ThreadPoolExecutor(上篇)
Java有两个线程池类:ThreadPoolExecutor和ScheduledThreadPoolExecutor,继承AbstractExecutorService类,AbstractExecutorService类实现了ExecutorService接口。Java API提供了Executors工厂类来帮助创建各种线程池。
ThreadPoolExecutor 构造方法
ThreadPoolExecutor 的构造方法如下:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
- corePoolSize:指定了线程池中的线程数量。
- maximumPoolSize:指定了线程池中的最大线程数量。
- keepAliveTime:当前线程池数量超过 corePoolSize 时,多余的空闲线程的存活时间,即多
次时间内会被销毁。 - unit:keepAliveTime 的单位。
- workQueue:任务队列,被提交但尚未被执行的任务。
- threadFactory:线程工厂,用于创建线程,一般用默认的即可。
- handler:拒绝策略,当任务太多来不及处理,如何拒绝任务。
ThreadPoolExecutor工作流程
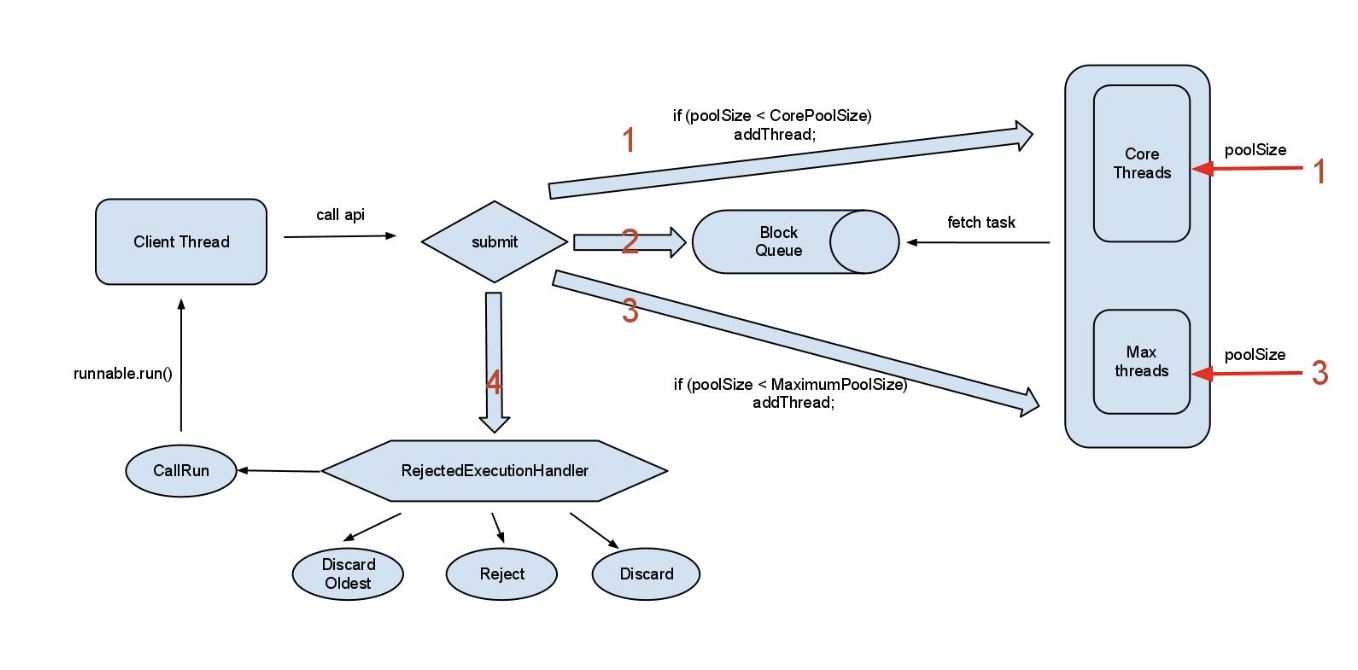
1、线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面
有任务,线程池也不会马上执行它们。
2、当调用 execute() 方法添加一个任务时,线程池会做如下判断:
a、如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
b、如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列;
c、如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要
创建非核心线程立刻运行这个任务;
d、如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池
会抛出异常 RejectExecutionException。
3、当一个线程完成任务时,它会从队列中取下一个任务来执行。
4、当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运
行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它
最终会收缩到 corePoolSize 的大小。
现代码实验下:
当池中正在运行的线程数(包括空闲线程)小于corePoolSize时,新建线程执行任务。
public class Exam13_1 {
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(2, 3, 1, TimeUnit.HOURS,
new LinkedBlockingQueue<>(1));
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
};
//任务1
executor.submit(runnable);
//任务2
executor.submit(runnable);
}
}
实验结果

从实验结果上可以看出,当执行任务1的线程(thread-1)执行完成之后,任务2并没有去复用thread-1而是新建线程(thread-2)去执行任务。
当池中正在运行的线程数大于等于corePoolSize时,新插入的任务进入workQueue排队(如果workQueue长度允许),等待空闲线程来执行。
public class Exam13_1 {
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(2, 3, 1, TimeUnit.HOURS,
new LinkedBlockingQueue<>(1));
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
};
//任务1
executor.submit(runnable);
//任务2
executor.submit(runnable);
//任务3
executor.submit(runnable);
}
}

从实验结果上看,任务3会等待任务1执行完之后,有了空闲线程,才会执行。并没有新建线程执行任务3,这时maximumPoolSize=3这个参数不起作用
当队列里的任务数达到上限,并且池中正在运行的线程数小于maximumPoolSize,对于新加入的任务,新建线程。
public class Exam13_1 {
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(2, 3, 1, TimeUnit.HOURS,
new LinkedBlockingQueue<>(1));
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
};
//任务1
executor.submit(runnable);
//任务2
executor.submit(runnable);
//任务3
executor.submit(runnable);
//任务4
executor.submit(runnable);
}
}

从实验结果上看,当任务4进入队列时发现队列的长度已经到了上限,所以无法进入队列排队,而此时正在运行的线程数(2)小于maximumPoolSize所以新建线程执行该任务。
当队列里的任务数达到上限,并且池中正在运行的线程数等于maximumPoolSize,对于新加入的任务,执行拒绝策略(线程池默认的拒绝策略是抛异常)。
public class Exam13_1 {
public static void main(String[] args) {
ExecutorService executor = new ThreadPoolExecutor(2, 3, 1, TimeUnit.HOURS,
new LinkedBlockingQueue<>(1));
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
}
};
//任务1
executor.submit(runnable);
//任务2
executor.submit(runnable);
//任务3
executor.submit(runnable);
//任务4
executor.submit(runnable);
//任务5
executor.submit(runnable);
}
}

实验结果分析:当任务5加入时,队列达到上限,池内运行的线程数达到最大,故执行默认的拒绝策略,抛异常。
ThreadPoolExecutor(上篇)的更多相关文章
- Android线程管理之ThreadPoolExecutor自定义线程池
前言: 上篇主要介绍了使用线程池的好处以及ExecutorService接口,然后学习了通过Executors工厂类生成满足不同需求的简单线程池,但是有时候我们需要相对复杂的线程池的时候就需要我们自己 ...
- 系统间通信(3)——IO通信模型和JAVA实践 上篇
来源:http://blog.csdn.net/yinwenjie 1.全文提要 系统间通信本来是一个很大的概念,我们首先重通信模型开始讲解.在理解了四种通信模型的工作特点和区别后,对于我们后文介绍搭 ...
- ThreadPoolExecutor使用和思考(上)-线程池大小设置与BlockingQueue的三种实现区别
工作中多处接触到了ThreadPoolExecutor.趁着现在还算空,学习总结一下. 前记: jdk官方文档(javadoc)是学习的最好,最权威的参考. 文章分上中下.上篇中主要介绍ThreadP ...
- ThreadPoolExecutor的应用和实现分析(中)—— 任务处理相关源码分析 线程利用(转)
前面一篇文章从Executors中的工厂方法入手,已经对ThreadPoolExecutor的构造和使用做了一些整理.而这篇文章,我们将接着前面的介绍,从源码实现上对ThreadPoolExecuto ...
- ThreadPoolExecutor(下篇)
上篇写到了ThreadPoolExecutor构造方法前4个参数int corePoolSize.int maximumPoolSize,.long keepAliveTime.TimeUnit un ...
- 看看C# 6.0中那些语法糖都干了些什么(上篇)
今天没事,就下了个vs2015 preview,前段时间园子里面也在热炒这些新的语法糖,这里我们就来看看到底都会生成些什么样的IL? 一:自动初始化属性 确实这个比之前的版本简化了一下,不过你肯定很好 ...
- 并发包的线程池第一篇--ThreadPoolExecutor执行逻辑
学习这个很长时间了一直没有去做个总结,现在大致总结一下并发包的线程池. 首先,任何代码都是解决问题的,线程池解决什么问题? 如果我们不用线程池,每次需要跑一个线程的时候自己new一个,会导致几个问题: ...
- ThreadPoolExecutor源码学习(1)-- 主要思路
ThreadPoolExecutor是JDK自带的并发包对于线程池的实现,从JDK1.5开始,直至我所阅读的1.6与1.7的并发包代码,从代码注释上看,均出自Doug Lea之手,从代码上看JDK1. ...
- ThreadPoolExecutor源码学习(2)-- 在thrift中的应用
thrift作为一个从底到上除去业务逻辑代码,可以生成多种语言客户端以及服务器代码,涵盖了网络,IO,进程,线程管理的框架,着实庞大,不过它层次清晰,4层每层解决不同的问题,可以按需取用,相当方便. ...
随机推荐
- 洛谷P2766 最长不下降子序列问题(最大流)
传送门 第一问直接$dp$解决,求出$len$ 然后用$f[i]$表示以$i$为结尾的最长不下降子序列长度,把每一个点拆成$A_i,B_i$两个点,然后从$A_i$向$B_i$连容量为$1$的边 然后 ...
- 【spring cloud】源码分析(一)
概述 从服务发现注解 @EnableDiscoveryClient入手,剖析整个服务发现与注册过程 一,spring-cloud-common包 针对服务发现,本jar包定义了 DiscoveryCl ...
- Python DataFrame 如何删除原来的索引,重新建立索引
删除行索引重排: ser.reset_index(drop = True) df.reset_index(drop = True) ---------------------------------- ...
- python模块-hmac
Hmac算法:Keyed-Hashing for Message Authentication.它通过一个标准算法,在计算哈希的过程中,把key混入计算过程中. import timefrom has ...
- 【hadoop】 eclipse中的“run on hadoop”和打包成jar提交任务的区别
eclipse中的 调试运行 及 “run on hadoop”默认只是运行在单机上的,因为要想在集群中让程序分布式运行还要经历上传类文件.分发到各个节点等过程, 一个简单的“run on hadoo ...
- Python3之Memcache使用
简介 Memcached是一个高性能的分布式内存对象缓存系统,用于动态WEB应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态,数据库网站的速度.Memcached ...
- app.use和app.get的区别及解析
转载至:http://blog.csdn.net/wthfeng/article/details/53366169 写在前面:最近研究nodejs及其web框架express,对app.use和app ...
- python get() 和getattr()
get() Python 字典 get() 函数返回指定键的值,如果值不在字典中返回默认值. 语法: dict.get(key, default=None) 实例1: d={'A':1,'b':2} ...
- 二分查找-数组实现(小trick)
template<typename T> int binarySearch(T arr[], int n, T target){ , r = n-; //在[l...r]范围内寻找targ ...
- SPOJ - DQUERY 莫队
题意:给定\(a[1...n]\),\(Q\)次询问,每次统计\([L,R]\)范围内有多少个不同的数字 xjb乱写就A了,莫队真好玩 #include<iostream> #includ ...