初学Hadoop之中文词频统计
1、安装eclipse
准备
eclipse-dsl-luna-SR2-linux-gtk-x86_64.tar.gz
安装
1、解压文件。
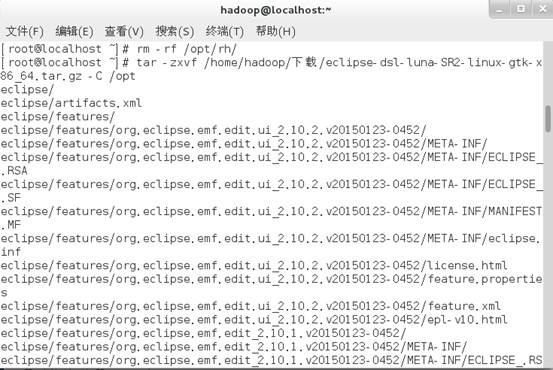
2、创建图标。
ln -s /opt/eclipse/eclipse /usr/bin/eclipse #使符号链接目录
vim /usr/share/applications/eclipse.desktop #创建一个 Gnome 启动

添加如下代码:
[Desktop Entry]
Encoding=UTF-8
Name=Eclipse 4.4.2
Comment=Eclipse Luna
Exec=/usr/bin/eclipse
Icon=/opt/eclipse/icon.xpm
Categories=Application;Development;Java;IDE
Version=1.0
Type=Application
Terminal=0

完成以后则会出现下图中的图标。

至此,eclipse安装完成。
2、安装hadoop插件
1、下载插件http://pan.baidu.com/s/1ydUEy 。
2、将插件放到/opt/eclipse/plugins文件夹下。
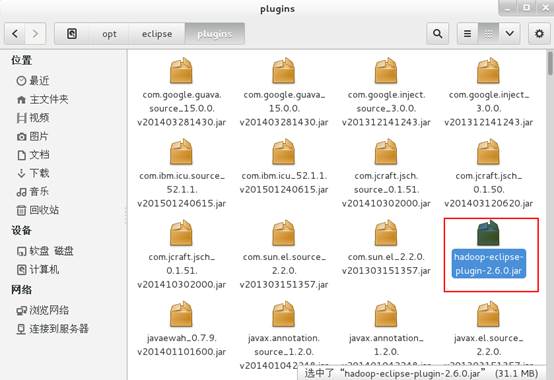
3、在eclipse->Windows->preferences设置Hadoop路径。
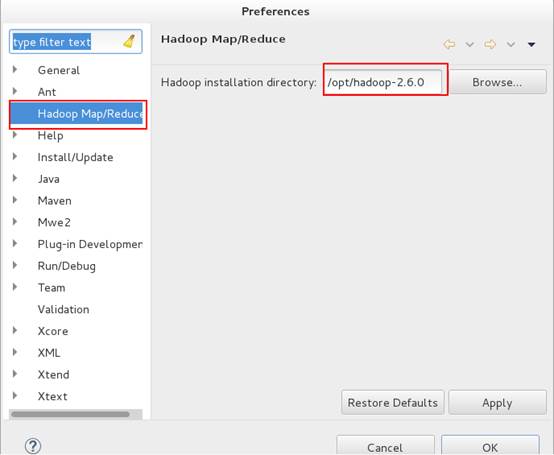
至此,插件安装完成。
3、ChineseWordCount源码
package com.example.test; import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import java.io.ByteArrayInputStream; import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class ChineseWordCount { public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context)
throws IOException, InterruptedException { byte[] bt = value.getBytes();
InputStream ip = new ByteArrayInputStream(bt);
Reader read = new InputStreamReader(ip);
IKSegmenter iks = new IKSegmenter(read, true);
Lexeme t;
while ((t = iks.next()) != null) {
word.set(t.getLexemeText());
context.write(word, one);
}
}
} public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(ChineseWordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4、创建Hadoop工程
1、创建一个Map/Reduce Project,名称为ChineseWordCount。
2、创建包com.example.test,创建ChineseWordCount类文件。
3、导入IkAnalyzer包。
下载地址:http://code.google.com/p/ik-analyzer/
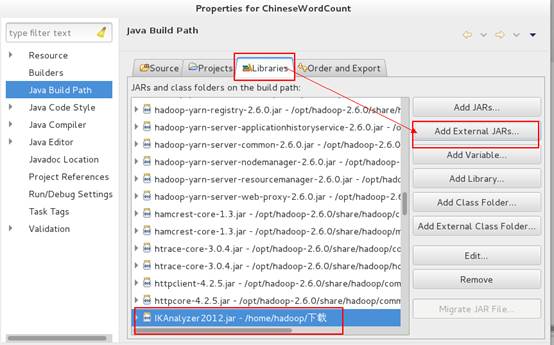
至此,Hadoop工程新建完成。
5、运行工程
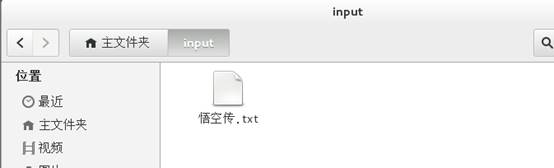
1、在/home/hadoop/目录下新建一个input文件夹,将中文文本"悟空传.txt"复制到里面。

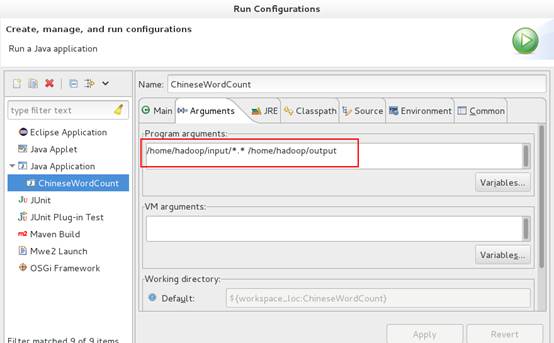
2、在eclipse中设置运行参数。
操作时遇到一个问题,当运行参数设置成/opt/hadoop-2.6.0/input/*.* /opt/hadoop-2.6.0/output时,无法运行成功,我想会不会是访问权限的问题,这个下次再解决。
3、点击运行。
6、查看结果

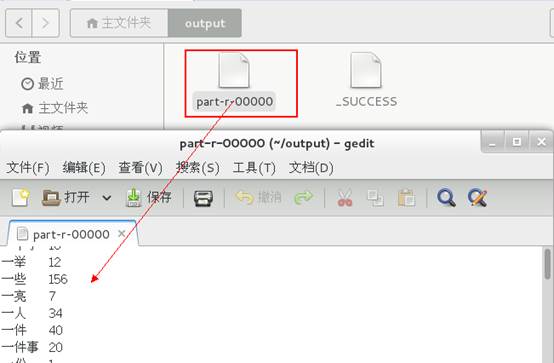
至此,中文词频统计运行成功。
7、总结
这次的中文词频统计只是一个简单的实验,还需要继续完善统计功能,比如词频数量的排序,去除单字统计等等。这方面我接触的还不深,希望有经验的朋友能给我一些学习建议和意见,谢谢。
初学Hadoop之中文词频统计的更多相关文章
- 初学Hadoop之WordCount词频统计
1.WordCount源码 将源码文件WordCount.java放到Hadoop2.6.0文件夹中. import java.io.IOException; import java.util.Str ...
- Python中文词频统计
以下是关于小说的中文词频统计 这里有三个文件,分别为novel.txt.punctuation.txt.meaningless.txt. 这三个是小说文本.特殊符号和无意义词 Python代码统计词频 ...
- 如何用java完成一个中文词频统计程序
要想完成一个中文词频统计功能,首先必须使用一个中文分词器,这里使用的是中科院的.下载地址是http://ictclas.nlpir.org/downloads,由于本人电脑系统是win32位的,因此下 ...
- Java实现中文词频统计
昨日有个中文词频统计的需求, 百度一番后, 发现一大堆标题党文章, 讲的与内容严重不符, 这里就简单记录下自己实现的流程吧! 与英文单词的词频统计不同, 中文的难点在于如何分词, 不过好在有许多优秀的 ...
- jieba (中文词频统计) 、collections (字频统计)、WordCloud (词云)
py库: jieba (中文词频统计) .collections (字频统计).WordCloud (词云) 先来个最简单的: # 查找列表中出现次数最多的值 ls = [1, 2, 3, 4, 5, ...
- py库: jieba (中文词频统计) 、collections (字频统计)、WordCloud (词云)
先来个最简单的: # 查找列表中出现次数最多的值 ls = [1, 2, 3, 4, 5, 6, 1, 2, 1, 2, 1, 1] ls = ["呵呵", "呵呵&qu ...
- Python实现简单中文词频统计示例
简单统计一个小说中哪些个汉字出现的频率最高: import codecs import matplotlib.pyplot as plt from pylab import mpl mpl.rcPar ...
- Programming | 中/ 英文词频统计(MATLAB实现)
一.英文词频统计 英文词频统计很简单,只需借助split断句,再统计即可. 完整MATLAB代码: function wordcount %思路:中文词频统计涉及到对"词语"的判断 ...
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
随机推荐
- 自定义类型转换器 及 使用 ServletAPI 对象作为方法参数
自定义类型转换器使用场景: jsp 代码: <!-- 特殊情况之:类型转换问题 --> <a href="account/deleteAccount?date=2018- ...
- 用HTML,css完成的百叶窗效果,新手必看
<!DOCTYPE html><html> <head> <meta charset="utf-8"> <title> ...
- loj #107. 维护全序集
#107. 维护全序集 题目描述 这是一道模板题,其数据比「普通平衡树」更强. 如未特别说明,以下所有数据均为整数. 维护一个多重集 S SS ,初始为空,有以下几种操作: 把 x xx 加入 S S ...
- 1. 时间复杂度(大O表示法)以及使用python实现栈
1.时间复杂度(大O表示法): O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n) < O(n! ...
- struts2的主要工作流程
struts2的框架结构图 struts2的主要工作流程: 1.客户端请求一个HttpServletRequest的请求,如在浏览器中输入http://localhost: 8080/bookcode ...
- 谈谈php中抽象类和接口的区别
php中抽象类和接口的区别 1) 概念 面向对象的三大概念:封装,继承,多态 把属性和方法封装起来就是类. 一个类的属性和方法被另外的类复制就是继承,PHP里面的任何类都可以被继承,被继 ...
- Qt 学习之路 2(45):模型
Home / Qt 学习之路 2 / Qt 学习之路 2(45):模型 Qt 学习之路 2(45):模型 豆子 2013年2月26日 Qt 学习之路 2 23条评论 在前面两章的基础之上,我们 ...
- CSS3 选择器 修改 整数个样式
.blogbottom ul li:nth-child(4n){margin-right:0px;} 说明:4n就是每第4个.
- I Hate It(线段树区间最值,单点更新)-------------蓝桥备战系列
很多学校流行一种比较的习惯.老师们很喜欢询问,从某某到某某当中,分数最高的是多少. 这让很多学生很反感. 不管你喜不喜欢,现在需要你做的是,就是按照老师的要求,写一个程序,模拟老师的询问.当然,老 ...
- poj1182 食物链 带权并查集
题目传送门 题目大意:大家都懂. 思路: 今天给实验室的学弟学妹们讲的带权并查集,本来不想细讲的,但是被学弟学妹们的态度感动了,所以写了一下这个博客,思想在今天白天已经讲过了,所以直接上代码. 首先, ...