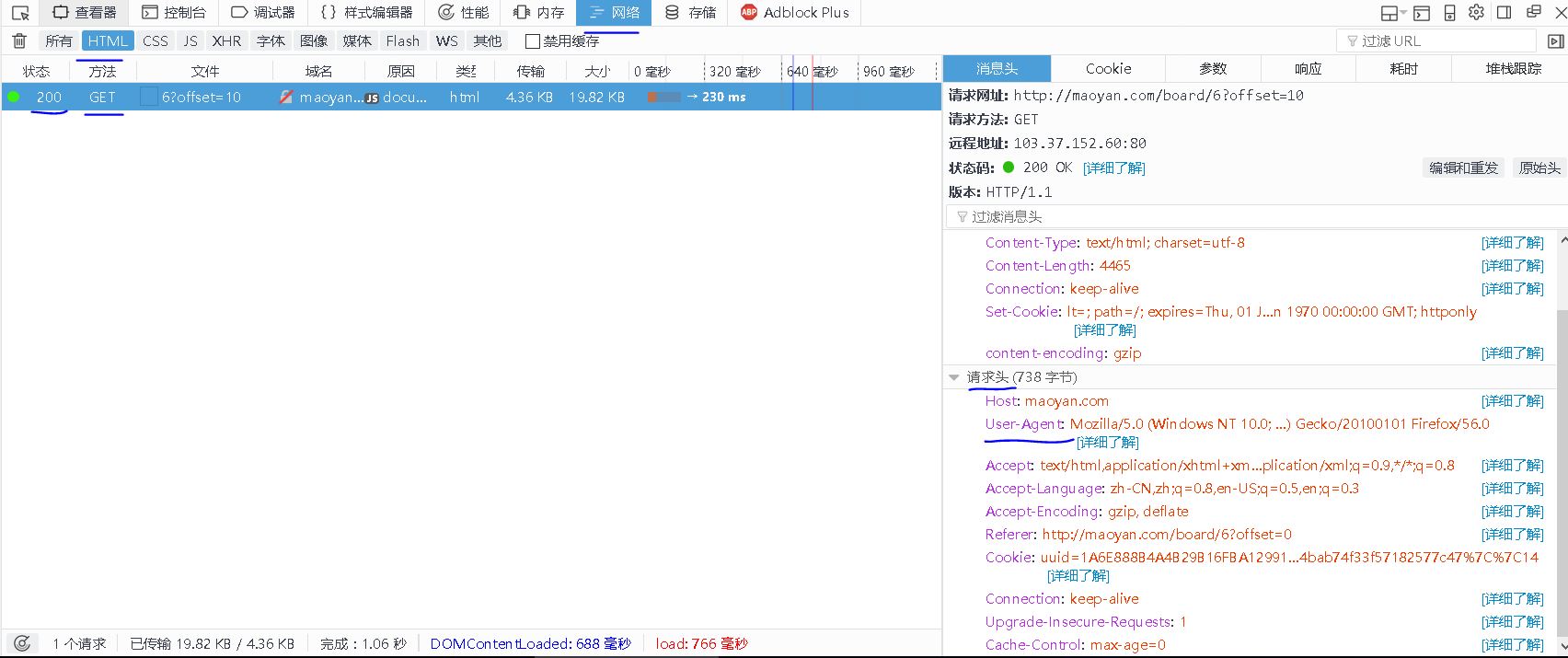
我们先给requests添加一个user-agent的头信息,尝试一下能否获取到源码信息。
import requests
#改进后的代码,插入headers
def get_html(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.79 Safari/537.36 Edge/14.14393'
}
response=requests.get(url,headers=headers)
if response.status_code==200:
html=response.content.decode('utf-8')
return html
else:
return None
好了,成功了,获取到了网页源码
【插入图片,获取源码成功】

第二步 解析获取的源码
得到源码后,就可以开始解析了,我们要得到的5个信息,包括排名、海报、名称、主演和上映时间等信息。
【插入图片 5某一电影标签的内容】
所有的内容包含在一个dd标签内。
我们想要用正则表达式来获取这5个信息,就要用到分组的格式,详见前面对正则表达式的介绍。
r'<dd.*?board-index.*?">(\d+)</i.*?data-src="(.*?)".*?<p class="name"><a.*?>(.*?)</a>.*?<p class="star">(.*?)</p.*?class="releasetime">(.*?)</p.*?</dd>'
这个pattern有点长,我们主要关注5个()里面的内容,这就是我们要获取的5个信息。
使用re的findall方法来匹配整个源码,会得到一个list,里面有这5个内容。
但是每一页上有10个电影,假如每个电影一个item,那么我们会得到有10个item组成的一个list。
代码如下:
def parse_html(html):
#为什么一定要开启非贪婪模式?
pattern=re.compile('<dd.*?board-index.*?">(\d+)</i.*?data-src="(.*?)".*?<p class="name"><a.*?>(.*?)</a>.*?<p class="star">(.*?)</p.*?class="releasetime">(.*?)</p.*?</dd>',re.S)
items=re.findall(pattern,html)
result=[]
for item in items:
result.append({
'排名':item[0],
'海报':item[1],
'名称':item[2],
'主演':item[3].strip()[3:],
'上映时间':item[4].strip()[5:]
})
return result
尤其要注意的是,.*表示可以匹配任意数量的字符,这个匹配是贪婪的,我们要在后面加上一个?才能保证匹配到第一个符合的内容就结束。
一开始没有注意,导致匹配失败很多次。
另外,由于获取主演的内容是这样的"主演:XXXXX",所以要对list切片,把前面3个字符去掉。
上映时间也是同样的道理。
这样,对一个页面的解析就完成了。
第三步 保存信息
之前我们尝试过将信息保存在文本中,今天试一下json。
因为我们要保存的内容中有中文信息,所以在写入的时候设置编码为utf-8,同时在json的dump方法中设置ascii为False。
def save_one_page(offset_no):
url=url_base+str(offset_no)
html=get_html(url)
items=parse_html(html)
for item in items:
print(item)
with open('most wanted.json','a',encoding='utf-8') as f:
json.dump(item,f,ensure_ascii=False)
第四步 开启多进程
如果想要提高运行效率,我们可以开始多进程,尤其对于这种多页、多条目的下载情况。当然我们目前的情况并不是十分要求,以备后面的情况。
Windows下,python的multiprocessing模块,提供了一个Process类来代表一个进程对象。
创建子进程时,只需要传入一个执行函数名和函数的参数,创建一个Process实例,用start()方法启动,join方法可以等待子进程结束后在继续往下运行。举个栗子:
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
#target是要运行的函数名称,args是传入的参数,可以看出是一个元组,
#如果只有一个参数,后面要加一个逗号
p = Process(target=run_proc, args=('test',))
print('Process will start.')
p.start()
p.join()
print('Process end.')
如果要启动大量的子进程,可以用进程池的方式批量创建子进程,这里的进程池就是multiprocessing模块中的Pool类。
如果使用进程池的话,就不要使用start方法了,使用apply或者apply_async方法,async是
举个例子:
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Pool()
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
根据上面的说明,我们的代码应该如下所示:
if __name__=='__main__':
pool = Pool()
for i in range(5):
pool.apply_async(save_one_page,args=(i*10,))
pool.close()
pool.join()
#map函数是python中的一种内置函数,用法后面再介绍
#pool.map(save_one_page, [i * 10 for i in range(5)])
至此为止,我们的代码就全部完成了。
附上效果图:【插入图片,结果】

未完成
但是仍然有一个内容,没有达到我的目标。
【插入图片,乱码】

【插入图片,对应数字】
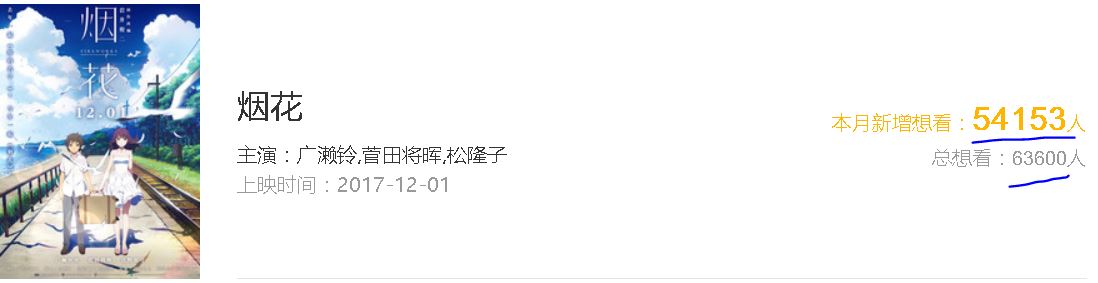
&#x格式的编码,一直没有搞清楚,否则就能得到总共想看该电影的人数了。
这个东西后面一定会解决的。

爬虫实战【4】Python获取猫眼电影最受期待榜的50部电影的更多相关文章
- Python 爬取猫眼电影最受期待榜
主要爬取猫眼电影最受期待榜的电影排名.图片链接.名称.主演.上映时间. 思路:1.定义一个获取网页源代码的函数: 2.定义一个解析网页源代码的函数: 3.定义一个将解析的数据保存为本地文件的函数: ...
- requests库爬取猫眼电影“最受期待榜”榜单 --网络爬虫
目标站点:https://maoyan.com/board/6 # coding:utf8 import requests, re, json from requests.exceptions imp ...
- Python:爬虫之利用Python获取指定网址上的所有图片—Jaosn niu
# coding=gbk import urllib.request import re import os import urllib def getHtml(url): #指定网址获取函数 pag ...
- 爬虫实战【11】Python获取豆瓣热门电影信息
之前我们从猫眼获取过电影信息,而且利用分析ajax技术,获取过今日头条的街拍图片. 今天我们在豆瓣上获取一些热门电影的信息. 页面分析 首先,我们先来看一下豆瓣里面选电影的页面,我们默认选择热门电影, ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
- Python实战:Python爬虫学习教程,获取电影排行榜
Python应用现在如火如荼,应用范围很广.因其效率高开发迅速的优势,快速进入编程语言排行榜前几名.本系列文章致力于可以全面系统的介绍Python语言开发知识和相关知识总结.希望大家能够快速入门并学习 ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- python爬虫:爬取猫眼TOP100榜的100部高分经典电影
1.问题描述: 爬取猫眼TOP100榜的100部高分经典电影,并将数据存储到CSV文件中 2.思路分析: (1)目标网址:http://maoyan.com/board/4 (2)代码结构: (3) ...
- Python 爬虫实战(1):分析豆瓣中最新电影的影评
目标总览 主要做了三件事: 抓取网页数据 清理数据 用词云进行展示 使用的python版本是3.6 一.抓取网页数据 第一步要对网页进行访问,python中使用的是urllib库.代码如下: from ...
随机推荐
- 工作笔记4.struts2上传文件到server
本文介绍两种:上传文件到server的方式 一种是提交Form表单:还有一种是ajaxfileupload异步上传. 一.JSP中: 1.提交Form表单 为了能完毕文件上传,我们应该将这 ...
- Eclipse下Java Build Path下Libraies中添加 Maven dependencies 失败解决方案
当maven 仓库有jar时,tomcat生成时总是报javaclassno..........无这个文件:用一下方法 转载:http://bugyun.iteye.com/blog/2311848 ...
- Centos下Subversion 服务器安装配置
1.安装 # yum install subversion 2. svn配置 建立svn版本库目录可建多个:2.1 新建文件夹: # mkdir -p /opt/svndata/repos 2.2 建 ...
- iframe元素获取
应用场景:main.jsp 中有Iframe,其中包含 home.jsp,在main.jsp中的dom元素绑定的方法操作home.jsp中元素.或反之操作.
- vc2010, fatal error LNK1123: failure during conversion to COFF: file invalid or corrupt解决办法
是因为安其它软件的时候更新了.net framework,导致vc2010出了问题. 解决办法是在系统里搜索cvtres.exe,会搜到很多,把其中 Microsoft Visual Studio 1 ...
- NIO之Charset类字符编码对象
Charset类字符编码对象 介绍 java中使用Charset来表示编码对象 This class defines methods for creating decoders and encoder ...
- 英语每日一句: What’s your point? 你究竟想说什么?
今天我们要学习的一句话是:What's your point? 你究竟想说什么?这句话在日常交流中非经常见,当对方说了非常多东西你仍不明确他究竟是什么意思时.你就能够问What's your poin ...
- codeforces 183B - Zoo
/* 题意:给出n,m. n表示给出的n个横坐标为1-n,y为0的坐标m表示以下有m个坐标,在横坐标上的点 向各个角度看,在可以看到最多的点在同一条直线上的点的做多值为横坐标这一点的值,最后各个 横坐 ...
- C# 泛型 default()方法
在泛型类和泛型方法中产生的一个问题是,在预先未知以下情况时,如何将默认值分配给参数化类型 T: T 是引用类型还是值类型. 如果 T 为值类型,则它是数值还是结构. 给定参数化类型 T 的一个变量 t ...
- hdu5802 Windows 10 贪心
Windows 10 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total ...