前言:
普通人有三件东西看不懂:医生的处方,道士的鬼符,程序员得正则表达式
什么是正则表达式?
- 正则表达式,又称规则表达式,英文名为Regular Expression,在代码中常简写为regex、regexp或RE,
- 是计算机科学的一个概念。
- 许多程序设计语言都支持利用正则表达式进行字符串操作。
- 例如,在Python中就内建了一个功能强大的正则表达式接口擎。
- 正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。
- 正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。
- 正则就是用有限的符号,处理表达无限的序列
有什么作用?
- 正则表通常被用来检索、替换那些符合某个模式(规则)的文本。
- 正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))
- 操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,
- 组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
- 正则表达式是一种文本模式,模式描述在搜索文本时要匹配的一个或多个字符串。
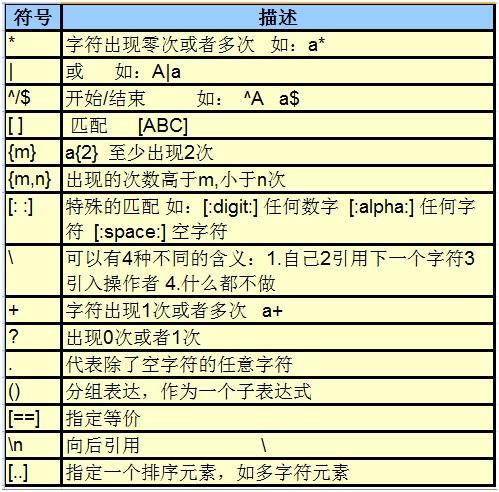
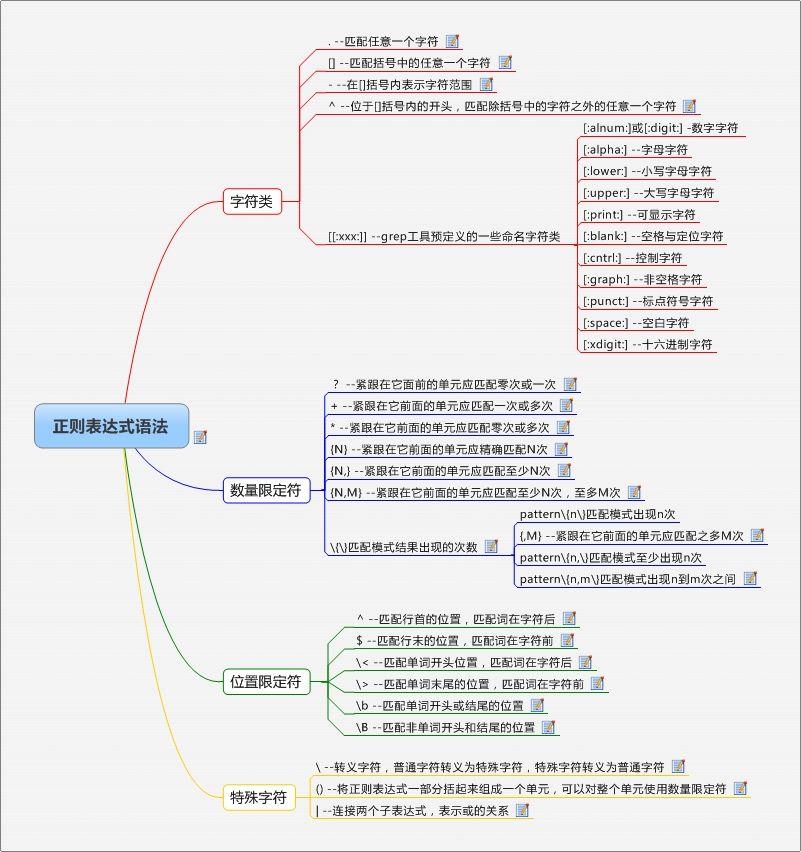
正则表达式语法:
正则表达式:
动机:
1. 文本处理已经成为计算机常见工作之一
2. 对文本的搜索,定位,提取的逻辑往往比较复杂
3. 为了解决上述问题,产生正则表达式技术
定义 :
正则表达式即文本的高级匹配模式,提供搜索,替代,获取等功能。
本质是由一系列特属符号和字符 构成的字串,这个字串就是正则表达式。
特点
* 方便进行检索和修改等文本操作
* 支持语言众多
* 灵活多样
正则表达式匹配手段:
通过设定有特殊意义的符号,描述符号和字符的
重复行为及位置特征来表示一类特定规则的字符串
python ---> re模块 处理正则表达式
re.findall(pattern,string)
参数:
pattern :
以字符串形式传入一个正则表达式
string :
要匹配的目标字符串
返回值 : 得到列表,将目标字串中能用正则匹配的内容放入列表
正则表达式元字符:
1. 普通字符匹配 :
(除了后续讲解的特殊字符全是普通字符)
可以用普通字符来匹配对应的字符
In [11]: re.findall("abc",'abcdefghabi')
Out[11]: ['abc']
In [12]: re.findall("成都",'成都的街头走一走')
Out[12]: ['成都']
2. 或:
元字符: |
匹配规则: 匹配符号两侧的正则表达式均可
In [14]: re.findall("ab|cd",'abcdefghabi')
Out[14]: ['ab', 'cd', 'ab']
3. 匹配单个字符:
元字符: .
匹配规则: 匹配除 \n 外任意一个字符
f.o ---> foo fao f@o
In [18]: re.findall("w.o",'woo,wao is not wbo')
Out[18]: ['woo', 'wao', 'wbo']
4. 匹配开始位置:
元字符: ^
匹配规则: 匹配目标字符串的开头位置
In [20]: re.findall("^Jame","Jame,how are you")
Out[20]: ['Jame']
5. 匹配结束位置:
元字符 : $
匹配规则: 匹配目标字符串的结束位置
In [23]: re.findall("py$","hello.py")
Out[23]: ['py']
6. 匹配重复:
元字符 : *
匹配规则: 匹配前面出现的正则表达式0次或多次
fo* ----> f fo fooooooooooooooooooo
In [31]: re.findall("ab*","abcdefae&65abbbbbbbb")
Out[31]: ['ab', 'a', 'abbbbbbbb']
7. 匹配重复:
元字符 : +
匹配规则: 匹配前面出现的正则表达式1次或多次
ab+ ---》 ab abbbbb
In [33]: re.findall(".+py$","hello.py")
Out[33]: ['hello.py']
8. 匹配重复:
元字符 : ?
匹配规则: 匹配前面出现的正则表达式0次或1次
ab? ---> a ab
In [36]: re.findall("ab?","abcea,adsfabbbbbb")
Out[36]: ['ab', 'a', 'a', 'ab']
9. 匹配重复:
元字符: {n}
匹配规则: 匹配前面的正则出现n次
ab{3} ---> abbb
In [39]: re.findall("ab{3}","abcea,adsfabbbbbb")
Out[39]: ['abbb']
10. 匹配重复:
元字符 : {m,n}
匹配规则 : 匹配前面的正则m-n次
ab{3,5} ---> abbb abbbb abbbbb
In [45]: re.findall("ab{3,5}","ab abbb abbbbabbbbbb")
Out[45]: ['abbb', 'abbbb', 'abbbbb']
11. 匹配字符集合:
元字符: [字符集]
匹配规则: 匹配字符集中任意一个字符
[abc123] --> a b c 1 2 3
In [46]: re.findall("[aeiou]","hello world")
Out[46]: ['e', 'o', 'o']
[0-9] [a-z] [A-Z] [0-9a-z]
In [47]: re.findall("^[A-Z][a-z]*","Hello world")
Out[47]: ['Hello']
[_abc0-9]
12. 匹配字符集:
元字符: [^...]
匹配规则:匹配除了中括号中字符集字符之外的任意一个字符
In [50]: re.findall("[^0-9]+","hello1")
Out[50]: ['hello']
13. 匹配任意(非)数字字符:
元字符 : \d \D
匹配规则: \d 匹配任意一个数字字符 [0-9]
\D 匹配任意一个非数字字符 [^0-9]
In [52]: re.findall("1\d{10}","13717776561")
Out[52]: ['13717776561']
In [53]: re.findall("\D+","hello world")
Out[53]: ['hello world']
14. 匹配任意(非)普通字符 :
(数字字母下划线 普通utf-8字符)
元字符 : \w \W
匹配规则: \w 匹配一个普通字符
\W 匹配一个非普通字符
In [54]: re.findall("\w+","hello$1")
Out[54]: ['hello', '1']
In [55]: re.findall("\W+","hello$1")
Out[55]: ['$']
15. 匹配(非)空字符:
(空格, \r \n \t \v \f)
元字符: \s \S
匹配规则: \s 匹配任意空字符
\S 匹配任意非空字符
In [59]: re.findall("\w+\s+\w+","hello world")
Out[59]: ['hello world']
In [61]: re.findall("\S+","hello world")
Out[61]: ['hello', 'world']
16. 匹配起止位置:
元字符: \A \Z
匹配规则: \A 匹配字符串开头位置 ^
\Z 匹配字符串结尾位置 $
In [63]: re.findall("\Ahi","hi,Tom")
Out[63]: ['hi']
In [2]: re.findall("is\Z",'This')
Out[2]: ['is']
完全匹配 : 使用一个正则表达式可以匹配目标字符串的全部内容
In [6]: re.findall("\A\w{5}\d{3}\Z",'abcde123')
Out[6]: ['abcde123']
17. 匹配(非)单词边界:
(普通字符和非普通字符的交接位置认为是单词边界)
元字符 : \b \B
匹配规则 : \b 匹配单词边界位置
\B 匹配非单词边界位置
In [17]: re.findall(r"\bis\b",'This is a test')
Out[17]: ['is']
元字符总结:
匹配单个字符 :
a . [...] [^...] \d \D \w \W \s \S
匹配重复:
* + ? {n} {m,n}
匹配位置:
^ $ \A \Z \b \B
其他 :
| () \
正则表达式的转义:
正则表达式特殊字符:
. * ? $ ^ [] {} () \
在正则表达式中如果想匹配这些特殊字符需要进行转义
In [23]: re.findall("\[\d+\]",'abc[123]')
Out[23]: ['[123]']
raw 字符串 ---》 原始字符串
特点 : 对字符串中的内容不进行转义,即表达原始含义
让转义符无效
r"\b" ---> \b
"\\b" ---> \b
In [39]: re.findall("\\w+@\\w+\\.cn",'lvze@tedu.cn')
Out[39]: ['lvze@tedu.cn']
In [40]: re.findall(r"\w+@\w+\.cn",'lvze@tedu.cn')
Out[40]: ['lvze@tedu.cn']
贪婪和非贪婪:
贪婪模式 :
正则表达式的重复匹配,总是尽可能多的向后匹配内容。
* + ? {m,n}
贪婪 ---》 非贪婪(懒惰) 尽可能少的匹配内容
*? +? ?? {m,n}?
In [46]: re.findall(r"ab*?",'abbbbbbbbbb')
Out[46]: ['a']
In [47]: re.findall(r"ab+?",'abbbbbbbbbb')
Out[47]: ['ab']
正则表达式分组:
使用()可以为正则表达式建立子组,子组不会影响正则
表达式整体的匹配内容,可以被看做是一个内部单元。
子组的作用:
1. 形成内部整体,该表某些元字符的行为
In [52]: re.search(r"(ab)+",'abababab').group()
Out[52]: 'abababab'
re.search(r"\w+@\w+\.(com|cn)",'Python@tedu.cn').group()
2. 子组匹配内容可以被单独获取
re.search(r"\w+@\w+\.(com|cn)",'lvze@tedu.com').group(1)
Out[59]: 'com'
子组注意事项:
* 一个正则表达式中可以有多个子组,区分第一,第二。。。子组
* 子组不要出现重叠的情况,尽量简单
捕获组和非捕获组 (命令组,未命名组)
捕获格式 :(?P<name>pattern)
re.search(r"(?P<dog>ab)+",'abababab').group()
作用 :
1 方便通过名字区分每个子组
2 捕获组可以重复调用
调用格式:(?P=name)
P<dog>ab)cd(?P=dog) ===> abcdab
In [69]: re.search(r"(?P<dog>ab)cdef(?P=dog)",'abcdefab').group()
Out[69]: 'abcdefab'
正则表达式的匹配原则:
1. 正确性 能够正确匹配目标字符串
2. 唯一性 除了匹配的目标内容,尽可能不会有不需要的 内容
3. 全面性 对目标字符串可能的情况要考虑全面不漏
re模块的使用:
regex = re.compile(pattern,flags = 0)
功能 :
生成正则表达式对象
参数 :
pattern 正则表达式
flags 功能标志位,丰富正则表达式的匹配
返回值:
返回一个正则表达式对象
re.findall(pattern,string,flags = 0)
功能 :
根据正则表达式匹配目标字串内容
参数 :
pattern 正则表达式
string 目标字符串
返回值:
列表 里面是匹配到的内容
如果正则表达式有子组,则只返回子组中的内容
regex.findall(string,pos,endpos)
功能 :
根据正则表达式匹配目标字串内容
参数 :
string 目标字符串
pos,endpos : 截取目标字符串的起止位置进行匹 配,默认是整个字符串
返回值:
列表 里面是匹配到的内容
如果正则表达式有子组,则只返回子组中的内容
re.split(pattern,string,flags = 0)
功能 :
通过正则表达式切割目标字符串
参数 :
pattern 正则
string 目标字串
返回值 :
以列表形式返回切割后的内容
re.sub(pattern,replace,string,max,flags)
功能:
替换正则表达式匹配内容
参数:
pattern 正则
replace 要替换的内容
string 目标字符串
max 设定最多替换几处
返回值 :
替换后的字符串
re.subn(pattern,replace,string,max,flags)
功能和参数同sub
返回值多一个实际替换了几处
re.finditer(pattern,string,flags)
功能:
使用正则匹配目标字串
参数:
pattern 正则
string 目标字串
返回值:
迭代对象 ----》 迭代内容为match对象
re.fullmatch(pattern,string,flags)
功能 :
完全匹配一个字符串
参数:
pattern 正则
string 目标字串
返回值:
match对象,匹配到的内容
re.match(pattern,string,flags)
功能 :
匹配一个字符串起始内容
参数:
pattern 正则
string 目标字串
返回值:
match对象,匹配到的内容
re.search(pattern,string,flags)
功能 :
匹配第一个符合条件的字符串
参数:
pattern 正则
string 目标字串
返回值:
match对象 匹配到的内容
regex 对象的属性
flags 标志位数值
pattern 正则表达式
groups 子组个数
groupindex 获取捕获组字典,键为组名值是第几组
- Python全栈工程师(装饰器、模块)
ParisGabriel 每天坚持手写 一天一篇 决定坚持几年 全栈工程师 Python人工智能从入门到精通 装饰器 decorators(专业提高篇) 装饰 ...
- python 全栈开发,Day25(复习,序列化模块json,pickle,shelve,hashlib模块)
一.复习 反射 必须会 必须能看懂 必须知道在哪儿用 hasattr getattr setattr delattr内置方法 必须能看懂 能用尽量用__len__ len(obj)的结果依赖于obj. ...
- Python全栈 正则表达式(re模块正则接口全方位详解)
re模块是Python的标准库模块 模块正则接口的整体模式 re.compile 返回regetx对象 finditer fullmatch match search 返回 match对象 match ...
- python 全栈开发,Day28(复习,os模块,导入模块import和from)
一.复习 collections 增加了一些扩展数据类型 :namedtuple orderdict defaltdict队列和栈time 时间 三种格式 : 时间戳 结构化 字符串random 随机 ...
- python全栈开发_day15_函数回调和模块
一:函数回调 def a(fn=None): print("run1") if fn: fn() print("run 2") def b(): print(& ...
- 老男孩Python全栈第2期+课件笔记【高清完整92天整套视频教程】
点击了解更多Python课程>>> 老男孩Python全栈第2期+课件笔记[高清完整92天整套视频教程] 课程目录 ├─day01-python 全栈开发-基础篇 │ 01 pyth ...
- python全栈开发学习_内容目录及链接
python全栈开发学习_day1_计算机五大组成部分及操作系统 python全栈开发学习_day2_语言种类及变量 python全栈开发_day3_数据类型,输入输出及运算符 python全栈开发_ ...
- python全栈开发之正则表达式和python的re模块
正则表达式和python的re模块 python全栈开发,正则表达式,re模块 一 正则表达式 正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如,a 到 z 之间的 ...
- python全栈开发中级班全程笔记(第二模块、第四章(三、re 正则表达式))
python全栈开发笔记第二模块 第四章 :常用模块(第三部分) 一.正则表达式的作用与方法 正则表达式是什么呢?一个问题带来正则表达式的重要性和作用 有一个需求 : 从文件中读取所有联 ...
随机推荐
- VirtualBox改变虚拟硬盘位置
原本放虚拟硬盘的位置容量不足,因此将原来的虚拟硬盘放到了一个相对空闲的分区.设置虚拟硬盘位置时出现一点小问题,解决过程记录如下. 1. 将虚拟硬盘复制到目标位置后,假设为“F:\Ubuntu 16.0 ...
- 【luogu P3952 时间复杂度】 题解
对于2017 D1 T2 这道题 实实在在是个码力题,非常考验耐心. 其实大体的思路并不是非常难想出来,但是要注意的小细节比较多. 题目链接:https://www.luogu.org/problem ...
- Retain NULL values vs Keep NULLs in SSIS Dataflows - Which To Use? (转载)
There is some confusion as to what the various NULL settings all do in SSIS. In fact in one team whe ...
- <head> 中的 JavaScript 函数
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content=&q ...
- Hibernate知识点小结(一)--快速入门
一.Hibernate的简介 1.Hibernate是一个开放源代码的对象关系映射框架 2.对象关系映射:ORM Object Relation Mapping 对象与数据 ...
- foreach, for in, for of 之间的异同
forEach() 方法用于调用数组的每个元素,并将元素传递给回调函数. 注意: forEach() 对于空数组是不会执行回调函数的. 示例代码: var arr = [4, 9, 16, 25]; ...
- 洛谷P3871 [TJOI2010]中位数(splay)
题目描述 给定一个由N个元素组成的整数序列,现在有两种操作: 1 add a 在该序列的最后添加一个整数a,组成长度为N + 1的整数序列 2 mid 输出当前序列的中位数 中位数是指将一个序列按照从 ...
- chromium之pickle
pickle谷歌翻译成泡菜 醉了,看一下头文件的说明 // This class provides facilities for basic binary value packing and unpa ...
- ABAP术语-IDOC
IDOC 原文:http://www.cnblogs.com/qiangsheng/archive/2008/02/21/1075988.html Intermediate Document Inte ...
- 分布式网上商城项目-dubbo搭建与初次使用错误
1.Spring-service启动失败 严重: Exception sending context initialized event to listener instance of class o ...