warmup预热学习率
学习率是神经网络训练中最重要的超参数之一,针对学习率的优化方式很多,Warmup是其中的一种
(一)、什么是Warmup?
Warmup是在ResNet论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps(比如4个epoches,10000steps),再修改为预先设置的学习来进行训练。
(二)、为什么使用Warmup?
由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
ExampleExampleExample:Resnet论文中使用一个110层的ResNet在cifar10上训练时,先用0.01的学习率训练直到训练误差低于80%(大概训练了400个steps),然后使用0.1的学习率进行训练。
(三)、Warmup的改进
(二)所述的Warmup是constant warmup,它的不足之处在于从一个很小的学习率一下变为比较大的学习率可能会导致训练误差突然增大。于是18年Facebook提出了gradual warmup来解决这个问题,即从最初的小学习率开始,每个step增大一点点,直到达到最初设置的比较大的学习率时,采用最初设置的学习率进行训练。
1.gradual warmup的实现模拟代码如下:
"""
Implements gradual warmup, if train_steps < warmup_steps, the
learning rate will be `train_steps/warmup_steps * init_lr`.
Args:
warmup_steps:warmup步长阈值,即train_steps<warmup_steps,使用预热学习率,否则使用预设值学习率
train_steps:训练了的步长数
init_lr:预设置学习率
"""
import numpy as np
warmup_steps = 2500
init_lr = 0.1
# 模拟训练15000步
max_steps = 15000
for train_steps in range(max_steps):
if warmup_steps and train_steps < warmup_steps:
warmup_percent_done = train_steps / warmup_steps
warmup_learning_rate = init_lr * warmup_percent_done #gradual warmup_lr
learning_rate = warmup_learning_rate
else:
#learning_rate = np.sin(learning_rate) #预热学习率结束后,学习率呈sin衰减
learning_rate = learning_rate**1.0001 #预热学习率结束后,学习率呈指数衰减(近似模拟指数衰减)
if (train_steps+1) % 100 == 0:
print("train_steps:%.3f--warmup_steps:%.3f--learning_rate:%.3f" % (
train_steps+1,warmup_steps,learning_rate))
2.上述代码实现的Warmup预热学习率以及学习率预热完成后衰减(sin or exp decay)的曲线图如下:
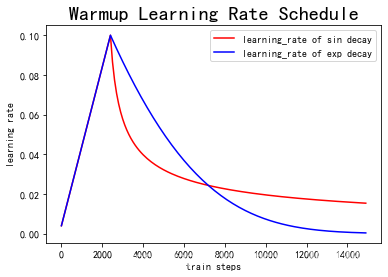
(四)总结
使用Warmup预热学习率的方式,即先用最初的小学习率训练,然后每个step增大一点点,直到达到最初设置的比较大的学习率时(注:此时预热学习率完成),采用最初设置的学习率进行训练(注:预热学习率完成后的训练过程,学习率是衰减的),有助于使模型收敛速度变快,效果更佳。
warmup预热学习率的更多相关文章
- RateLimiter的 SmoothBursty(非warmup预热)及SmoothWarmingUp(预热,冷启动)
SmoothBursty 主要思想 记录 1秒内的微秒数/permitsPerSencond = 时间间隔interval,每一个interval可获得一个令牌 根据允许使用多少秒内的令牌参数,计算出 ...
- CosineWarmup理论与代码实战
摘要:CosineWarmup是一种非常实用的训练策略,本次教程将带领大家实现该训练策略.教程将从理论和代码实战两个方面进行. 本文分享自华为云社区<CosineWarmup理论介绍与代码实战& ...
- Pytorch之训练器设置
Pytorch之训练器设置 引言 深度学习训练的时候有很多技巧, 但是实际用起来效果如何, 还是得亲自尝试. 这里记录了一些个人尝试不同技巧的代码. tensorboardX 说起tensorflow ...
- 性能调优必备利器之 JMH
if 快还是 switch 快?HashMap 的初始化 size 要不要指定,指定之后性能可以提高多少?各种序列化方法哪个耗时更短? 无论出自何种原因需要进行性能评估,量化指标总是必要的. 在大部分 ...
- Dubbo的负载均衡算法源码分析
Dubbo提供了四种负载均衡:RandomLoadBalance,RoundRobinLoadBalance,LeastActiveLoadBalance,ConsistentHashLoadBala ...
- 海华大赛第一名团队聊比赛经验和心得:AI在垃圾分类中的应用
摘要:为了探究垃圾的智能分类等问题,由中关村海华信息研究院.清华大学交叉信息研究院以及Biendata举办的2020海华AI垃圾分类大赛吸引了大量工程师以及高校学生的参与 01赛题介绍 随着我国经济的 ...
- JMH 使用指南
简介 JMH(Java Microbenchmark Harness)是用于代码微基准测试的工具套件,主要是基于方法层面的基准测试,精度可以达到纳秒级.该工具是由 Oracle 内部实现 JIT 的大 ...
- (八)使用 jmh 压测 Dubbo
1.JMH简介 JMH即Java Microbenchmark Harness,是Java用来做基准测试的一个工具,该工具由OpenJDK提供并维护,测试结果可信度高. 相对于 Jmeter.ab , ...
- 如何对SharePoint网站进行预热(warmup)以提高响应速度
问题描述 SharePoint Server是一个易于使用的协作平台,目前在越来越多的企业中被应用开来.SharePoint Server是通过网站的形式向最终用户提供服务的,而这个网站是基于ASP. ...
- [转帖]阿里的JDK预热warmup过程
预热warmup过程 https://blog.csdn.net/wabiaozia/article/details/82056520 Jwarmup 原理是记录上一次运行时已经变成native co ...
随机推荐
- Zabbix6.0使用教程 (二)—zabbix6.0常用术语
上一次我们已经详细介绍了zabbix6.0的新增功能,本篇我们来说说zabbix6.0常用的一些术语,这个对小伙伴日常使用zabbix的时候还是非常有用,建议大家收藏起来,话不多说,附上干货. 概览 ...
- 巧用SQL语句中的OR查询完成业务新需求-2022新项目
一.业务场景 目前参与开发的项目,之前的一个已上线的版本中有一类查询是根据两张表进行LEFT JOIN查询用来取数据, 主表中有一个字段field用来区分不同的数据类型比如说A/B/C.前面的版本中只 ...
- docker 资料整理
docker 资料整理 基础概念 docker deamon 守护系统:简单理解就是docker的软件系统,管控这容器的开关. docker容器:从镜像启动到内存中形成动态运行,从编程角度,如果镜像是 ...
- python 文件操作常用方法
一 python文件创建 import os import argparse def file_write(file_name,msg): f = open(file_name,"a&quo ...
- c语言中的指针,数组和结构体结合的一个经典案例
一 你真正懂了C语言了吗? 很多人刚把c语言用了两年,就以为很懂,等遇到稍微深层次一点的问题,就卡住了.这里,有一个问题,可以考察你对这三者理解如何. 二 一个例子: #include <std ...
- 利用log4j打印sql的log日志
默认情况下,使用ibatis是不打印ibatis相关的log的,因为内部的sql执行都是内部调用,在server的控制台是不 会 打印log的. 在log4j的配置文件log4j.properties ...
- java -jar xxx.jar命令执行jar包时出现Error: Invalid or corrupt jarfile xxx.jar解决方案
MANIFEST.MF清单文件内容: Manifest-Version: 1.0 Ant-Version: Apache Ant 1.8.2 Created-By: 1.8.0_60-b27 (Ora ...
- 5G时代,3DCAT助力AR/VR内容上云
一.5G网络三大应用场景 目前中国的5G技术正在加速发展,5G网络拥有增强型移动宽带.超高可靠低时延通信.海量机器类通信三大技术特点和应用场景.其中增强型移动宽带技术特点与AR&VR行业相关, ...
- 06.Android之消息机制问题
目录介绍 6.0.0.1 谈谈消息机制Hander作用?有哪些要素?流程是怎样的? 6.0.0.2 为什么一个线程只有一个Looper.只有一个MessageQueue,可以有多个Handler? 6 ...
- 【已解决】严重: Failed to initialize end point associated with ProtocolHandler ["http-bio-8080"]
Web开发项目中,启动Tomcat时出现错误 这是因为之前启动了Tomcat服务器,但是没有正常的关闭,造成8080端口号的进程依旧在系统后台运行着,导致Tomcat重启失败. cmd taskkil ...