机器人多目标包围问题(MECA)新算法:基于关系图深度强化学习
摘要:中科院自动化所蒲志强教授团队,提出一种基于关系图的深度强化学习方法,应用于多目标避碰包围问题(MECA),使用NOKOV度量动作捕捉系统获取多机器人位置信息,验证了方法的有效性和适应性。研究成果在2022年ICRA大会发表。
在多机器人系统的研究领域中,包围控制是一个重要的课题。其在民用和军事领域都有广泛的应用场景,包括协同护航、捕获敌方目标、侦察监视、无人水面舰艇巡逻狩猎等。
这些应用的核心问题是如何控制一个多机器人系统,涉及多目标分配,同时解决目标包围和避碰子问题。这是一个巨大的挑战,特别是对于分散的多机器人系统。
中科院自动化所蒲志强教授团队在2022年ICRA大会发表论文,提出了一种基于关系图的深度强化学习方法,对各种条件下的多目标避碰包围(MECA)问题具有良好的适应性。
定义任务
该研究定义了一个MECA任务,即在具有L个静态障碍物(黑色圆圈)的环境中,由N个机器人(绿色圆圈)组成的多机器人系统,协同包围K (1 < K < N)个静止或运动的目标(红色圆圈)。
所有机器人需要自动形成多组,包围所有目标,每组需要形成圆形队形,包围一个独立的目标,同时避免碰撞。这涉及到以下三个子问题:
1) 动态多目标分配与分组
2) 每组分别包围
3) 相互之间避免碰撞
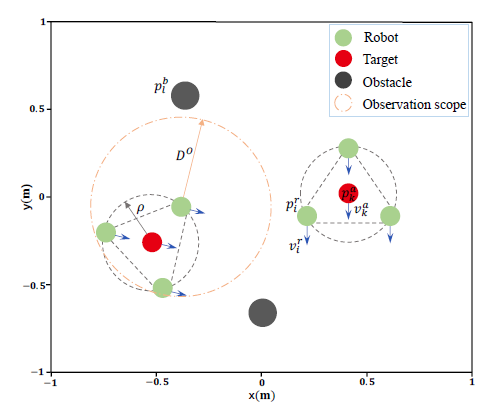
分散式多机器人系统的MECA图解
方法框架
在MECA问题中,存在三种类型的实体,即机器人、目标和障碍物。不同的实体对机器人有不同的影响关系,例如避障、包围目标、与其他机器人合作等。
研究提出了一种基于机器人级和目标级关系图(RGs)的DRL分散方法,命名为MECA-DRL-RG方法。
具体而言:
- 利用图注意网络(GATs)对机器人级RGs进行建模和学习,该RGs由每个机器人与其他机器人、目标和障碍物之间的三个异构关系图组成。
- 利用GAT构建目标级RG,构建机器人与各目标之间的空间关系。目标的运动由目标级RG建模,并通过监督学习进行学习,以预测目标的轨迹。
- 此外,定义了一个知识嵌入式复合奖励函数,解决MECA中的多目标问题。采用基于集中式训练和去中心化执行框架的演员-评论家训练算法对策略网络进行训练。

MECA-DRL-RG方法的整体结构
实验验证
研究团队分别进行了仿真实验和真实环境实验。在真实实验中,情景设置为:6个机器人在有2个障碍物的环境中包围2个移动的目标。机器人的位置和速度数据由NOKOV度量动作捕捉系统提供。

6个机器人在有2个障碍物的环境中包围2个移动目标
仿真实验和真实实验都验证了,相比于其他方法,MECA-DRL-RG方法使机器人能够从周围环境中,学习异构空间关系图,并预测目标的轨迹,从而促进每个机器人对其周围环境的理解和预测。证实了MECA-DRL-RG方法的有效性。
并且,无论机器人、障碍物或目标的数量增加,抑或是目标的移动速度加快,MECA-DRL-RG方法都表现出良好的性能,具有广泛的适应性。
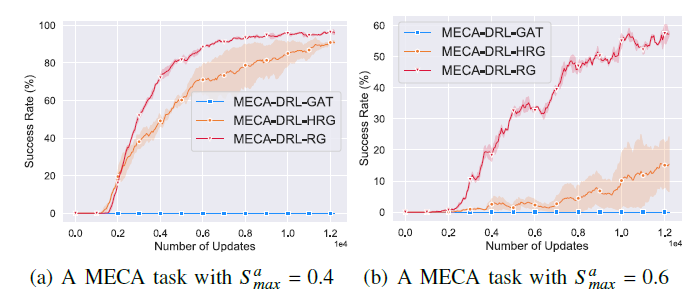
MECA-DRL-RG方法训练曲线
参考文献:
机器人多目标包围问题(MECA)新算法:基于关系图深度强化学习的更多相关文章
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- 论文:利用深度强化学习模型定位新物体(VISUAL SEMANTIC NAVIGATION USING SCENE PRIORS)
这是一篇被ICLR 2019 接收的论文.论文讨论了如何利用场景先验知识 (scene priors)来定位一个新场景(novel scene)中未曾见过的物体(unseen objects).举例来 ...
- 基于深度强化学习(DQN)的迷宫寻路算法
QLearning方法有着明显的局限性,当状态和动作空间是离散的且维数不高时可使用Q-Table存储每个状态动作的Q值,而当状态和动作时高维连续时,该方法便不太适用.可以将Q-Table的更新问题变成 ...
- 【转载】 DeepMind发表Nature子刊新论文:连接多巴胺与元强化学习的新方法
原文地址: baijiahao.baidu.com/s?id=1600509777750939986&wfr=spider&for=pc 机器之心 18-05-15 14:26 - ...
- 【算法总结】强化学习部分基础算法总结(Q-learning DQN PG AC DDPG TD3)
总结回顾一下近期学习的RL算法,并给部分实现算法整理了流程图.贴了代码. 1. value-based 基于价值的算法 基于价值算法是通过对agent所属的environment的状态或者状态动作对进 ...
- 强化学习(五)—— 策略梯度及reinforce算法
1 概述 在该系列上一篇中介绍的基于价值的深度强化学习方法有它自身的缺点,主要有以下三点: 1)基于价值的强化学习无法很好的处理连续空间的动作问题,或者时高维度的离散动作空间,因为通过价值更新策略时是 ...
- 强化学习-Q-Learning算法
1. 前言 Q-Learning算法也是时序差分算法的一种,和我们前面介绍的SARAS不同的是,SARSA算法遵从了交互序列,根据当前的真实行动进行价值估计:Q-Learning算法没有遵循交互序列, ...
- 【目标跟踪】相关滤波算法之MOSSE
简要 2010年David S. Bolme等人在CVPR上发表了<Visual Object Tracking using Adaptive Correlation Filters>一文 ...
- CVPR目标检测与实例分割算法解析:FCOS(2019),Mask R-CNN(2019),PolarMask(2020)
CVPR目标检测与实例分割算法解析:FCOS(2019),Mask R-CNN(2019),PolarMask(2020)1. 目标检测:FCOS(CVPR 2019)目标检测算法FCOS(FCOS: ...
- The game of life(生命游戏)新算法
我写了一种常见的实现算法,和另一种新算法,即不是每次循环计算每个细胞的周围细胞数来产生下一时刻,而是每次每个产生状态变化的细胞主动通知周围的邻居,因此每个细胞增加一个用来记录邻居数的字段.由邻居数决定 ...
随机推荐
- Codeforces Round #700 (Div. 2) A~C题解
写在前边 链接:Codeforces Round #699 (Div. 2) A. Yet Another String Game 链接:A题链接 题目大意: 给定一个字符串,有两位同学来操作这个字符 ...
- OpenSSL 使用AES对文件加解密
AES(Advanced Encryption Standard)是一种对称加密算法,它是目前广泛使用的加密算法之一.AES算法是由美国国家标准与技术研究院(NIST)于2001年发布的,它取代了原先 ...
- 【封装】二维BIT
struct BIT{ #define maxn 1000 int n, m; int d1[maxn][maxn], d2[maxn][maxn], d3[maxn][maxn], d4[maxn] ...
- [USACO2007OPENG] Dining G
题目描述 Cows are such finicky eaters. Each cow has a preference for certain foods and drinks, and she w ...
- 关于yolov3在训练自己数据集时容易出现的bug集合,以及解决方法
早先写了一篇关于yolov3训练自己数据集的博文Pytorch实现YOLOv3训练自己的数据集 其中很详细的介绍了如何的训练自定义的数据集合,同时呢笔者也将一些容易出现的bug写在了博文中,想着的是可 ...
- 使用Redis实现一个分布式的全局ID
当然实现方式有很多中,这里主要是记录一下使用Redis的实现方式 import lombok.extern.slf4j.Slf4j; import org.springframework.beans. ...
- Javascript Ajax总结——其他跨域技术之Web Sockets
Web Sockets的目标是在一个单独的持久连接上提供全双工.双向通信.在Javascript中创建了Web Sockets之后,会有一个HTTP请求发送到浏览器以发起连接.在取得服务器响应后,建立 ...
- 关于 K8s 的一些基础概念整理
〇.前言 Kubernetes,将中间八个字母用数字 8 替换掉简称 k8s,是一个开源的容器集群管理系统,由谷歌开发并维护.它为跨主机的容器化应用提供资源调度.服务发现.高可用管理和弹性伸缩等功能. ...
- MySQL|主从延迟问题排查(一)
一.案例分享 1.1 问题描述 大查询长时间执行无法释放DML读锁,后续同步主库的DDL操作获取DML写锁资源被阻塞等待,导致后续同步主库的操作堆积,主从延迟增长严重.从同步延迟的监控来看,延迟从17 ...
- 升级高版本springboot2.6.x:org/springframework/boot/context/properties/ConfigurationBeanFactoryMetadata
升级springboot高版本2.6.x 项目使用到了springcloud的oauth2依赖,直接升级springboot项目版本为最新 2.6.8(2022年6月16日)将会报以下错误: org/ ...