深度学习Python代码小知识点(备忘,因为没有脑子)
现在是2024年4月24日16:58,今天摸鱼有点多,备忘一下,都写到一篇内容里面,免得分散。
1. np.concatenate()函数
'np.concatenate'是NumPy库中用来合并两个或多个数组的函数。它可以在任意指定的轴上连接数组,是数据预处理和特征工程中常用的工具。
基本语法:
numpy.concatenate((a1, a2, ..., an), axis=0)
# (a1, a2, ..., an):一个包含多个数组的元组或列表。这些数组必须具有相同的形状,除了指定的轴
# axis:指定要沿其连接数组的轴。默认是0,意味着沿第一个轴连接。如果'axis=-1',则沿最后一个轴连接
示例代码:
import numpy as np # 两个数组
array1 = np.array([[1, 2], [3, 4]])
array2 = np.array([[5, 6], [7, 8]]) # 连接两个数组
# 沿着第一个轴(行方向)
np.concatenate((array1, array2), axis=0)
# 输出:
# [[1, 2],
# [3, 4],
# [5, 6],
# [7, 8]] # 沿着第二个轴(列方向)
np.concatenate((array1, array2), axis=-1)
# 输出:
# [[1, 2, 5, 6],
# [3, 4, 7, 8]]
2. 构造字典
字典在Python中是一种非常重要的数据结构,以键-值对的形式存储数据。字典允许快速存取、添加和删除数据条目,非常适合用于数据存储和访问,特别是在处理复杂数据时。
基本语法:
字典可以通过花括号'{}'或者使用'dict()'函数来创建:
# 使用花括号
my_dict = {'key1': 'value', 'key2': 'value2'} # 使用dict()函数
my_dict = dict(key1='value1', key2='value2')
(我这个猪脑子,明明之前学Python的时候,相当自信,还写的很愉快,扭脸就忘了,呜呜呜呜呜呜,鱼的记忆.)
示例代码:
# 假设用户信息
user_info = {'name': 'Alice', 'age': 30} # 访问数据
print(user_info['name'])
# 输出:
# Alice # 修改数据
user_info['age'] = 31
暂时先这样,后面再补充新的小细节内容(2024/4/24 17:22)。
3. 正则化(regularization)
(现在是2024年4月25日,20:22,组会摸鱼,哈哈哈哈)
正则化是机器学习和统计学中用于防止模型过拟合的一种技术。过拟合是指模型在训练数据上表现很好,但是在未见过的测试数据上表现不佳的现象。正则化通过向模型训练过程添加额外的信息或约束来解决这个问题,以便提高模型的泛化能力。下面是几种常见的正则化技术:
- L1 正则化(Lasso):L1 正则化通过向损失函数添加模型权重的绝对值之和的惩罚项来实现正则化。这种方式倾向于生成一个稀疏权重矩阵,即很多权重值会变为0。这有助于特征选择,因为模型会倾向于只使用最重要的特征。
- L2 正则化(Ridge):L2 正则化通过向损失函数添加模型权重的平方和的惩罚项来实现正则化。与L1正则化不同,L2正则化倾向于均匀地减小权重值,而不会将它们设为0。这有助于控制模型复杂度,使权重不会过大,从而防止模型过于依赖训练数据中的任何一个特征。
- Dropout:Dropout是神经网络中常用的一种正则化技术。在训练过程中,它通过随机丢弃(即设置为零)网络中的一部分神经元来工作。这有助于使网络的不同部分更加独立,防止它们互相适应(即共适应现象),从而提高模型的泛化能力。
- Early Stopping:提前停止是另一种常用的正则化形式,通过在验证集上的性能不再提高时停止训练来实现。这防止了模型在训练数据上过度训练,从而在遇到新数据时能保持较好的性能。
- 数据增强:在训练深度学习模型时,数据增强可以视为一种正则化形式。通过在训练过程中引入随机变化(如旋转、缩放、剪裁或颜色变化),模型被迫学习更加鲁棒的特征,这有助于提高其在新、未见过的数据上的性能。
- 参数平均(如SWA):参数平均,如随机权重平均(SWA),是一种通过在多个训练点上平均模型参数来改进模型最终性能的技术。这有助于稳定训练过程中的波动,并达到更平滑的错误景观和更好的泛化性能。(正在看的模型代码是使用的这个方法)
正则化的目的是改善模型在未见过的数据上的预测能力,从而使模型更加健壮。通过合适的正则化技术,可以显著提高复杂模型在实际应用中的可靠性和有效性。
(完蛋了,在摸鱼,忘写了,现在是21:21,组会还没开完,又要汇报进展,先写到这)
4. Python的切片(slicing)操作
在Python和尤其是在NumPy库中,切片是一种非常重要的数据操作方式,允许访问数组的子集、子序列或子矩阵。可以方便获取数据的某个部分而不必使用循环。
基本语法:
Python的切片语法通常写作:
start:stop:step
其中:
start是切片开始的位置,
stop是切片结束的位置(不包括此位置本身),
step是步长,即取值的间隔。
如果step是负数,意味着切片操作是从数组的尾部向头部进行。
示例和解释:
- [ : -1 ]和[ -1 : ]:
- [ : -1 ]表示从数组的开始位置取到最后一个元素之前的所有元素(不包括最后一个元素)。这是因为stop的参数为-1,它在Python中代表最后一个元素的索引位置,但由于切片不包括stop指定的元素,所以结果中不包括最后一个元素。
- [ -1 : ]表示从数组的倒数第一个元素开始取到数组的结束。由于start是-1,这里只包含最后一个元素。
- [ : , : -1 ]和[ : , -1 : ]:这两个表达式用于多维数组(如二维数组),通常出现在NumPy数组操作中。
- [ : , : -1 ]表示选取二维数组中的所有行,并且每行从第一个元素取到最后一个元素之前。
- [ : , -1 : ]表示选取二维数组中的所有行,并且每行只取最后一个元素。
这里的: 表示选取这一维度上的所有元素,是一个常见用法来表达在该维度上不做切片限制。
(2024年5月7日16:55,摸鱼老混子上线了)
5. 余弦退火学习率调度器(CosineAnnealingLR)
余弦退火学习率调度器(CosineAnnealingLR)是一种非常有效的方法,它通过模拟退火过程中温度的降低来调整学习率。具体来说:
- 开始时:学习率开始较高,有助于模型快速下降到损失较低的区域。
- 周期中期:随着周期数的增加,学习率逐渐降低,减少学习速率,有助于模型在损失较低的区域进行更精细的搜索。
- 周期末期:学习率再次升高,有时可以帮助模型跳出局部最小值,重新寻找更好的解。
这种学习率调整策略尤其适用于大规模和复杂的模型训练,能够有效提高模型的泛化能力和最终性能。使用学习率调度器通常可以观察到训练过程中的性能提升,尤其是在训练深层神经网络时。
(20:13,好好学习,不要摸鱼)
为什么需要清零梯度?
在训练神经网络时,使用反向传播算法来计算损失函数关于模型参数的梯度。这些梯度用于通过优化算法(如SGD、Adam等)更新参数。PyTorch的设计是将梯度累加到参数的 .grad 属性中,这意味着每次执行反向传播时,新计算出的梯度将被添加到已存在的梯度上。
这种累加机制在某些情况下是有用的(例如想要在多个小批次上累积梯度时),但在大多数标准训练循环中,在每次更新参数之前只使用当前批次计算的梯度。因此,在每次迭代开始时使用 optimizer.zero_grad() 清除累积的梯度变得非常必要。
如何使用 optimizer.zero_grad()
在模型训练的典型循环中,optimizer.zero_grad() 通常与 loss.backward() 和 optimizer.step() 结合使用,形成以下的步骤:
清除梯度:
optimizer.zero_grad()
在计算新的梯度之前清除旧的梯度。
- 计算梯度:
loss.backward()
在当前批次的数据上执行反向传播,计算损失函数相对于每个参数的梯度。
- 更新参数:
optimizer.step()
根据计算出的梯度更新模型的参数。
示例代码:
一个完整的训练迭代可能看起来像这样:
for epoch in range(total_epochs):
for batch in train_loader:
inputs, targets = batch
outputs = model(inputs)
loss = loss_function(outputs, targets) optimizer.zero_grad() # 重置梯度
loss.backward() # 反向传播,计算当前梯度
optimizer.step() # 根据梯度更新网络参数 print(f"Epoch {epoch}, Loss: {loss.item()}")
这个流程确保了每次参数更新都是基于最新一批数据的独立梯度,从而有效避免了梯度累积带来的问题。
(21:30,头痛+鼻塞,嗯,感冒了,无语)
1. 神经网络的基本结构
- 输入层:接收输入数据。
- 隐藏层:通过神经元进行复杂的非线性变换。
- 输出层:生成预测结果。
2. 前向传播(Forward Propagation)
前向传播是计算模型输出的过程。输入数据通过网络层逐层传播,直到生成最终的输出。
- 每一层的输入是前一层的输出。
- 每个神经元对输入进行加权求和,并通过激活函数生成输出。
示例: 假设有一个简单的三层神经网络(输入层、一个隐藏层、输出层):
import torch
import torch.nn as nn class SimpleNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size) def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out # 创建模型实例
model = SimpleNN(input_size=10, hidden_size=20, output_size=1) # 前向传播示例
input_data = torch.randn(5, 10) # 5个样本,每个样本10个特征
output_data = model(input_data)
print(output_data)
3. 损失函数(Loss Function)
损失函数用于衡量模型预测值与真实值之间的差距。常见的损失函数有均方误差(MSE)和交叉熵损失(Cross-Entropy Loss)。
- 均方误差:用于回归任务。
- 交叉熵损失:用于分类任务。
4. 反向传播(Backward Propagation)
反向传播是计算梯度并更新模型参数的过程。前向传播计算损失,反向传播通过链式法则(链式求导)计算每个参数的梯度。
- 链式法则:用于计算每个参数对损失函数的导数。
- 梯度:表示损失函数相对于参数变化的敏感度。
示例: 假设我们使用均方误差作为损失函数:
import torch.optim as optim # 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01) # 假设我们有真实值
target_data = torch.randn(5, 1) # 前向传播
output_data = model(input_data) # 计算损失
loss = criterion(output_data, target_data) # 反向传播
optimizer.zero_grad() # 清零梯度
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
5. 优化算法(Optimizer)
优化算法用于更新模型参数以最小化损失函数。常见的优化算法有随机梯度下降(SGD)、Adam、RMSprop 等。
- SGD:每次使用一个或几个样本计算梯度并更新参数。
- Adam:自适应学习率优化算法,结合了动量和 RMSprop 的优点。
前向传播与反向传播的详细过程
前向传播:
- 输入数据通过网络层逐层传播,生成输出。
- 每个神经元计算输入加权求和并通过激活函数生成输出。
- 最终层生成预测结果。
计算损失:
- 使用损失函数计算预测值与真实值之间的差距。
反向传播:
- 从输出层开始,逐层计算损失函数相对于每个参数的梯度。
- 使用链式法则将梯度传递到每一层。
- 更新每层的参数。
反向传播的数学原理
反向传播的核心是计算损失函数对每个参数的偏导数。这是通过链式法则实现的。假设有一个简单的两层神经网络,前向传播过程如下:
- 输入 x。
- 第一层权重 W1,偏置 b1。
- 第一层输出 z1=W1⋅x+b1。
- 激活函数 a1=σ(z1)。
- 第二层权重 W2,偏置 b2。
- 最终输出 z2=W2⋅a1+b2。
假设损失函数为 LLL,反向传播计算如下:
- 计算损失对第二层输出的梯度 ∂L∂z2\frac{\partial L}{\partial z_2}∂z2∂L。
- 计算第二层输出对第二层权重的梯度 ∂z2∂W2\frac{\partial z_2}{\partial W_2}∂W2∂z2 和对偏置的梯度 ∂z2∂b2\frac{\partial z_2}{\partial b_2}∂b2∂z2。
- 计算损失对第一层输出的梯度 ∂L∂a1\frac{\partial L}{\partial a_1}∂a1∂L,通过链式法则传递梯度。
- 计算第一层输出对第一层权重的梯度 ∂z1∂W1\frac{\partial z_1}{\partial W_1}∂W1∂z1 和对偏置的梯度 ∂z1∂b1\frac{\partial z_1}{\partial b_1}∂b1∂z1。

深度学习模型训练的完整流程
初始化:
- 定义模型结构。
- 初始化模型参数。
- 选择损失函数和优化算法。
训练循环:
- 迭代若干个 epoch,每个 epoch 包括以下步骤:
- 前向传播:计算模型输出。
- 计算损失:评估预测值与真实值的差距。
- 反向传播:计算梯度。
- 参数更新:使用优化算法更新模型参数。
- 迭代若干个 epoch,每个 epoch 包括以下步骤:
评估:
- 在验证集或测试集上评估模型性能。
- 根据需要调整模型结构或超参数。
通过上述步骤,深度学习模型能够在大量数据上进行训练,并逐渐调整自身参数,以便在特定任务上取得良好的性能。
8. 标准化(Standardization)和归一化(Normalization)
(2024年9月2日,在看代码.)
标准化和归一化是两种常用的数据预处理方法,它们虽然有相似的目的——使数据更适合机器学习模型,但它们的实现方法和应用场景有所不同。
标准化(Standardization)
定义:
- 标准化是将数据调整为零均值和单位方差的过程。通常,标准化会将数据转换为一个新的分布,其均值为0,方差为1。
公式: x′=x−μ/σ其中:
- x是原始数据。
- μ是原始数据的均值。
- σ是原始数据的标准差。
- x′是标准化后的数据。
特点:
- 标准化处理后,数据的均值为0,标准差为1。
- 标准化不会将数据限制在某个固定的范围内,例如0到1。
- 适用于数据的分布不均匀,或数据包含异常值(离群点)的情况。
- 适合用于需要计算距离的算法(如K-均值聚类、PCA)以及那些对特征尺度敏感的模型(如线性回归、支持向量机)。
示例:
from sklearn.preprocessing import StandardScaler scaler = StandardScaler()
train_X_standardized = scaler.fit_transform(train_X)
归一化(Normalization)
定义:
- 归一化是将数据缩放到一个固定的范围内,通常是0到1。目的是使数据在一个统一的尺度上,这样不同特征对模型的影响更为一致。
公式: x′=x−xmin/xmax−xmin其中:
- x是原始数据。
- xminx和 xmax分别是数据的最小值和最大值。
- x′是归一化后的数据。
特点:
- 归一化处理后,数据被缩放到0到1的范围内。
- 对于有界数据,归一化是一个常用的选择。
- 不适合处理数据中包含离群点的情况,因为离群点会影响最小值和最大值的计算,从而影响归一化结果。
- 适合用于需要特征值在同一尺度上的模型(如神经网络)。
示例:
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler()
train_X_normalized = scaler.fit_transform(train_X)
区别总结
- 标准化:将数据转化为均值为0,标准差为1的分布。处理后的数据没有固定的范围,适合处理具有不同尺度和单位的数据。
- 归一化:将数据缩放到固定范围(如0到1)。处理后的数据在一个统一的范围内,适合用于需要特征值在相同尺度上的算法。
注意:在实际应用中,选择使用标准化还是归一化应根据数据的特性和模型的要求来决定。有些模型对数据的分布和尺度非常敏感,因此选择合适的预处理方法可以显著影响模型的性能。
9. 序列化(Serialization)和反序列化(Deserialization)
(2024年9月3日)
1. 序列化(Serialization)
- 序列化是将Python对象转换为字节流(binary stream)的过程,以便将数据保存到文件中或者通过网络传输。
- Python中的
pickle模块可以将复杂的Python对象序列化为字节流。
2. 反序列化(Deserialization)
- 反序列化是将字节流重新转换为原始的Python对象的过程。
pickle.load就是实现这个功能的函数,它从文件中读取序列化的字节流,并将其转换回原始的Python对象。
示例
假设我们有一个包含字典的Python对象,并将其保存到文件中:
import pickle # 创建一个Python对象
data = {'name': 'Alice', 'age': 25, 'city': 'New York'} # 将对象序列化并保存到文件
with open('data.pkl', 'wb') as f:
pickle.dump(data, f)
这段代码使用pickle.dump将data对象序列化并写入文件data.pkl。
反序列化
现在,我们可以使用pickle.load从文件中加载数据:
# 从文件中读取并反序列化对象
with open('data.pkl', 'rb') as f:
loaded_data = pickle.load(f) print(loaded_data)
输出:
{'name': 'Alice', 'age': 25, 'city': 'New York'}
10. DTW(Dynamic Time Warping, 动态时间规划)算法
(2024年9月9日)
DTW (Dynamic Time Warping, 动态时间规划) 是一种用于计算两个时间序列之间相似性或距离的算法,特别适用于长度不相同或速度不同步的时间序列。
DTW 的关键特点:
- 时间轴不对齐问题:
- 在现实世界中,时间序列数据(如语音信号、股票价格、人体运动数据等)可能由于时间尺度上的变化,无法直接通过欧氏距离等传统方法进行比较。DTW通过动态调整时间轴,允许在不同时间步的序列之间进行匹配,从而计算出最小匹配距离。
- 局部匹配:
- DTW通过允许一个序列的点与另一个序列的多个点进行匹配,从而找到两者最合适的匹配方式。这种匹配方式可以容忍序列的时间偏差(如一个人说话速度变快或变慢的情况)。
DTW算法的基本流程:
距离矩阵:
- 首先为两个时间序列构建一个矩阵,其中每个元素表示两个序列中对应时间步的距离(通常使用欧氏距离计算)。矩阵的行数为第一个序列的长度,列数为第二个序列的长度。
累积距离矩阵:
- 构建一个累积距离矩阵,记录从序列起点到当前点的最小距离。每个元素的值等于当前位置与起点之间的最小代价路径上的距离和。累积路径通常是从左上角开始,一直到右下角。
动态规划:
- 利用动态规划算法,找到一条经过最小代价的路径(称为“最佳路径”),该路径表示两个序列的最佳匹配。路径上的点表示序列之间的匹配方式。
计算最小匹配距离:
- 通过累积最小代价路径上的距离值,得到两个时间序列之间的DTW距离。
DTW 示例
假设有两个时间序列:
- 序列 A: [1, 2, 3]
- 序列 B: [2, 2, 3]
通过DTW算法,序列A的第一个元素(1)可以与序列B的第一个元素(2)进行匹配,而不必要求它们在时间上完全对齐。最终,DTW算法会找到两者的最小匹配代价,并得出距离。
DTW 的应用:
- 语音识别:DTW用于对比语音样本,识别不同发音的相似性。
- 手写字符识别:用于比较手写字符的笔画顺序和速度差异。
- 股票分析:用于比较不同股票的价格走势,尽管它们可能在时间上有所错位。
- 人体动作分析:在运动捕捉中,DTW用于对比不同时间段的运动轨迹。
与其他距离度量的区别:
- 欧氏距离 只能直接比较长度相同的序列,且要求时间步一一对应。它不能处理速度不同步的情况。
- DTW 则通过动态规划允许时间轴上的偏移,是时间序列相似性计算的强大工具。
因此,DTW解决了时间序列在时间上不对齐的比较问题,广泛应用于模式识别、信号处理等领域。
11. GAK(Global Alignment Kernel, 全局对齐核)算法
(2024年9月10日)
GAK(Global Alignment Kernel, 全局对齐核) 是一种用于衡量时间序列相似性的方法,尤其适用于时间序列分析中的全局对齐问题。与其他传统的时间序列相似度度量方法(如动态时间规整 DTW)相比,GAK 更加注重时间序列的整体对齐情况,并且能较好地应对时间序列的时间变形。
核心概念
GAK 是一种基于核方法的相似度度量,它通过定义时间序列之间的“核函数”来衡量它们的相似度。与其他相似度度量不同的是,GAK 不直接计算距离,而是根据相似度函数来量化两个时间序列之间的相似性。
GAK 的优势
- 全局对齐:GAK 注重时间序列的整体对齐效果,可以通过核函数捕捉时间序列的全局特性。
- 鲁棒性:GAK 对时间序列的局部变形(如非线性时间变形)具有较好的鲁棒性。
- 可微分性:GAK 是基于核方法的,因此在优化过程中具有更好的数学性质。
公式与原理
GAK 的基本思想是使用核方法来定义时间序列之间的相似性。给定两个时间序列 X=(x1,x2,...,xT)和 Y=(y1,y2,...,yT),其相似性通过以下递归公式计算:
K(i,j)=e−d(xi,yj)/σ⋅(K(i−1,j−1)+K(i−1,j)+K(i,j−1))
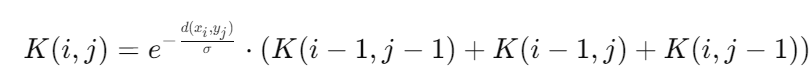
其中:
- K(i,j)表示时间序列 X和 Y在位置i和j处的局部相似性。
- d(xi,yj)是两个时间点xi和yj之间的距离(通常是欧氏距离)。
- σ是核的平滑参数,用于控制时间序列对齐的敏感度。
GAK 计算步骤
- 初始化核矩阵:首先构建一个核矩阵,用于存储每对时间序列元素之间的相似度。
- 递归计算:从时间序列的起点开始,通过递归公式计算时间序列的全局对齐核值。
- 累积相似性:通过核矩阵中的累积值,计算出时间序列的最终相似性值。
应用场景
- 时间序列分类:在时间序列数据的分类任务中,GAK 可以用来衡量不同时间序列的相似性,并基于这种相似性进行分类。
- 时间序列聚类:GAK 可以帮助时间序列数据的聚类分析,通过全局对齐核度量时间序列之间的相似性,从而实现更合理的聚类效果。
- 异常检测:在检测时间序列数据中的异常时,GAK 可以通过对比序列的整体变化趋势,判断哪些序列存在异常波动。
总结
GAK 是一种基于核函数的全局对齐方法,能够有效地衡量时间序列之间的相似性,尤其适用于处理具有时间变形的序列。与传统的动态时间规整(DTW)方法相比,GAK 更注重序列的全局特性,因此在很多时间序列分析任务中具有独特的优势。
12. MDTW(Multivariate Dynamic Time Warping, 多维动态时间规划)算法
(2024年9月10日)
MDTW(Multivariate Dynamic Time Warping,多维动态时间规整)是一种用于计算多维时间序列相似度的算法。它是经典 DTW(Dynamic Time Warping,动态时间规整)算法的扩展,能够处理时间序列中的多个维度。MDTW 被广泛用于时序数据分析中,尤其是在涉及多维时间序列的场景下,比如多传感器数据、金融时间序列、气象数据等。
DTW 基本概念
在介绍 MDTW 之前,先了解一下 DTW 的基础概念。
DTW 是一种衡量两个时间序列相似度的算法,它能够处理时间轴上存在不对齐或者变速的序列。DTW 通过动态规划方法,寻找两个时间序列之间最优的对齐路径,允许对时间序列进行拉伸和压缩,从而计算出最短的“对齐距离”。
DTW 核心步骤:
- 距离计算:对于两个时间序列 A和 B,首先计算它们在不同时间点上的距离(通常是欧几里得距离)。
- 动态规划:通过动态规划表计算出从第一个点到最后一个点的最短距离路径,这条路径就是对齐路径。
- 最短路径:对齐路径上的累积距离作为时间序列之间的 DTW 距离,反映了两个序列的相似度。
MDTW 概念
MDTW 是对 DTW 算法的扩展,专门用于处理多维时间序列(即每个时间点具有多个维度的序列)。在多维时间序列中,每个时间点不仅包含一个值,还可能包含多个值(如多个传感器记录的数据)。
MDTW 的核心思想:
MDTW 通过在多个维度上同时执行 DTW,对每个时间点的所有维度进行同步匹配。每个时间点的多维向量被看作一个整体,MDTW 通过计算每个时间点向量之间的距离来确定两条时间序列的相似度。
MDTW 的步骤:
- 计算每个时间点的距离:
- 对于两条多维时间序列中的每个时间点,计算它们的向量距离(通常使用欧几里得距离或者曼哈顿距离)。例如,假设两个时间序列分别是 A=[A1,A2,...,AT]和 B=[B1,B2,...,BT],其中每个 AiA_iAi 和 BiB_iBi 都是多维向量。
- 动态规划对齐:
- 类似于 DTW,MDTW 通过动态规划来确定如何最佳地对齐两个多维时间序列。它允许在时间上进行拉伸和压缩,以寻找两个序列的最佳匹配路径。
- 最优路径:
- 通过寻找最小的累积路径来计算整体的对齐距离,这个距离就是两个多维时间序列之间的 MDTW 距离。
MDTW 与 DTW 的主要区别:
- 输入数据:DTW 处理单维时间序列,而 MDTW 处理多维时间序列。
- 计算距离:在 DTW 中,每个时间点的距离是标量(通常是欧几里得距离),而在 MDTW 中,每个时间点的距离是多维向量的距离。
- 对齐方式:DTW 是沿时间轴对齐两个标量序列,而 MDTW 是沿时间轴对齐两个多维序列。
MDTW 的应用场景:
- 多传感器数据融合:在物联网或自动驾驶等场景中,多个传感器会同时产生数据。MDTW 可以用来比较不同传感器组合的数据,进行相似性分析。
- 金融数据:在股票市场分析中,MDTW 可用于比较不同股票的多维时间序列(如价格、成交量等),帮助投资决策。
- 运动模式识别:用于分析人体运动中的多维数据,比如手势识别、步态分析等。
MDTW 的优缺点:
优点:
- 能够处理时间轴上的变速、拉伸等不对齐现象,适用于复杂的多维时间序列。
- 通过全局对齐找到两个多维时间序列的最优匹配路径。
缺点:
- 计算复杂度较高,尤其是在处理高维、大规模数据时,计算时间和内存占用会显著增加。
- 对噪声敏感,由于全局对齐路径的计算依赖于所有点,因此噪声点可能影响整体距离计算。
总结:
MDTW 是 DTW 在多维时间序列分析中的扩展版本,通过在多个维度上同时进行对齐,能够处理复杂的多维时间序列数据。它在多维传感器融合、金融时间序列分析、运动模式识别等领域有广泛的应用。
深度学习Python代码小知识点(备忘,因为没有脑子)的更多相关文章
- python - opencv 的一些小技巧备忘
python - opencv 的一些小技巧备忘 使用python-opencv来处理图像时,可以像matlab一样,将一幅图像看成一个矩阵,进行矢量操作,以加快代码运行速度. 下面记录几个常用的操作 ...
- [深度学习] Python人脸识别库Deepface使用教程
deepface是一个Python轻量级人脸识别和人脸属性分析(年龄.性别.情感和种族)框架,提供非常简单的接口就可以实现各种人脸识别算法的应用.deepface官方仓库为deepface.deepf ...
- 深度学习python的配置(Windows)
Windows下深度学习python的配置 1.安装包的下载 (1)anaconda (2)pycharm 2.安装教程 (1)anaconda a.降版本 b.换源 (2)pycharm a.修改h ...
- Python TensorFlow深度学习回归代码:DNNRegressor
本文介绍基于Python语言中TensorFlow的tf.estimator接口,实现深度学习神经网络回归的具体方法. 目录 1 写在前面 2 代码分解介绍 2.1 准备工作 2.2 参数配置 2 ...
- [深度学习]Python/Theano实现逻辑回归网络的代码分析
2014-07-21 10:28:34 首先PO上主要Python代码(2.7), 这个代码在Deep Learning上可以找到. # allocate symbolic variables for ...
- python序列,字典备忘
初识python备忘: 序列:列表,字符串,元组len(d),d[id],del d[id],data in d函数:cmp(x,y),len(seq),list(seq)根据字符串创建列表,max( ...
- Python 小细节备忘
1. 多行字符串可以通过三个连续的单引号 (”’) 或是双引号 (“”") 来进行标示 >>> a='''a bc def ''' >>> print a ...
- 小鬼难缠--python小bug备忘
今天编译pyhon做人脸识别,遇到几个问题,做个记录吧. 编译报错: File "harrClassifier.py", line 17, in <module> fl ...
- iOS学习——iOS开发小知识点集合
在iOS学习和开发过程中,经常会遇到一些很小的知识点和问题,一两句话就可以解释清楚了,这样的知识点写一篇随笔又没有必要,但是又想mark一下,以备不时之需,所以就有了本文.后面遇到一些小的知识点会不断 ...
- [深度学习] Python人脸识别库face_recognition使用教程
Python人脸识别库face_recognition使用教程 face_recognition号称是世界上最简单的开源人脸识别库,可以通过Python或命令行识别和操作人脸.face_recogni ...
随机推荐
- PowerBuilder编程新思维6.5:外传1(PowerPlume的设计与规划)
<第五部分 Otherside 意外的宝藏> 每一颗种子都有发芽的梦想.PowerPlume(孔雀翎)开发交流群:286502392 PowerBuilder编程新思维6.5:外传1 ...
- AT_abc246_d 题解
洛谷链接&Atcoder 链接 本篇题解为此题较简单做法及较少码量,并且码风优良,请放心阅读. 题目简述 给定整数 \(N\),请你找到最小的整数 \(X\),满足: \(X \ge N\). ...
- 学习笔记--Java中方法递归调用
Java中方法递归调用 public class RecursionTest01{ public static void main(String[] args){ System.out.println ...
- java开发,入职第一天都干什么,带提前了解
2024.7.24,帝都今晚大雨,在雨声磅礴的夜晚适合干什么,没错适合敲代码,写博客,今晚来聊下入职一个新公司,第一天都干什么. 无论是刚毕业的新手小白,还是工作十余年的职场老人,入职一家新公司,只要 ...
- SpringSecurity:hasAuthority与自定义权限校验
springsecurity中有两种权限控制方法 1.基于注解 @PreAuthorize("hasAuthority('syst:add')") 他的作用是在controller ...
- 《最新出炉》系列入门篇-Python+Playwright自动化测试-57- 上传文件 - 番外篇
1.简介 前边的三篇文章基本上对文件上传的知识介绍和讲解的差不多了,今天主要是来分享宏哥在文件上传的实际操作中发现的一个问题:input控件和非input控件的上传API对其都可以上传成功.废话不多说 ...
- Mysql函数10-IF
IF函数用于判断条件是否成立,成立则执行命令1,不成立则执行命令2. 1.sql查询出一列create_time select create_time from goods where id=65 2 ...
- 路径规划综述博客:A* Optimizations and Improvements
地址: https://lucho1.github.io/JumpPointSearch/ 原作者还开发了A* 算法的Windows系统上的小程序:(重点:小程序意义不大,这个综述还是不赖的) 项目地 ...
- 如何使用工具下载B站非会员视频(下载B站免费web视频)
最近准备从B站上下载几个web页面上的视频,但是B站的视频又没有提供相关的下载工具,于是找到了一款下载B站视频的工具( you-get ), 该工具不能下载会员版的视频,不能下载收费的视频,不过对于免 ...
- 神经网络初始化:xavier,kaiming、ortho正交初始化在CNN网络中的使用
xavier.ortho是神经网络中常用的权重初始化方法,在全连接中这两种权重初始化的方法比较好理解,但是在CNN的卷积网络中的具体实现却不好理解了. 在CNN网络中xavier的初始化可以参看: [ ...