spark编译安装 spark 2.1.0 hadoop2.6.0-cdh5.7.0
1、准备:
centos 6.5
jdk 1.7
Java SE安装包下载地址:http://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase7-521261.html
maven3.3.9
Maven3.3.9安装包下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache//maven/maven-3/3.3.9/binaries/
spark 2.1.0 下载
http://spark.apache.org/downloads.html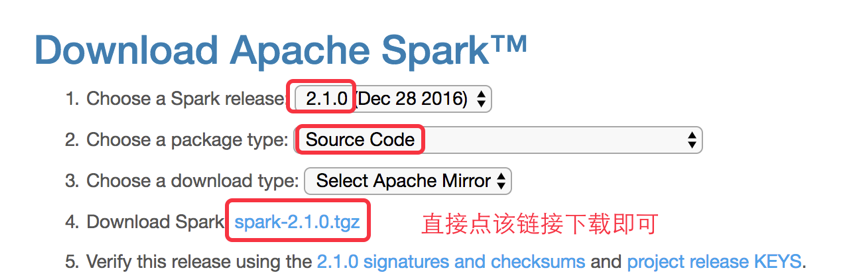
下载后文件名:

***************************************************分界线 编译开始*********************************************************************
上传到linux
安装maven,解压,配置环境变量
在此略掉...
mvn-v

说明mvn就已经没问题
*************************************************************分界线***********************************************************************************
我的hadoop版本是hadoop2.6.0-cdh5.7.0
解压spark源码包

得到源码包

忽略我这边已经编译好的spark安装包
先设置maven的内存,不然会有问题,直接设置临时的
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
[root@master109 opt]# echo $MAVEN_OPTS
-Xmx2g -XX:ReservedCodeCacheSize=512m
进入spark源码主目录

./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Phadoop-2.6 -Dhadoop.version=2.6.0-cdh5.7.0 -Phive -Phive-thriftserver -Pyarn
结果:
[INFO] BUILD FAILURE
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 9.810 s (Wall Clock)
[INFO] Finished at: 2017-10-13T15:52:09+08:00
[INFO] Final Memory: 67M/707M
[INFO] ------------------------------------------------------------------------
[ERROR] Failed to execute goal on project spark-launcher_2.11: Could not resolve dependencies for project org.apache.spark:spark-launcher_2.11:jar:2.1.0: Failure to find org.apache.hadoop:hadoop-client:jar:2.6.0-cdh5.7.0 in https://repo1.maven.org/maven2 was cached in the local repository, resolution will not be reattempted until the update interval of central has elapsed or updates are forced -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/DependencyResolutionException
[ERROR]
[ERROR] After correcting the problems, you can resume the build with the command
[ERROR] mvn <goals> -rf :spark-launcher_2.11
编译失败,显示没有找到一些包,这里是数据源不对,默认的是Apache的源,这里要改成cdh的源
编辑 pom.xml
[root@master109 spark-2.1.0]# ls
appveyor.yml bin common CONTRIBUTING.md data docs external launcher licenses mllib NOTICE project R repl scalastyle-config.xml streaming tools
assembly build conf core dev examples graphx LICENSE mesos mllib-local pom.xml python README.md sbin sql target yarn
[root@master109 spark-2.1.0]# vim pom.xml
在如下位置插入
#---------------------------------------------
中间的内容,改变数据源。记住,删掉上下的分隔符。
#---------------------------------------------
<repositories>
<repository>
<id>central</id>
<!-- This should be at top, it makes maven try the central repo first and then others and hence faster dep resolution -->
<name>Maven Repository</name>
<url>https://repo1.maven.org/maven2</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository> #---------------------------------------------
<repository>
<id>cloudera</id>
<name>cloudera Repository</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
</repository>
#---------------------------------------------
</repositories>
重新编译开始:
[root@master109 spark-2.1.0]# ./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Phadoop-2.6 -Dhadoop.version=2.6.0-cdh5.7.0 -Phive -Phive-thriftserver -Pyarn
等待几分钟:
[INFO] Reactor Summary:
[INFO]
[INFO] Spark Project Parent POM ........................... SUCCESS [ 3.997 s]
[INFO] Spark Project Tags ................................. SUCCESS [ 3.394 s]
[INFO] Spark Project Sketch ............................... SUCCESS [ 14.061 s]
[INFO] Spark Project Networking ........................... SUCCESS [ 37.680 s]
[INFO] Spark Project Shuffle Streaming Service ............ SUCCESS [ 12.750 s]
[INFO] Spark Project Unsafe ............................... SUCCESS [ 33.158 s]
[INFO] Spark Project Launcher ............................. SUCCESS [ 50.148 s]
[INFO] Spark Project Core ................................. SUCCESS [04:16 min]
[INFO] Spark Project ML Local Library ..................... SUCCESS [ 45.832 s]
[INFO] Spark Project GraphX ............................... SUCCESS [ 26.712 s]
[INFO] Spark Project Streaming ............................ SUCCESS [ 58.080 s]
[INFO] Spark Project Catalyst ............................. SUCCESS [02:22 min]
[INFO] Spark Project SQL .................................. SUCCESS [03:02 min]
[INFO] Spark Project ML Library ........................... SUCCESS [02:16 min]
[INFO] Spark Project Tools ................................ SUCCESS [ 2.588 s]
[INFO] Spark Project Hive ................................. SUCCESS [01:19 min]
[INFO] Spark Project REPL ................................. SUCCESS [ 6.337 s]
[INFO] Spark Project YARN Shuffle Service ................. SUCCESS [ 13.252 s]
[INFO] Spark Project YARN ................................. SUCCESS [ 57.556 s]
[INFO] Spark Project Hive Thrift Server ................... SUCCESS [ 45.074 s]
[INFO] Spark Project Assembly ............................. SUCCESS [ 7.410 s]
[INFO] Spark Project External Flume Sink .................. SUCCESS [ 30.214 s]
[INFO] Spark Project External Flume ....................... SUCCESS [ 19.359 s]
[INFO] Spark Project External Flume Assembly .............. SUCCESS [ 6.082 s]
[INFO] Spark Integration for Kafka 0.8 .................... SUCCESS [ 30.266 s]
[INFO] Spark Project Examples ............................. SUCCESS [ 28.668 s]
[INFO] Spark Project External Kafka Assembly .............. SUCCESS [ 6.919 s]
[INFO] Spark Integration for Kafka 0.10 ................... SUCCESS [ 30.811 s]
[INFO] Spark Integration for Kafka 0.10 Assembly .......... SUCCESS [ 6.551 s]
[INFO] Kafka 0.10 Source for Structured Streaming ......... SUCCESS [ 17.707 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 13:25 min (Wall Clock)
[INFO] Finished at: 2017-10-13T16:35:47+08:00
[INFO] Final Memory: 90M/979M
[INFO] ------------------------------------------------------------------------
完事!
2017-10-13 16:55:55
作者by :山高似水深(http://www.cnblogs.com/tnsay/)转载注明出处。
spark编译安装 spark 2.1.0 hadoop2.6.0-cdh5.7.0的更多相关文章
- 基于cdh5.10.x hadoop版本的apache源码编译安装spark
参考文档:http://spark.apache.org/docs/1.6.0/building-spark.html spark安装需要选择源码编译方式进行安装部署,cdh5.10.0提供默认的二进 ...
- 编译安装spark 1.5.x(Building Spark)
原文连接:http://spark.apache.org/docs/1.5.0/building-spark.html · Building with build/mvn · Building a R ...
- Spark入门实战系列--2.Spark编译与部署(下)--Spark编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Spark .时间不一样,SBT是白天编译,Maven是深夜进行的,获取依赖包速度不同 ...
- Spark编译安装和运行
一.环境说明 Mac OSX Java 1.7.0_71 Spark 二.编译安装 tar -zxvf spark-.tgz cd spark- ./sbt/sbt assembly ps:如果之前执 ...
- Spark编译及spark开发环境搭建
最近需要将生产环境的spark1.3版本升级到spark1.6(尽管spark2.0已经发布一段时间了,稳定可靠起见,还是选择了spark1.6),同时需要基于spark开发一些中间件,因此需要搭建一 ...
- Cenos7 编译安装 Mariadb Nginx PHP Memcache ZendOpcache (实测 笔记 Centos 7.0 + Mariadb 10.0.15 + Nginx 1.6.2 + PHP 5.5.19)
环境: 系统硬件:vmware vsphere (CPU:2*4核,内存2G,双网卡) 系统版本:CentOS-7.0-1406-x86_64-DVD.iso 安装步骤: 1.准备 1.1 显示系统版 ...
- hadoop2.3.0cdh5.0.2 升级到cdh5.7.0
后儿就放假了,上班这心真心收不住,为了能充实的度过这难熬的两天,我决定搞个大工程.....ps:我为啥这么期待放假呢,在沙发上像死人一样躺一天真的有意义嘛....... 当然版本:hadoop2.3. ...
- Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建
[注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.Spark编译与部署将以CentOS 64位操作系统为基础,主要是考虑到实际应用 ...
- Spark编译与部署
Spark入门实战系列--2.Spark编译与部署(上)--基础环境搭建 [注] 1.该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取: 2.S ...
随机推荐
- C#基础知识梳理系列
1. 这个系列深入的从IL层面谈了C#各种基本知识的本质,十分值得学习: http://www.cnblogs.com/solan/category/398748.html
- Java IO流读写文件的几个注意点
平时写IO相关代码机会挺少的,但却都知道使用BufferedXXXX来读写效率高,没想到里面还有这么多陷阱,这两天突然被其中一个陷阱折腾一下:读一个文件,然后写到另外一个文件,前后两个文件居然不 ...
- 专业工具软件AutoCAD复习资料
专业工具软件AutoCAD复习资料 下载地址:http://download.csdn.net/detail/zhangrelay/9849503 这里给出了一些dwg格式的CAD资料,用于课后学习和 ...
- 移动元素时,translate要比margin好
比如 做全屏轮播时,父元素往往是被子元素撑起来的,那你设置父元素的margin时,往往会感染到子元素,如下图: 而用translate3d就不会出现这种效果:
- Golang 编译成 DLL 文件
golang 编译 dll 过程中需要用到 gcc,所以先安装 MinGW. windows 64 位系统应下载 MinGW 的 64 位版本: https://sourceforge.net/pro ...
- Discuz代码研究-编码规范
Discuz中的编码规范很值得PHP开发人员借鉴.里面既介绍了编码时代码标记,注释,书写规则,命名原则等方面基础的内容,对代码的安全性,性能,兼容性,代码重用,数据库设计,数据库性能及优化作了阐述,这 ...
- linux之管道
1. 进程间通信概述 进程是一个独立的资源分配单元,不同进程之间的资源是独立的,没有关联,不能在一个进程中直接访问另一个进程的资源.进程不是孤立的,不同的进程需要进行信息的交互和状态的传递等,因此需要 ...
- 分布式缓冲之memcache
1. memcache简介 memcache是danga.com的一个项目,它是一款开源的高性能的分布式内存对象缓存系统,,最早是给LiveJournal提供服务的,后来逐渐被越来越多的大型网站所采用 ...
- HTML中id与name的用法
可以说几乎每个做过Web开发的人都问过,到底元素的ID和Name有什么区别阿?为什么有了ID还要有Name呢? 而同样我们也可以得到最经典的答案:ID就像是一个人的身份证号码,而Name就像是他的名字 ...
- LeetCode Split Concatenated Strings
原题链接在这里:https://leetcode.com/problems/split-concatenated-strings/description/ 题目: Given a list of st ...