机器学习:详解是否要使用端到端的深度学习?(Whether to use end-to-end learning?)
详解是否要使用端到端的深度学习?
假设正在搭建一个机器学习系统,要决定是否使用端对端方法,来看看端到端深度学习的一些优缺点,这样就可以根据一些准则,判断的应用程序是否有希望使用端到端方法。

这里是应用端到端学习的一些好处,首先端到端学习真的只是让数据说话。所以如果有足够多的\((x,y)\)数据,那么不管从\(x\)到\(y\)最适合的函数映射是什么,如果训练一个足够大的神经网络,希望这个神经网络能自己搞清楚,而使用纯机器学习方法,直接从\(x\)到\(y\)输入去训练的神经网络,可能更能够捕获数据中的任何统计信息,而不是被迫引入人类的成见。
例如,在语音识别领域,早期的识别系统有这个音位概念,就是基本的声音单元,如cat单词的“cat”的Cu-、Ah-和Tu-,觉得这个音位是人类语言学家生造出来的,实际上认为音位其实是语音学家的幻想,用音位描述语言也还算合理。但是不要强迫的学习算法以音位为单位思考,这点有时没那么明显。如果让的学习算法学习它想学习的任意表示方式,而不是强迫的学习算法使用音位作为表示方式,那么其整体表现可能会更好。
端到端深度学习的第二个好处就是这样,所需手工设计的组件更少,所以这也许能够简化的设计工作流程,不需要花太多时间去手工设计功能,手工设计这些中间表示方式。

那么缺点呢?这里有一些缺点,首先,它可能需要大量的数据。要直接学到这个\(x\)到\(y\)的映射,可能需要大量\((x,y)\)数据。在以前看过一个例子,其中可以收集大量子任务数据,比如人脸识别,可以收集很多数据用来分辨图像中的人脸,当找到一张脸后,也可以找得到很多人脸识别数据。但是对于整个端到端任务,可能只有更少的数据可用。所以\(x\)这是端到端学习的输入端,\(y\)是输出端,所以需要很多这样的\((x,y)\)数据,在输入端和输出端都有数据,这样可以训练这些系统。这就是为什么称之为端到端学习,因为直接学习出从系统的一端到系统的另一端。
另一个缺点是,它排除了可能有用的手工设计组件。机器学习研究人员一般都很鄙视手工设计的东西,但如果没有很多数据,的学习算法就没办法从很小的训练集数据中获得洞察力。所以手工设计组件在这种情况,可能是把人类知识直接注入算法的途径,这总不是一件坏事。觉得学习算法有两个主要的知识来源,一个是数据,另一个是手工设计的任何东西,可能是组件,功能,或者其他东西。所以当有大量数据时,手工设计的东西就不太重要了,但是当没有太多的数据时,构造一个精心设计的系统,实际上可以将人类对这个问题的很多认识直接注入到问题里,进入算法里应该挺有帮助的。
所以端到端深度学习的弊端之一是它把可能有用的人工设计的组件排除在外了,精心设计的人工组件可能非常有用,但它们也有可能真的伤害到的算法表现。例如,强制的算法以音位为单位思考,也许让算法自己找到更好的表示方法更好。所以这是一把双刃剑,可能有坏处,可能有好处,但往往好处更多,手工设计的组件往往在训练集更小的时候帮助更大。

如果在构建一个新的机器学习系统,而在尝试决定是否使用端到端深度学习,认为关键的问题是,有足够的数据能够直接学到从\(x\)映射到\(y\)足够复杂的函数吗?还没有正式定义过这个词“必要复杂度(complexity needed)”。但直觉上,如果想从\(x\)到\(y\)的数据学习出一个函数,就是看着这样的图像识别出图像中所有骨头的位置,那么也许这像是识别图中骨头这样相对简单的问题,也许系统不需要那么多数据来学会处理这个任务。或给出一张人物照片,也许在图中把人脸找出来不是什么难事,所以也许不需要太多数据去找到人脸,或者至少可以找到足够数据去解决这个问题。相对来说,把手的X射线照片直接映射到孩子的年龄,直接去找这种函数,直觉上似乎是更为复杂的问题。如果用纯端到端方法,需要很多数据去学习。
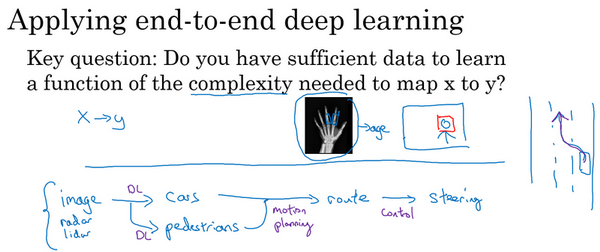
最后讲一个更复杂的例子,可能知道一直在花时间帮忙主攻无人驾驶技术的公司drive.ai,无人驾驶技术的发展其实让相当激动,怎么造出一辆自己能行驶的车呢?好,这里可以做一件事,这不是端到端的深度学习方法,可以把车前方的雷达、激光雷达或者其他传感器的读数看成是输入图像。但是为了说明起来简单,就说拍一张车前方或者周围的照片,然后驾驶要安全的话,必须能检测到附近的车,也需要检测到行人,需要检测其他的东西,当然,这里提供的是高度简化的例子。
弄清楚其他车和形如的位置之后,就需要计划自己的路线。所以换句话说,当看到其他车子在哪,行人在哪里,需要决定如何摆方向盘在接下来的几秒钟内引导车子的路径。如果决定了要走特定的路径,也许这是道路的俯视图,这是的车,也许决定了要走那条路线,这是一条路线,那么就需要摆动的方向盘到合适的角度,还要发出合适的加速和制动指令。所以从传感器或图像输入到检测行人和车辆,深度学习可以做得很好,但一旦知道其他车辆和行人的位置或者动向,选择一条车要走的路,这通常用的不是深度学习,而是用所谓的运动规划软件完成的。如果学过机器人课程,一定知道运动规划,然后决定了的车子要走的路径之后。还会有一些其他算法,说这是一个控制算法,可以产生精确的决策确定方向盘应该精确地转多少度,油门或刹车上应该用多少力。

所以这个例子就表明了,如果想使用机器学习或者深度学习来学习某些单独的组件,那么当应用监督学习时,应该仔细选择要学习的\(x\)到\(y\)映射类型,这取决于那些任务可以收集数据。相比之下,谈论纯端到端深度学习方法是很激动人心的,输入图像,直接得出方向盘转角,但是就目前能收集到的数据而言,还有今天能够用神经网络学习的数据类型而言,这实际上不是最有希望的方法,或者说这个方法并不是团队想出的最好用的方法。而认为这种纯粹的端到端深度学习方法,其实前景不如这样更复杂的多步方法。因为目前能收集到的数据,还有现在训练神经网络的能力是有局限的。
这就是端到端的深度学习,有时候效果拔群。但也要注意应该在什么时候使用端到端深度学习。
机器学习:详解是否要使用端到端的深度学习?(Whether to use end-to-end learning?)的更多相关文章
- 【机器学习详解】SMO算法剖析(转载)
[机器学习详解]SMO算法剖析 转载请注明出处:http://blog.csdn.net/luoshixian099/article/details/51227754 CSDN−勿在浮沙筑高台 本文力 ...
- 机器学习 | 详解GBDT在分类场景中的应用原理与公式推导
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第31篇文章,我们一起继续来聊聊GBDT模型. 在上一篇文章当中,我们学习了GBDT这个模型在回归问题当中的原理.GBD ...
- TVM:一个端到端的用于开发深度学习负载以适应多种硬件平台的IR栈
TVM:一个端到端的用于开发深度学习负载以适应多种硬件平台的IR栈 本文对TVM的论文进行了翻译整理 深度学习如今无处不在且必不可少.这次创新部分得益于可扩展的深度学习系统,比如 TensorFlo ...
- 机器学习--详解人脸对齐算法SDM-LBF
引自:http://blog.csdn.net/taily_duan/article/details/54584040 人脸对齐之SDM(Supervised Descent Method) 人脸对齐 ...
- 机器学习——详解经典聚类算法Kmeans
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第12篇文章,我们一起来看下Kmeans聚类算法. 在上一篇文章当中我们讨论了KNN算法,KNN算法非常形象,通过距离公 ...
- 机器学习 | 详解GBDT梯度提升树原理,看完再也不怕面试了
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第30篇文章,我们今天来聊一个机器学习时代可以说是最厉害的模型--GBDT. 虽然文无第一武无第二,在机器学习领域并没有 ...
- 详解 Facebook 田渊栋 NIPS2017 论文:深度强化学习研究的 ELF 平台
这周,机器学习顶级会议 NIPS 2017 的论文评审结果已经通知到各位论文作者了,许多作者都马上发 Facebook/Twitter/Blog/ 朋友圈分享了论文被收录的喜讯.大家的熟人 Faceb ...
- 详解zabbix安装部署(Server端篇)
原文:http://blog.chinaunix.net/uid-25266990-id-3380929.html Linux下常用的系统监控软件有Nagios.Cacti.Zabbix.Monit等 ...
- 详解zabbix安装部署(Server端篇) (转)
Linux下常用的系统监控软件有Nagios.Cacti.Zabbix.Monit等,这些开源的软件,可以帮助我们更好的管理机器,在第一时间内发现,并警告系统维护人员. 今天开始研究下Zabbix,使 ...
- 在windows下详解:大端对齐和小端对齐
计算机的内存最小单位是什么?是BYTE,是字节.一个大于BYTE的数据类型在内存中存放的时候要有先后顺序. 高内存地址放整数的高位,低内存地址放整数的低位,这种方式叫倒着放,术语叫小端对齐.电脑X86 ...
随机推荐
- itest(爱测试) 4.5.5 发布,开源BUG 跟踪管理 & 敏捷测试管理&极简项目管理软件
itest 简介 itest 开源敏捷测试管理,testOps 践行者,极简的任务管理,测试管理,缺陷管理,测试环境管理4合1,又有丰富的统计分析.可按测试包分配测试用例执行,也可建测试迭代(含任务, ...
- CF98C Help Greg the Dwarf 题解
CF98C Help Greg the Dwarf 题解 为什么不三分? 首先我们考虑如何求出答案. 如图,考虑设夹角为 \(\theta\),那么可以得到表达式: \[[\cfrac a {\tan ...
- 连续段 dp - 状态转移时依赖相邻元素的序列计数问题
引入 在一类序列计数问题中,状态转移的过程可能与相邻的已插入元素的具体信息相关. 这类问题通常的特点是,如果只考虑在序列的一侧插入,问题将容易解决. 枚举插入顺序的复杂度通常难以接受,转移时枚举插入位 ...
- go 1.6 废弃 io/ioutil 包后的替换函数
go 1.6 废弃 io/ioutil 包后的替换函数 io/ioutil 替代 ioutil.ReadAll -> io.ReadAll ioutil.ReadFile -> os.R ...
- 利用夜莺开源版对H3C无线设备监控
编者荐语:真正搞监控的人肯定知道 SNMP 水有多深,有时我甚至腹黑猜测,这些厂商是故意的吧,,,指标不标准,格式各异,只能靠一款灵活的采集器了,本文是夜莺社区用户写的文章,转给大家参考. autho ...
- 非空处理 Java非空判断 非空处理及mysql数据库字段的not null
1.mysql## 去掉非空,如果非空又没有默认值,这样程序在添加数据的时候i,如果没有设置值就会报错.该操作很危险.##ALTER TABLE `order_test` ADD COLUMN `te ...
- 一文了解Spark引擎的优势及应用场景
Spark引擎诞生的背景 Spark的发展历程可以追溯到2009年,由加州大学伯克利分校的AMPLab研究团队发起.成为Apache软件基金会的孵化项目后,于2012年发布了第一个稳定版本. 以下是S ...
- 解决Mixed Content:the page at‘https://' was loaded over HTTPS,but requested an insecure resource 'http://'
问题:在Vue项目中使用axios访问了一个http协议的接口,报错如下 查资料后发现原因是在https中请求http接口或引入http资源都会被直接blocked(阻止),浏览器默认此行为不安全,会 ...
- C++判断当前程序是否运行在Windows展台(Kiosk)模式下
Windows有一个展台(Kiosk)模式.展台模式可以使Windows作为数字标牌进行使用.具体请参考Windows 展台 配置完展台模式,重启设备后,Windows会以全屏的方式运行展台应用,无法 ...
- 汇总:"undefined reference to" 问题解决方法
背景 在Linux下编程容易出现的现象,就是在链接多文件的时候总是报错,类似下面这样的错误: (.text+0x13): undefined reference to `func' 关于undefin ...