【转载】 优必选悉尼 AI 研究院何诗怡:基于课程学习的强化多标签图像分类算法 | 分享总结
原文地址:
https://baijiahao.baidu.com/s?id=1603057342167437458&wfr=spider&for=pc
来源“雷锋网”
-----------------------------------------------------------
雷锋网 AI 科技评论按:与单标签图像分类相比,多标签图像分类是一种更符合真实世界客观规律的方法,尤其在图像和视频的语义标注,基于内容的图像检索等领域有着广泛的应用。
在雷锋网旗下学术频道 AI 科技评论的数据库项目「AI 影响因子」中,优必选悉尼 AI 研究院凭借4 篇 CVPR 录用论文、8.2亿美元的C轮融资、AI首席科学家陶大程当选澳大利亚科学院院士的不俗表现,排在「AI 影响因子」前列。
近期,在 GAIR 大讲堂上,北京大学计算机视觉硕士何诗怡分享了她用强化学习解决多标签图像分类问题的方法和经验。
公开课视频回放地址:http://www.mooc.ai/open/course/499
何诗怡,北京大学计算机视觉硕士,优必选悉尼 AI 研究院学生,主要研究方向为强化学习,深度学习等。
分享题目: 基于课程学习的强化多标签图像分类算法
分享提纲
- 基于课程学习的机制,我们提出了一种强化多标签分类的方法来模拟人类从易到难预测标签的过程。
- 这种方法让一个强化学习的智能体根据图像的特征和已预测的标签有顺序地进行标签预测。进而,它通过寻求一种使累计奖赏达到最大的方法来获得最优策略,从而使得多标签图像分类的准确性最高。
- 在真实的多标签任务中,这种强化多标签图像分类方法的必要性和有效性。
以下为雷锋网 AI 科技评论整理的分享内容:

优必选成立于 2012 年,是一家全球领先的人工智能和人形机器人公司,目前已经推出了消费级人形机器人 Alpha 系列,STEM 教育智能编程机器人 Jimu,智能云平台商用服务机器人 Cruzr 等多款产品,并成功入驻全球 Apple Store 零售店。
此外,优必选还与清华大学成立了智能服务机器人联合实验室,与悉尼大学成立了人工智能研究院,与华中科技大学成立了机器人联合实验室,在人形机器人驱动伺服、步态运动控制算法、机器视觉、语音/语义理解、情感识别、U-SLAM(即时定位与地图构建) 等领域深度布局。2018 年,优必选完成了 C 轮融资,估值 50 亿美元。
讲解之前,我想感谢我的合作者们,他们在学习和工作中都给予了我很大的帮助,首先是郭天宇博士,徐畅博士,许超教授,和陶大程教授。

传统的单标签图像分类是指一幅图只有一个标签,比如手写数字识别数据集 Mnist:一张图只有一个标签,从 0 到 9 的一个数字;ImagineNet,一个数据集有 1000 个标签,每张图都只对应一个标签。但在真实的生活中,一幅图往往是属于多个标签的,比如一幅图有桌子,很有可能也有瓶子,桌子和瓶子都是这幅图像的标签,下面是给出的多标签图例:

图(a)中的标签:老虎、雪、西伯利亚虎 ;图(b)中的标签:老虎、雪、树、西伯利亚虎
这两幅图例都属于多标签图像,一副图中有多个物体,多个物体的标签组成了整幅图的标签,近些年来,这些多标签分类的方法有着各种各样的应用,比如图像的语义标注,视频的语义标注,还有基于内容的图像检索等等。
相较于单标签图像分类,多标签图像分类有一些难点:
- 难点一,标签之间存在各种各样的共生关系,比如天空和云彩,一幅图中有天空,很大可能也是有云彩。
- 难点二,这种标签之间的关系维度很高,用模型难以衡量。
- 难点三,很多标签在语义上有重叠,比如 cat 和 kitten 都指猫,所以这两个标签在语义上有重叠近些年来,关于多标签图像分类有着各种各样的研究,下面来介绍相关的工作。
多标签图像分类的一种典型做法,就是将多标签问题转化为单标签问题,最具有代表性的方法就是 Binary Relevance 方法,即我们常说的 BR 方法,假设有 3 个标签,那么这里就有 3 个分类器,每一个分类器都对应一个二分类器,输入 X,经过 3 个分类器,分别得到 Y1,Y2 和 Y3,它们的值都是 0 或 1。如果值是 0,就表示标签不属于该图像,如果是 1,就表示标签属于该图像。
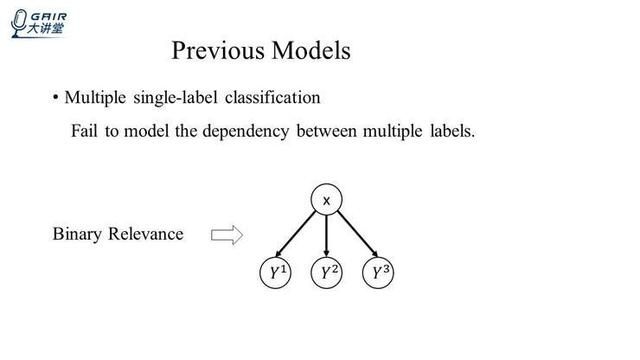
关于 BR 分类器的选择是多种多样的,有人使用 CNN,也有人使用决策树。近些年来,大家使用 CNN 作为基本分类器,然后用 ranking loss 和 cross entropy loss 来训练,但是这些方法都有一个共同的问题,它们忽略了标签之间的相关性。但是在多标签图像分类问题中,标签之间的相关性广泛存在。
怎么来衡量标签之间的相关性?
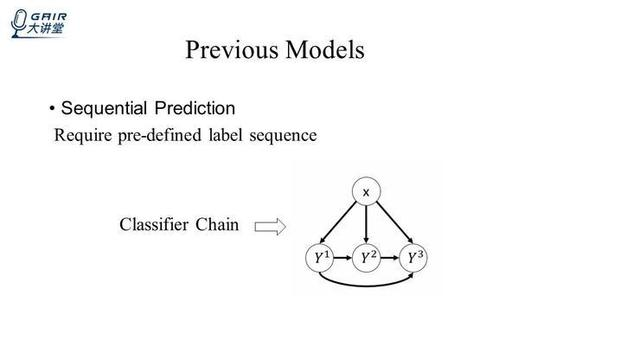
一种简单的方法,就是用预测过的标签来推断当前的标签,即用顺序预测的方法,顺序预测的方法一个典型的例子就是 classifier chain 的方法,上边是 classifier chain 的示意图,这比刚才的 Binary Relevance 方法多了几条线,就是从 Y1 到 Y2 的线,从 Y2 到 Y3 的线,还有从 Y1 到 Y3,刚开始的时候,X 输入进分类器,然后得到 Y1,将 Y1 和 X 同时作为输入,经过一个分类器得到了 Y2,然后将 X,Y1,Y2 再同时作为输入,经过分类器得到 Y3,也就是说,后面标签的预测依赖前面已经预测过的标签,classifier chain 的方法需要固定的顺序,而这个顺序是提前定好,Classifier Chain 方法对顺序非常敏感,为了减少顺序带来的影响,classifier chain 就有了各种各样的变种,比如 ECC(Ensemble Cassifier Chain),就是用 ensemble 的方法来提高 Classifier Chain 的 performance,除此之外,还有一种 CNN-RNN 的方法。
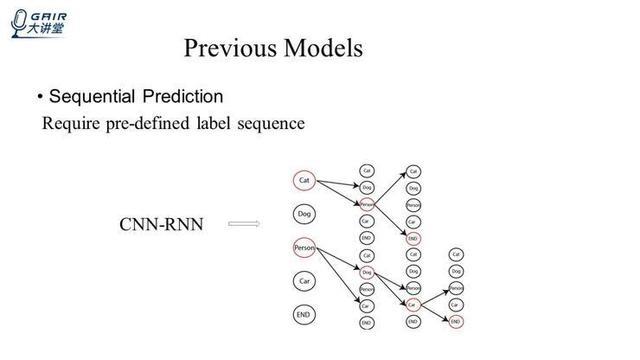
CNN-RNN 的方法,用 CNN 来提取图像的语义信息,然后用 RNN 去 model 这个图像和 label 之间的关系,但这个方法也需要一个提前定好的顺序。
除此之外,还有一些图的模型,如下图所示。
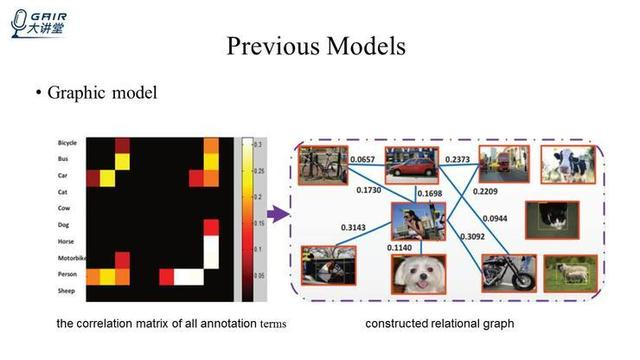
图(上左)是标签之间的共生机制; 图(上右)将标签之间的共生机制转化成了一个图的模型,通过求解图的模型来求解多标签图像分类的问题,但是这种方法参数比较多,求解比较复杂。
现有的方法不是同时预测图像的标签,就是进行顺序预测,但顺序需要提前定好,而且一般都是整个数据集给定一个顺序,这与人,动物的学习方法相悖。人和动物一般遵循的一种从简单到复杂的一种顺序,也就是我们常说的先易后难。在生物学里,这种机制叫做课程学习机制,2009 年的 ICML 提出了这种课程学习的机制,并且验证了能够通过改变学习的顺序(对知识进行简单的组织),来提升机器学习的效率。

上面是一个简单的例子,图(上排)是一些比较容易辨认狗的图片,图(下排)是比较难以辨认狗的图片。
使用 Curriculum Learning 来解决深度学习问题的时候,先学习图(上排)这些比较 easy 的样本,再去学习下面这些比较 hard 的样本,从而去提升算法的 performance 和更加有利于它的收敛,在这里我们将这种课程学习的机制延伸到多标签图像分类的问题中。

看图(左),boat 是十分显眼的,所以说在这幅图像中是 boat 属于一个比较 easy 的 label,但是 boat 上的 person 被部分遮挡,因此 person 是比较难以预测的 label。人类对图像预测的顺序,是先预测 boat 再预测 person,这遵循了人的从简单到复杂课程学习机制。
图(右)中,我们首先看到的是比较显眼的「猫」,所以「猫」就是比较 easy 的 label,看到后面有部分遮挡的「沙发」,所以「沙发」就是比较 complex 的 label,这也是遵循了人的从易到难的课程学习机制。
其实,对于人和动物来说,同一幅图中物体的的顺序并不是固定的,它们的顺序根据物体在图像中的大小,一些语义之间的联系这些因素决定,给整个数据集定一个顺序不符合人的课程学习机制,因此,我们就提出了基于课程学习的强化多标签学习的方法,让强化学习的智能体根据图像的内容和标签的关系,来学习该如何预测以及预测的顺序。

其次,在真实的图像标注系统中,一般都是用户上传一幅图,随后系统会为用户推荐几个标签,会给出一些反馈,面对给出的标签,用户会给出一些反馈。而这些反馈都很少被研究过,在这篇文章中我们也将反馈的信息都融入到了多标签学习的过程中。
上面我们提到的都是用强化学习来进行多标签分类学习的问题,下面我们就来简单介绍一下强化学习。
强化学习是机器学习的一个重要分支,强化学习与其他机器学习的不同之处在于,首先强化学习没有教师信号,比如它没有 label,只有 reward。强化学习的反馈有延迟,不能够立即反馈。强化学习输入的相当于系列数据,它是从一个状态到另一个状态。强化学习智能体之间的动作是会影响到之后的数据。
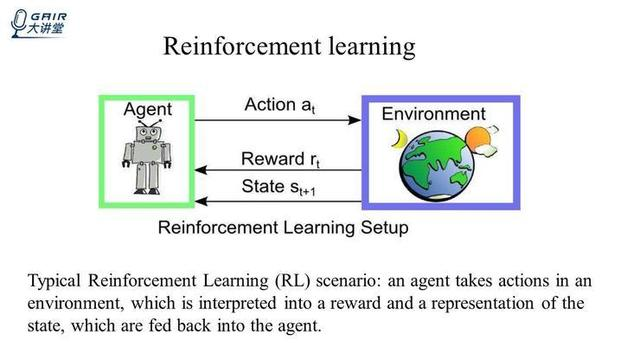
图(左)是一个强化学习的智能体, 图(右)是环境。强化学习的智能体通过与环境交互,通过不断的试错学习,能够达到目标的最优策略。
强化学习有三个要素,第一个要素是状态 State,第二个要素是动作 Action,第三个要素是 Reward。在 t 时刻的时候,智能体的状态是 St,通过观察环境,采取动作 at,同时得到环境的反馈 rt,进入到了下一个状态 St+1,重复上述过程,直到交互结束。这就是一个强化学习的基本过程。
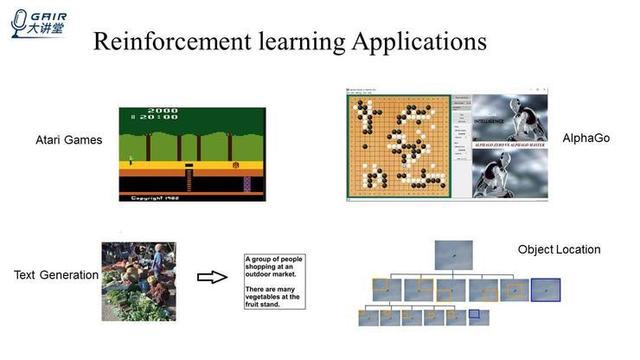
除此之外,强化学习还有许多的应用,比如在大部分的 Atari 游戏中,强化学习的智能体的得分超过人类;AlphaGo(是将强化学习和蒙特卡洛树搜索 (UCT) 结合在一起),强化学习的智能体能够下赢世界冠军;
在文本领域,可以利用强化学习的算法,根据图片生成文本;在图像领域,上图(右下)是利用强化学习来做目标检测的一个例子。
下面介绍一下强化多标签图像分类学习方法。

首先,我们来简单介绍一下里面用的符号,X(大写)是输入语,Y(大写)是 label 集,如果有 m 个标签的话,它的 label 集就是从 1 到 m。x(小写)是输入的一个例子,在这里我们一般指的是一幅图像,y(小写)是属于这个例子的标签,如果这个例子有 K 个标签,那么 Y={y1,...... ,yk},yi 对应着第 i 个标签属于 x。

我们将强化学习这个方法和普通的监督学习方法来进行一下对比,在传统的监督学习方法中,在训练的时候,x,y 已知,也就是输入 X 和输出 Y 在训练的时候已知,我们学习的就是从 X 到 Y 的一个映射,但是在强化学习问题中没有 label,也就是说 Y 未知,我们得到是只有反馈 p,在一个时刻,输入是 x,采取动作是 zi,就会得到一个 zi 的反馈:pi。一般来说,pi 属于 {-1,+1} 这两个值,它反映了推荐标签的好坏,-1 值推荐这个标签得到的反馈不好,+1 指推荐这个标签得到的反馈是好的。

在这个任务中,我们将这个图像序列建模的过程建立成一个 Markov 的过程,Markov 过程有 5 个要素,S,A,R,T,γ 。
- S:状态空间(state space)
- A:动作集,一般动作集都是有限的
- R:在执行状态 S 下,执行动作 A 会得到一系列 R 构成的空间,称为 R 空间,R 一般属于 {-1,+1},它反映了执行动作 A 之后得到的反馈的好坏
- T:在状态 S 下执行 A 得到下一个一个状态,就是之间状态的转移
- γ:属于 [0,1]
- π:在这里指我们想要找的策略,是从 S 到 A 的一个映射
首先我们来介绍第一个要素,A,即 Action。
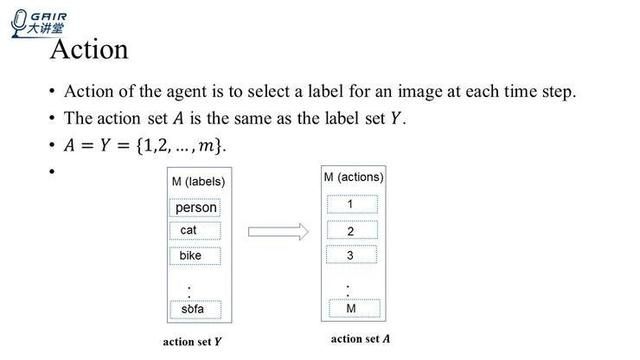
一个智能体它的动作就是为一幅图选择一个标签,在多标签分类图像这个问题里面,动作 A 这个集和 label 的集一样,如果一个数据集有 m 个标签,它就有 m 个动作,上图(左)对应的是这个数据集的标签集,它有 person,cat,bike 以及 sofa 这些标签,然后它会分别对应到动作集 A 中来,比如说 person 对应 1,cat 对应 2,一一对应。
状态 S,State
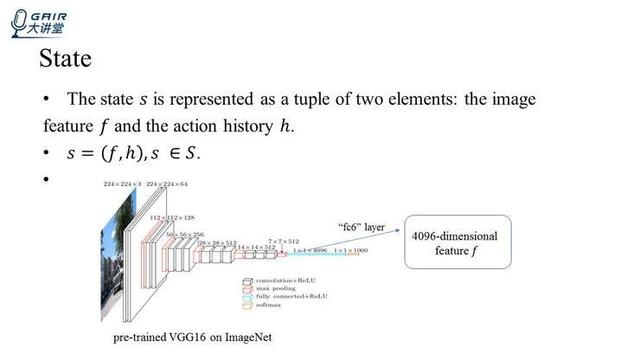
状态 S 是用一个二元组来表示的,二元组的第一个元素是图像的元素 f(feature),第二个元素是 action history h,所以 s=(f,h),每一个状态都属于整个状态空间。
首先,feature f 是从一个 VGG16 的全连接层、4096 维的向量提取出来,VGG16 已经在 ImageNet 上面训练好,但是还需要在多标签数据集上进行返训,这样做是因为 imageNet 和这个 multi-label 数据集的标签可能不完全一致,相较于 imageNet 这个单标签的数据集而言,多标签数据集的语义和空间关系会更加复杂一些,所以在 muti-label 数据集上的返训非常有必要。

二元组的第二个元素 h,h 是一个实向量,代表之前预测过的标签,即从这个 episode 开始,一直到当前时刻所有预测过的标签都叫做 action history,每个动作都对应着 1 到 M 的一个数字,所以我们将每一个动作编码成一个向量,如果这个动作集仅有 M 个动作,那么每一个动作都会被编码成一个 M-1 位的向量,就是上图(下)的公式,e 代表每一个动作的编码。

上图一个具体的例子,初始的时候,这张图没有任何的标签预测过,标签页面为空,然后我们进行它的第一个动作,就是预测它的标签是 person,在这个图里面找到了它的标签 person,然后把它添加到 action history 里面。在 t=3 时刻的时候,预测了标签 car,再将 car 添加到 action history 里面来,在 t=4 的时刻,预测了标签 tree,所以再将 tree 添加到 action history 里面来,所以我们可以看到,从初始状态一直到这个 episode 的结束,它的 action history 是从一开始的空到基本能填满一些标签,再看图(左),刚才我们说每一个动作都被建模成一个 M-1 位的向量,如果我们取 n 个动作作为 action history 的话,那么 h 的维度就是 n*(M-1)。
然后是 Transitions T,在我们这个 MDP 过程(马尔科夫决策过程)中,T 是固定的,也就是说对于一个状态和动作的对来说,它能够到达的新状态是固定的,也就是说在状态 s 下采取动作 a,能够达到唯一的下一个状态值 sp,即上图中的这个公式:T(s,a)=T((f,h)a)=(f,h')。因为对于一个 episode 来说,图像的 feature 是不变的,都是 VGG16 全连接的那个 feature,变化的只是 action history。
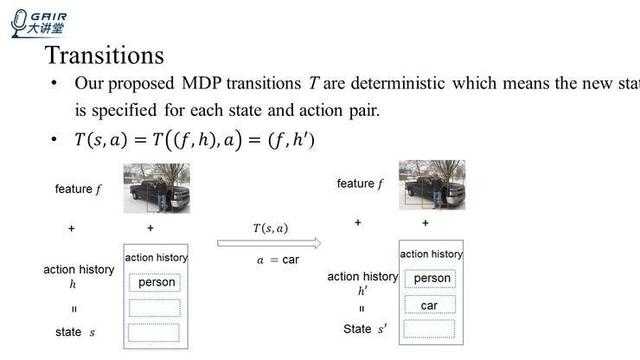
看上图(下部),将该图像输入到 VGG16 中,抽取全连接层的 4096 维的 feature,组成了这个 feature f。这里,我们假设已经预测了一个标签 person,所以这个就是它的 action history,两者共同构成了状态 s。在本时刻,我们预测 a=car,就会得到下一个状态,就是同样的状态加上变化了的 action history,将这个 car 添加到 action history 列表中来,得到了一个状态 s',对于每一个状态而言,它采取了每一个固定动作之后,它得到了下一个状态 s'也是唯一的。
在真实的场景中,这些反馈是离散的(reward 是离散的),但是在这里为了简化这个问题,我们将 reward 设置了一下:如果它的反馈是好的,那么就将它的 reward 设置成 1,如果它的反馈不好,就将它的 reward 设置成-1,如何来评定这个好和不好?

在这个问题中,如果它选的标签是对的,那么我们就认为它是好的,如果它选的标签不属于这个图像,就认为它是不好的。上图(下)是一个具体的例子,在同一个状态下,我们去选择动作,如果它选择的动作是 car 或 tree,就说明这个两个标签都是属于该图像,说明它选对了,就会得到 r=+1 这个标签。如果它选的标签是 dog 或 bus,就说明这两个标签是不属于这个图像,说明它选错了,就会得到 r=-1。
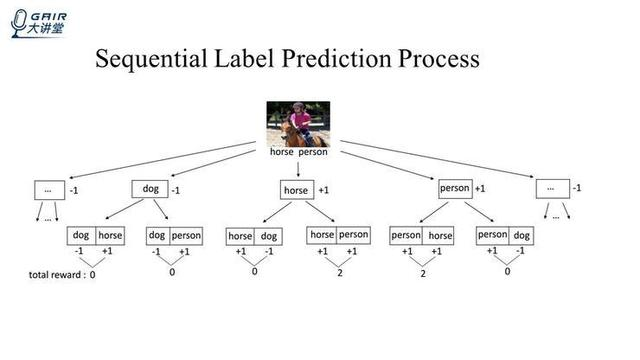
这是一个顺序预测的例子,该例子更清晰的显示 r 如何设置,在刚开始的时候图像是有 horse 和 person 两个标签,如果我给这个图像一个标签「dog」,这个「dog」是不属于这个图像的,所以它会得到一个 reward=-1。如果给一个标签 horse 或 person,这两个标签都属于这个图像,它们都会得到一个 reward=+1,当然预测成其他标签也不对,它们得到的 reward 都是-1。
选择了标签 dog 之后,我们就会选择预测它的下一个标签,如果它的下一个标签预测的是 horse,就说明它选对了,就给一个 reward=+1。如果它下一个标签选择的是 person,也认为它选对了。当然,如果 horse 的下一个标签选错了,就给它一个-1,如果它的下一个标签选对了,就给+1,另一边也是如此。
然后我们计算一下这两步总体的 reward 和,可以看出当一个 reward 选对,一个 reward 选错时,它们总体的 reward 和为 0,只有当两个标签都选对的时候,比如 horse,person 或者 person,horse,它才会得到 reward=+2,其他的情况会得到 0 或者-2。对于我们这个多标签图像分类问题转化成标签顺序预测的问题,目标就是寻求一种预测,能够让它得到的 reward 和最大,也就对应着它的准确率是最高。
上面的方法已经介绍完毕,下面我们来介绍用于求解多标签强化图像分类的 deep Q-learning 的算法。

强化学习的最优策略,就是刚才讲解的累计奖赏和最大的策略。在多标签图像分类任务中,累计奖赏和最大对应预测出的准确度最大。我们用 deep Q-learning 来解决寻求最优策略的问题,deep Q-learning 是运用神经网络来预测每一个状态动作对对应的 Q 值,使用已经训练好的 CNN 作为 feature 的提取器,在训练的时候不再对这一部分进行训练,即这一部分的参数不再进行更新了,只需要更新 Q 网络的参数,这样会让该算法收敛的更快、且更稳定。
下图是 deep Q-learning 的网络结构示意图:

给出一幅图像,在 VGG 的这个网络中输入已经训练好的 CNN,就会得到一个 feature
,将该图像的 feature 和 action history 并在一起作为状态,将其作为 deep Q 网络的输入,deep Q 网络的输出是每一个网络对应的 Q 值,比如这里的 person,cat,bike...sofa 都会对应着自己的一个 Q 值,每一次在选择的时候,我们都会选择 Q 值最大的动作作为最优的动作来进行迭代更新。

训练 Q 网络的损失函数,经典的 deep Q-learning 算法是写成这样的形式(见上图第一行公式),在每一步选取动作的时候,都选取最大 Q 值对应的动作,但是这里我们根据多标签图像的这个问题,进行了一下变化,就是不再选取最大的 Q 值对应的动作,而是直接将下一个动作保存起来,存在 experience replay 里,更新的时候直接用这一部分(红圈标注部分)的 Q 值,参数的迭代也是这种形式。
下面是 deep Q-learning 的具体算法:

初始的时候,我们初始化一个 replay memory D,和整个动作集 A,我们设置一个 B 作为已经预测过的动作集,然后设置了一个动作集 C 作为没有预测过的动作集。因为在典型的强化学习问题中,对于每一个 episode 而言,智能体每一步是选取一个动作,一个 episode 的动作可以重叠,但是对多标签图像分类而言,每一幅图都不会存在重复的标签,因此在用强化学习解决多标签图像分类的问题时,每一幅图,每一个时刻都不再选择这些已经预测过的标签,这就是为什么要设置已经预测过的动作集 B 和没有预测过的动作集 C,然后从 t=1,T 时刻,在每一个时刻都首先计算一下 C,C 是没有预测过的标签动作集,C=A\B,即从 A 中将 B 的元素去掉,然后遵循∈-greedy,从 C 中选取一个动作,执行这个动作,然后会得到一个 reward r,同时进入下一个状态,这样一次交互就已经完成了,然后将刚才执行过的动作放入已经预测过的动作集 B 中,然后重新计算 C=A\B,然后遵循∈-greedy 这个策略,选择下一个动作的状态 at+1,然后将 St,at,rt,St+1,at+1 一起放在 D 中,一个和环境交互的过程就完成了(如上图)。
上图(红线下部分)是训练的过程,在训练的时候,我们从 D 中随机抽取一个 mini batch 出来,然后用图(红线下部分)的公式来计算 Target Q 网络的值,然后根据梯度更新 Q 网络的参数和 target Q 网络的参数,执行 M 次,最后通过这一系列算法的过程就会得到一个最优的动作和最优的策略,这就是 deep Q-learning 用于多标签图像分类算法的流程。
下面介绍一下实现的一些细节:

我们用的数据集是 PASCAL VOC2007 和 PASCAL VOC2012,我们的 deep Q 网络的设置是第一层有 512 个节点,第二层有 128 个节点。因为这个数据集有 20 个标签,所以最后一层是有 20 个节点。数据集有 20 个标签,每一个动作都可以用一个 19 维的向量来表示,每一个 action history h 都会编码之前的两个动作,所以 h 总共有 38 位。我们训练这个网络的 3 个 epoch,每一个 epoch 都表示整个数据集图像都标记完,在训练的时候,遵循∈-greedy 这个策略,∈在前两个 epoch 的时候从 0 到 1.2,最后一个 epoch 固定在 0.1。
介绍一下实验的结果:

首先,介绍实验中的 PASCAL VOC2007 和 PASCAL VOC2012,PASCAL VOC2007 一共有 9963 张图,其中 5011 张是 trainval 的样本,4952 张是 test 的样本。PASCAL VOC2012 的数据集的图像数量约为 VOC2007 的两倍,是 22531 张图,其中 trainval 的图有 11540 张,test 图有 10991 张,它们每个数据集都只有 20 个标签。
衡量指标,我们用 average percision 和 mean of averge percison 来衡量。

首先,是我们设计实验来探究了学习出来的 label 是不是符合课程学习的机制,我们标准的算法叫做 RMIC,然后我们设计了一个 RMIC-fixed 的算法,RMIC-fixed 是 RMIC 的一个变种算法,它是这样设计的:
假设在训练集中出现次数较多的标签,相较于训练集中出现次数较少的标签,预测的时候应该更靠前一些,因此我们计算了每一个标签出现的次数,然后按照标签次数从多到少设计了一个固定的顺序,这就是我们为 RMIC 设计的固定顺序,但是相对于标准的 RMIC 来说,RMIC-fixed 的 reward 设置有一些不同,举一个例子,如果我们定义好的这个顺序是 person 和 dog 的话,那么我们预测的顺序是 dog 和 person 的话,那么 RMIC-fixed 得到的 reward 就是-1 和-1,RMIC 得到的 reward 是+1 和+1,RMIC-fixed 是当你预测的顺序和定义好的顺序完全一致的时候,它的 reward 才会都是+1。我们通过比较这两种办法来判断学习到的标签顺序是不是根据 label 出现的频率从多到少的顺序。
然后我们用下面的指标来衡量:
- 第一个指标,类平均和样本平均的准确率,即 class-level 和 example-level 的 precision
- 第二个指标,指标是类平均和样本平均的召回率,即 class-level 和 example-level 的 recall 值
- 第三个指标,类平均和样本平均的的指标值,即 class-level 和 example-level 的 F 值
下面就是这个实验的结果:
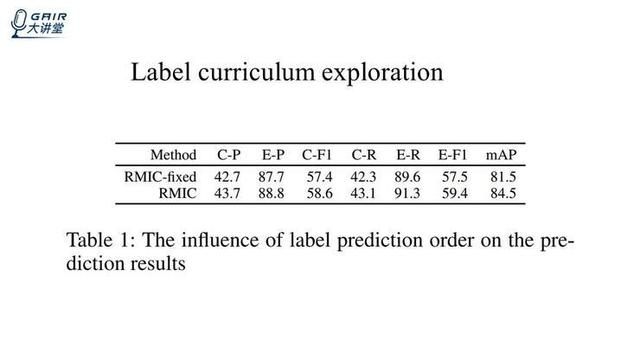
无论是在类平均(C-P),还是在样本平均(E-P)上,RMIC 的 performance 远远好于 RMIC-fixed,所以标准的 RMIC 方法的学习顺序优于简单的定义好的顺序。
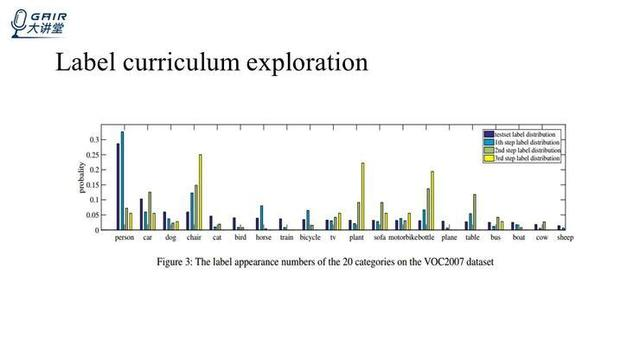
介绍一下标签出现顺序和预测顺序之间的关系,看上图,紫色的柱体代表的是测试集中标签出现次数的分布,蓝色柱体表示第一步预测出来标签的分布,绿色的柱体表示第二步预测出来标签的分布,黄色表示第三步预测出来标签的分布。
通过观察可以发现,第一步预测出来的标签的分布和测试集上真实的分布,就是蓝色的分布和紫色的分布大体上一致,出现次数越多的标签会被更早的预测出来。在绿色和黄色的分布中,可以发现这种趋势变得没那么明显了,也就是智能体在已经预测出简单标签的帮助下,能够去预测一些比较难的标签,比如说 person,car 和 dog,它们都是一些比较简单的标签,往往在第一步就会被预测出来,然后像后面的 bottle,chair 和 plant 这些标签,它们都是一些比较难的标签,一般在第一步都很难被预测出来,都在第二步和第三步才预测出来,也就是说第一步简单标签的预测对后面难的标签的预测有帮助作用。
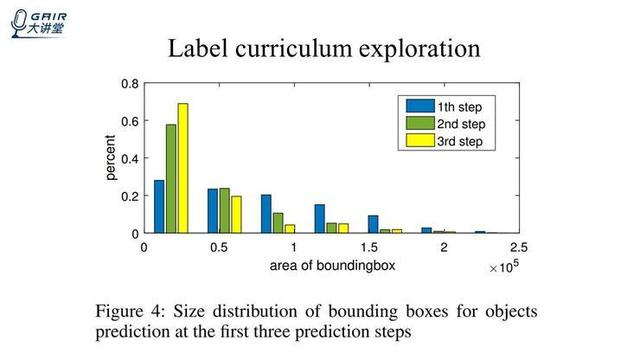
除此之外,我们还预测了物体顺序和大小的关系,看上图,蓝色是第一步预测出来物体大小的分布,绿色是第二步预测出来物体大小的分布,黄色是第三步预测物体大小的分布。
可以看到比较大的物体,在第一步预测的时候会被预测出来,举一个例子,比如 person 和 chair 都会比较大,通常会在第一步被预测出来,plant 和 bottle 比较小,一般会在第二步预测出来。也就是说第一步先预测出来 person,在 person 的帮助下,通常很容易在第二步和第三部预测出来 plant 和 bottle。经过这幅图和前面的那幅图可以得出,强化学习智能体是 能够针对每幅图的内容,按照从简单到复杂的顺序进行预测。
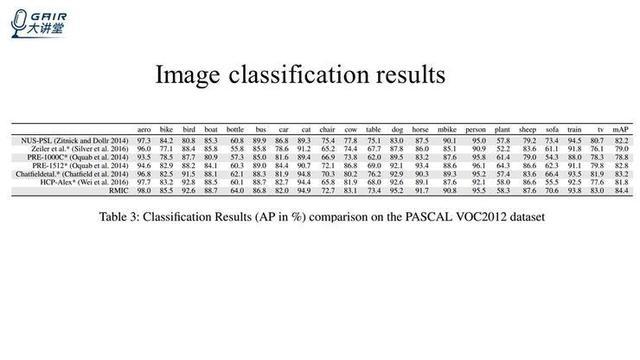
将实验算法和全监督的算法进行比较:
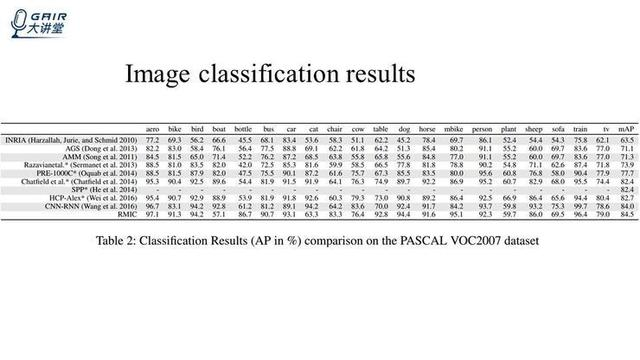
我们的算法在训练的时候有 reward,在测试的时候没有 reward,我们直接用输入的 Q 值作为置信度的分数来进行比较,上面的这些算法都是全监督的算法,最后这一行是我们的算法。可以看到,我们的算法和全监督的算法相当,甚至会优于这些全监督的算法,上图在 VOC2007 上的结果,下图是在 VOC2012 山的结果,我们算法的优势会更加明显一些,这些结果就说明我们的算法相较于全监督的算法相当,或者是有一些优势。
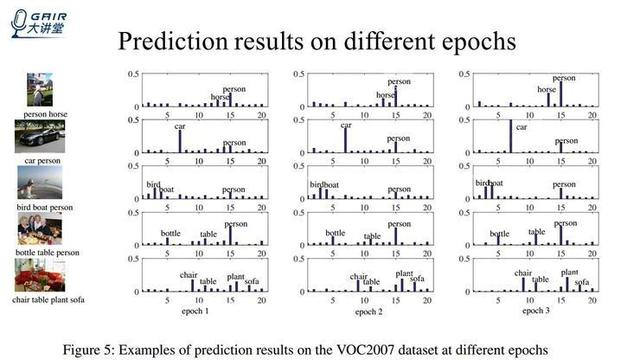
我们进一步分析了这个 RMIC 算法在不同的 epoch 的预测结果,这里一共列出来 3 个 epoch(竖排),观察这些图可以发现,从第一个 epoch 到第三个 epoch,预测出来的标签越来越明显,尤其是当标签个数比较多的时候,趋势会更加明显一些。然后我们挨个分析一下这几个图,刚开始 horse 的分数不是很高,随着 person 被预测出来,person 的分数越来越高,horse 的分数也会被预测出来。
- 观察第一幅图(竖排)可以发现,person 是比较容易预测的,horse 有部分遮挡和比较难预测的,这说明简单标签的预测可以帮助困难标签的预测。
- 第二幅图,car 比较显眼,基本都被遮挡或者不是很明显,我们可以看到当 car 的分数越来越高的时候,person 的分数也越来越高,也就说明,car 的预测有助于 person 的预测。
- 第四幅图,刚开始的时候,bottle 和 table 的 score 都不是很高,但是 person 的 score 是高于其他的标签的,随着 person 的 score 越来越高(越来越明显),然后 bottle 和 table 的 score 也越来越高,说明 person 的预测有助于 bottle 和 table 的预测。
- 第五幅图,我们可以看到 chair 的预测直接促进了 table 和 sofa 的预测。
结论

- 本文提出了强化多标签分类图像算法,这个算法模拟人类课程学习的机制,从简单到复杂的进行标签的预测。
- 在这个算法中,一个强化学习的智能体,使用图像的特征和之前预测过的标签作为状态,然后让标签作为动作,寻找一个使得预测准确率得到最高的策略。
- 我们在 VOC2007 和 VOC2012 上证明了我们的实验的有效性。
参考文献:

-----------------------------------------------------------
“本文转自雷锋网,如需转载请至雷锋网官网申请授权。”
--------------------------------------------------------------------------------------
【转载】 优必选悉尼 AI 研究院何诗怡:基于课程学习的强化多标签图像分类算法 | 分享总结的更多相关文章
- 艾伦AI研究院发布AllenNLP:基于PyTorch的NLP工具包
https://www.jiqizhixin.com/articles/2017-09-09-5 AllenNLP 可以让你轻松地设计和评估几乎所有 NLP 问题上最新的深度学习模型,并同基础设施一起 ...
- redhat自定义安装必选
redhat自定义安装必选 1.桌面 ked桌面 x 窗口系统 2.应用程序 编辑器 基于文本的互联网 图形互联网 3.服务器 服务器配置工具 万维网服务器 Windows文件 FTP服务器
- ASP.NET MVC验证标注的扩展-checkbox必选
我们知道ASP.NET mvc提供一些表单的验证标注,比如必填属性RequiredAttribute 但是这个属性不适合选择框的必选 但是很多时候,我们却是需要一些必选的单选框 比如网站注册的时候,需 ...
- saiku之固定维度(必选维度)
工作中遇到的问题,记录下来方便以后查找. 在saiku中如何设定固定维度? 找到WorkspaceDropZone.js文件,在synchronize_query: function(){}方法中的“ ...
- VUE新版扫码下单必选分类设置FAQ
使用场景:商家想要设置某些分类下的商品设置必选,否则不能下单.如某火锅店,商家想要设置汤底这个分类下的商品,顾客扫码下单的时候必须选择一份才能下单,此时 就可以使用这个功能 配置步骤和注意事项如下: ...
- python-在定义函数时,不定长参数中,默认值参数不能放在必选参数前面
如果一个函数的参数中含有默认参数,则这个默认参数后的所有参数都必须是默认参数,否则会报错:SyntaxError: non-default argument follows default argum ...
- js 判断 复选框全选、全不选、反选、必选一个
一个挺 使用的 js 代码片段, 判断 复选框全选.全不选.反选.必选一个 记录下, 搬来的 思路: 修改数据的 选中与否状态, 拿到所有的输入框,看是否有选中的状态 <html> & ...
- Python星号*与**用法分析 What does ** (double star/asterisk) and * (star/asterisk) do for parameters? 必选参数 默认参数 可变参数 关键字参数
python中*号**的区别 - CSDN博客 https://blog.csdn.net/qq_26815677/article/details/78091452 定义可变参数和定义 list 或 ...
- Python 必选参数,默认参数,可变参数,关键字参数和命名关键字参数
Py的参数还真是多,用起来还是很方便的,这么多参数种类可见它在工程上的实用性还是非常广泛的. 挺有意思的,本文主要参照Liaoxuefeng的Python教程. #必选参数 def quadratic ...
- 【转载】程序猿转型AI必须知道的几件事!
历史上AI火过两次,但是最终都已销声匿迹作为结束.这次AI大火的原因:AlphaGo 4比1战胜李世石,相对于一些外行人的恐慌和恐惧,其实很多业内人员在这场世纪之战结束后,都为人类点上了一个大大的赞. ...
随机推荐
- Ubuntu 更改鼠标滚轮速度
1.安装imwheel sudo apt-get install imwheel 2.更改配置 sudo gedit ~/.imwheelrc 输入以下内容: ".*"None, ...
- 修改带有强签名的DLL并重新生成
一.如果含有强签名,需要先使用去除强签名工具,这里使用的是"StrongNameRemove",点击修正就可以了,如果没有强签名可直接下一步: 二.将没有强签名的DLL进行反编译, ...
- == 和 equals 的区别是什么
== : 它的作用是判断两个对象的地址是不是相等.即,判断两个对象是不是同一个对象.(基本数据类型 == 比较的是值,引用数据类型 == 比较的是内存地址) equals() : 它的作用也是判断两个 ...
- python根据文件目录批量过滤空行
import shutil import os path = "E:\\in\\" #文件夹操作目录 path2 = "E:\\out\\" #文件夹输出目录 ...
- Linux curl支持http/https方法,Curl请求示例语法
Curl请求示例curl -X GET "http://<host:port>/api/1/test/get?test=<value>&app_id=< ...
- Puremvc
Puremvc 框架unitypuremvc PureMVC健壮.易扩展.易维护 Many so-called Model-View-Controller frameworks today seem ...
- 虚拟机安装Linux CENTOS 07 部署NET8 踩坑大全
首先下载centos07镜像,建议使用阿里云推荐的地址: https://mirrors.aliyun.com/centos/7.9.2009/isos/x86_64/?spm=a2c6h.25603 ...
- 高通LCD开发常见问题&分析
reference : https://blog.csdn.net/sinat_34606064/article/details/77921323 https://www.cnblogs.com/bi ...
- V4L2视频采集操作流程和接口说明
背景: V4L2是V4L的升级版本,为linux下视频设备程序提供了一套接口规范.包括一套数据结构和底层V4L2驱动接口. <WAV文件格式分析> 一般操作流程(视频设备): 1.打开设备 ...
- mysqldump备份时保持数据一致性分析--master-data=2 --single-transaction
对MySQL数据进行备份,常见的方式如以下三种,可能有很多人对备份时数据一致性并不清楚 1.直接拷贝整个数据目录下的所有文件到新的机器.优点是简单.快速,只需要拷贝:缺点也很明显,在整个备份过程中新机 ...