Python爬取数据并保存到csv文件中
1、数据源
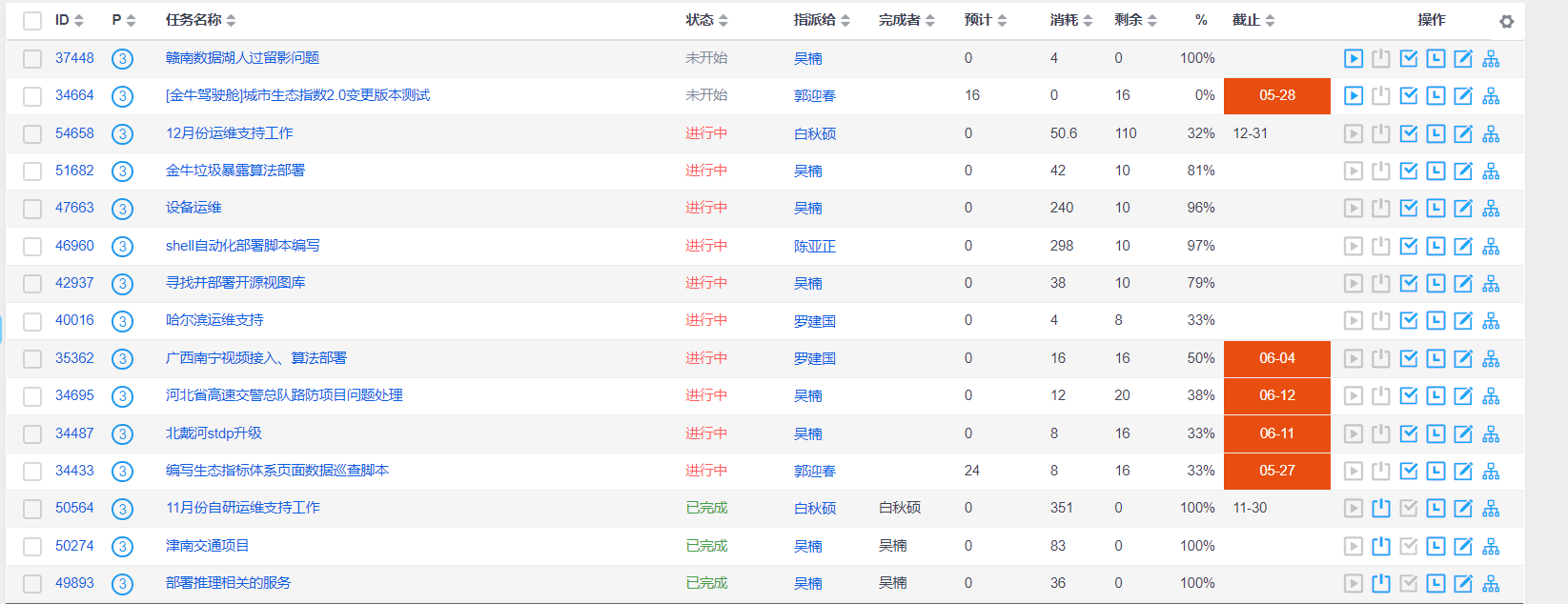
2、Python代码
import requests
from lxml import etree
import csv url = 'http://211.103.175.222:5080/zentaopms/www/index.php?m=project&f=task&projectID=830'
headers = {
'Cookie': 'lang=zh-cn; device=desktop; theme=default; feedbackView=0; lastProject=830; preProjectID=830; lastTaskModule=0; projectTaskOrder=status%2Cid_desc; pagerProjectTask=2000; keepLogin=on; za=zhangyh01; zp=2a7befd1193619083ca09e00e186dc709a5722c2; windowWidth=1707; windowHeight=679; zentaosid=revjktmd869d6q7ilfhrjp1bpn'
} res = requests.get(url,headers=headers)
res.encoding = 'utf-8' tree = etree.HTML(res.text)
trs = tree.xpath('//*[@id="taskList"]/tbody/tr')
f = open('result.csv',mode='w',newline='') # newline='':防止保存的csv文件有空行
csv_writer = csv.writer(f) for tr in trs:
id = tr.xpath('./td[1]/a/text()')[0]
jb = tr.xpath('./td[2]/span/text()')[0]
title = tr.xpath('./td[3]/a/text()')[0]
name = tr.xpath('./td[5]/a/span/text()')[0]
wcl = tr.xpath('./td[10]/text()')[0]
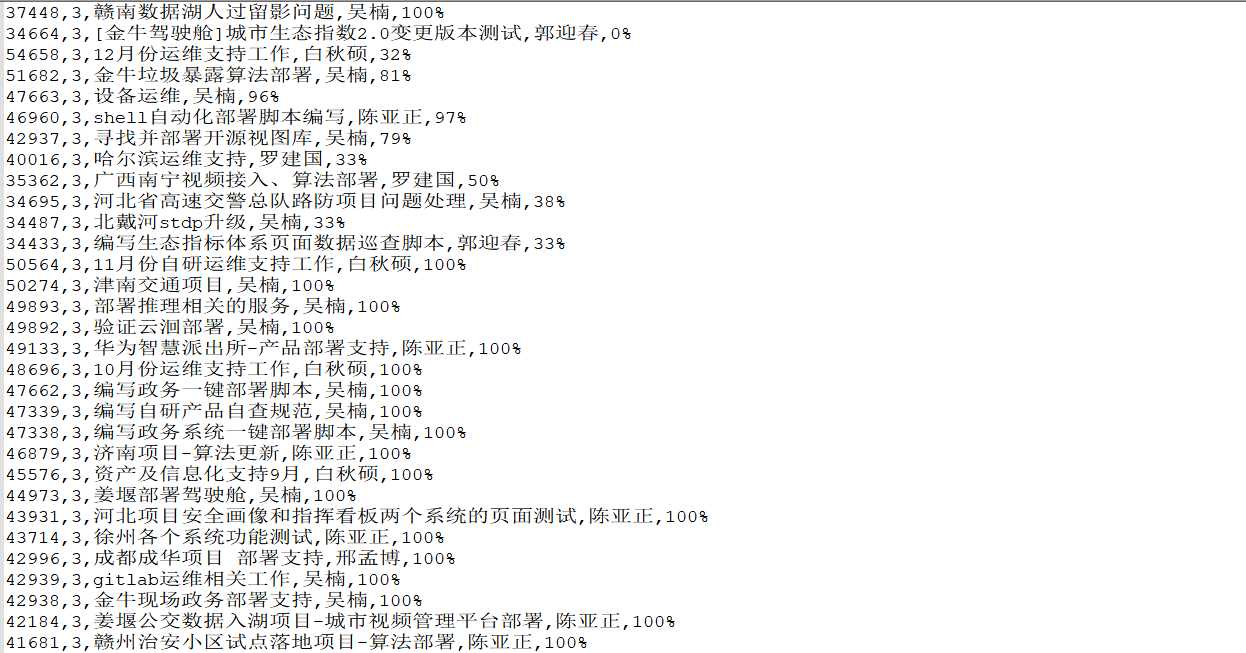
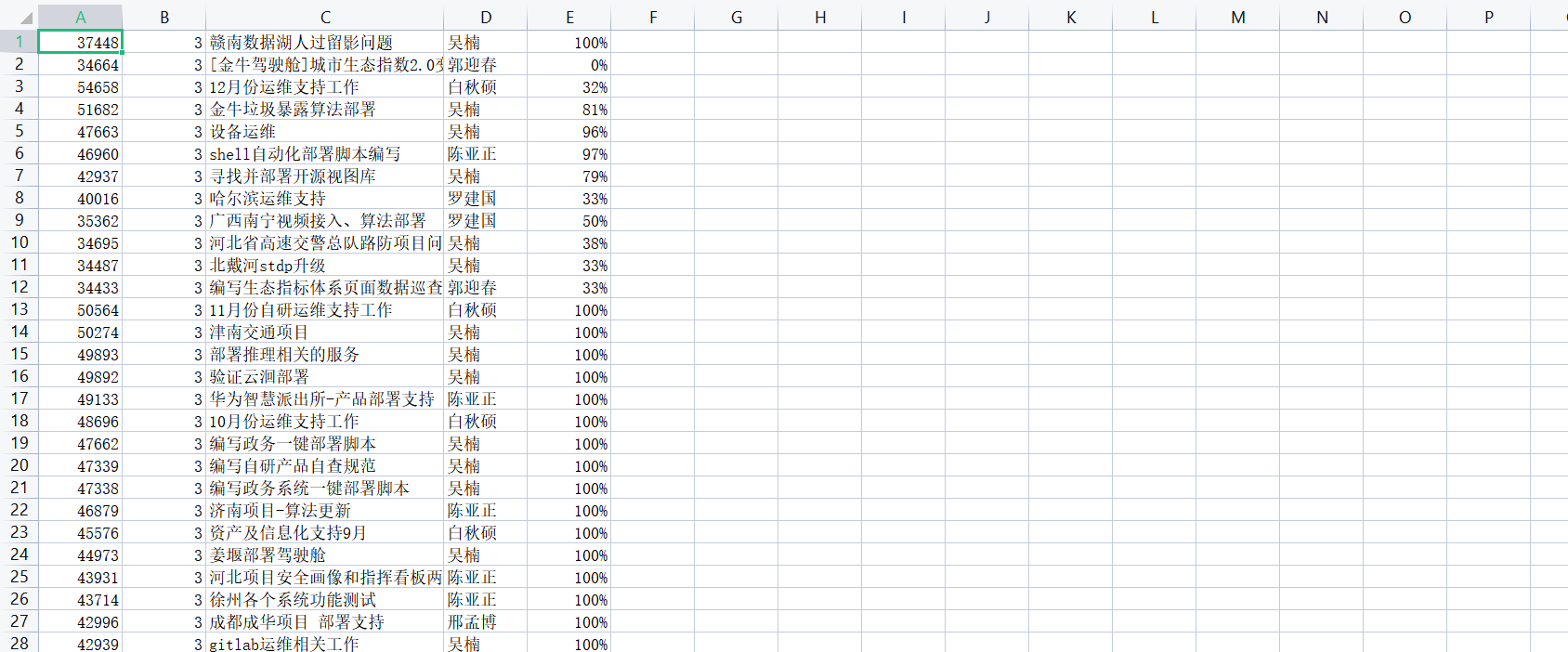
csv_writer.writerow([id,jb,title,name,wcl])
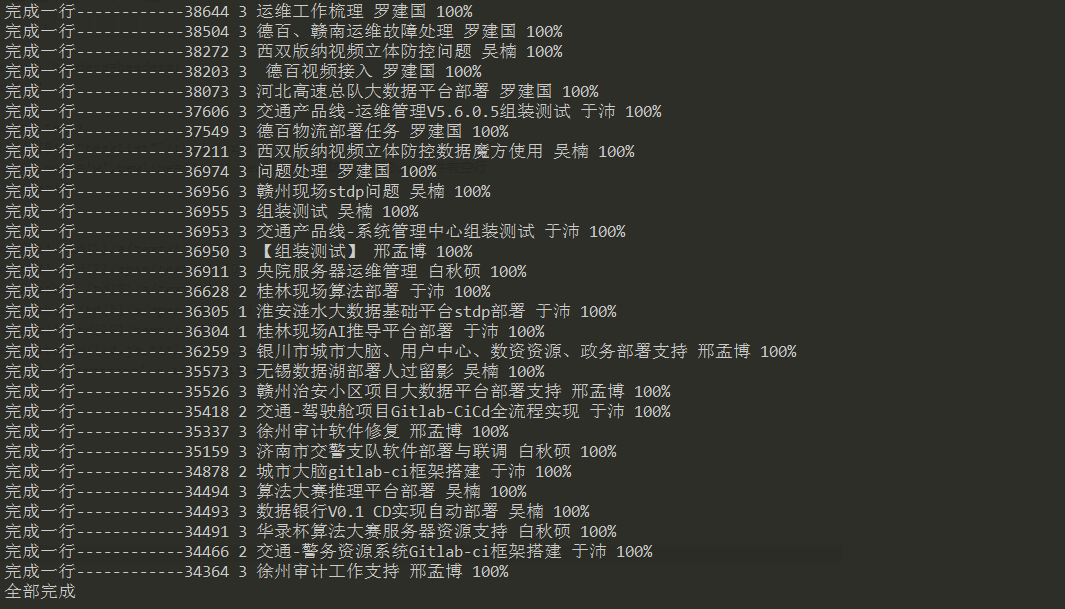
print('完成一行------------' + id,jb,title,name,wcl) f.close()
print('全部完成')
3、执行过程
4、保存的结果
Python爬取数据并保存到csv文件中的更多相关文章
- 使用scrapy爬取的数据保存到CSV文件中,不使用命令
pipelines.py文件中 import codecs import csv # 保存到CSV文件中 class CsvPipeline(object): def __init__(self): ...
- 使用pandas中的raad_html函数爬取TOP500超级计算机表格数据并保存到csv文件和mysql数据库中
参考链接:https://www.makcyun.top/web_scraping_withpython2.html #!/usr/bin/env python # -*- coding: utf-8 ...
- 实现多线程爬取数据并保存到mongodb
多线程爬取二手房网页并将数据保存到mongodb的代码: import pymongo import threading import time from lxml import etree impo ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
- node 爬虫 --- 将爬取到的数据,保存到 mysql 数据库中
步骤一:安装必要模块 (1)cheerio模块 ,一个类似jQuery的选择器模块,分析HTML利器. (2)request模块,让http请求变的更加简单 (3)mysql模块,node连接mysq ...
- Python爬取爬取明星关系并写入csv文件
今天用Python爬取了明星关系,数据不多,一共1386条数据,代码如下: import requests from bs4 import BeautifulSoup import bs4 impor ...
- 直接把数据库中的数据保存在CSV文件中
今天突然去聊就来写一个小小的demo喽,嘿嘿 public partial class Form1 : Form { public Form1() { InitializeComponent(); } ...
- python爬取数据保存到Excel中
# -*- conding:utf-8 -*- # 1.两页的内容 # 2.抓取每页title和URL # 3.根据title创建文件,发送URL请求,提取数据 import requests fro ...
- python爬取数据需要注意的问题
1 爬取https的网站或是接口的时候,如果是不受信用的SSL证书,会报错,需要添加如下代码,如下代码可以保证当前代码块内所有的请求都自动屏蔽ssl证书问题: import ssl # 这个是爬取ht ...
- python爬取数据保存入库
import urllib2 import re import MySQLdb class LatestTest: #初始化 def __init__(self): self.url="ht ...
随机推荐
- MogDB/openGauss中merge的语法解析
MogDB/openGauss 中 merge 的语法解析 近期了解学习了 MogDB/openGauss 中 merge 的使用,merge 语法是根据源表对目标表进行匹配查询,匹配成功时更新,不成 ...
- Tailwind CSS 使用指南
0x01 概述 (1)简介 Tailwind CSS 官网:https://www.tailwindcss.cn/ Tailwind CSS 是一个 CSS 框架,使用初级"工具" ...
- centos6.5源码编译http2.4.9、虚拟主机、基于用户认证
centos6.5源码编译http2.4.9.虚拟主机.基于用户认证 2014-04-23 07:45 作者: 51linux 来源: 本站 浏览: 0 views 我要评论 字号: 大 中 ...
- mysql 必知必会整理—sql 计算函数[六]
前言 简单整理一下sql的计算函数. 正文 函数没有SQL的可移植性强 能运行在多个系统上的代码称为可移植的(portable).相对来说,多数SQL语句是可移植的,在SQL实现之间有差异时,这些差异 ...
- mysql 重新整理——七种连接join连接[六]
前言 总结一下其中join连接. 正文 又到了盗图时刻: 上面标记好了顺序. 第一种: select * from A a left join B b on a.key=b.key 这里解释一下,这里 ...
- 深度解读《深度探索C++对象模型》之拷贝构造函数
接下来我将持续更新"深度解读<深度探索C++对象模型>"系列,敬请期待,欢迎关注!也可以关注公众号:iShare爱分享,自动获得推文. 写作不易,请有心人到我的公众号上 ...
- 简述Linux磁盘IO
1.什么是磁盘 在讲解磁盘IO前,先简单说下什么是磁盘.磁盘是可以持久化存储的设备,根据存储介质的不同,常见磁盘可以分为两类:机械磁盘和固态磁盘. 1.1 机械磁盘 第一类,机械磁盘,也称为硬盘驱动器 ...
- pypinyin 获取拼音,作为智能设备的唤醒比对结果
from pypinyin import lazy_pinyin,TONE,TONE2,TONE3,NORMAL a = "小七同学" b = "小琦同学" c ...
- 力扣442(java)-数组中重复的数据(中等)
题目: 给你一个长度为 n 的整数数组 nums ,其中 nums 的所有整数都在范围 [1, n] 内,且每个整数出现 一次 或 两次 .请你找出所有出现 两次 的整数,并以数组形式返回. 你必须设 ...
- 5G新基建 边缘计算乘风破浪
作者 | 张羽辰(同昭)阿里云交付专家 导读:如今,几乎所有的事情都离不开软件,当你开车时,脚踩上油门,实际上是车载计算机通过力度感应等计算输出功率,最终来控制油门,你从未想过这会是某个工程师的代码. ...