spark读取hive表,org.apache.spark.sql.AnalysisException: Unsupported data source type for direct query on files: hive;
异常出现:spark读取hive表时,spark.read.table(hive.test)
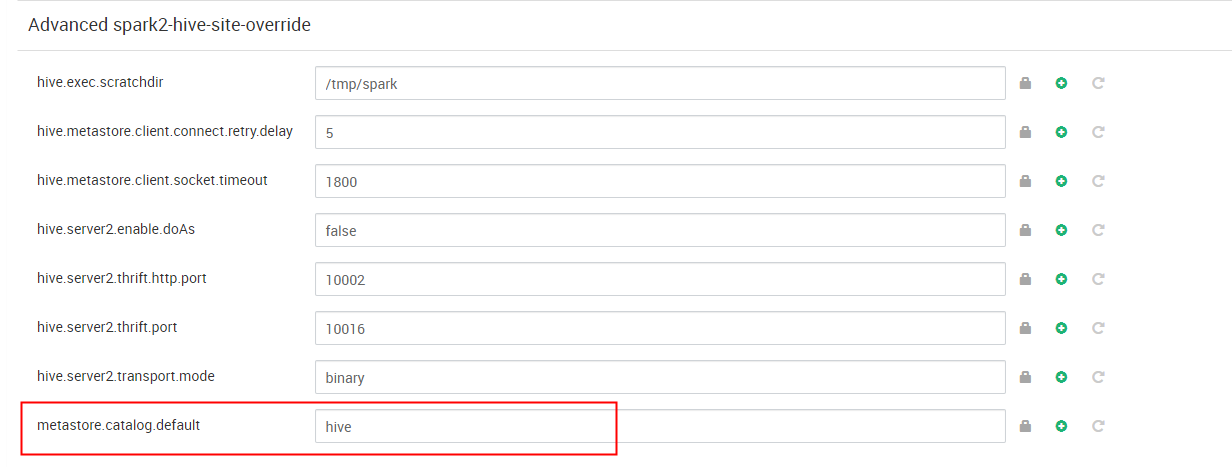
hdp版本的spark默认的catalog是spark,配置项 metastore.catalog.default 默认值是spark,即读取SparkSQL自己的metastore_db。所以才会出现上述相互是查看不到的对方的创建的数据的问题。
org.apache.spark.sql.AnalysisException: Unsupported data source type for direct query on files: hive;;
at org.apache.spark.sql.catalyst.analysis.package$AnalysisErrorAt.failAnalysis(package.scala:47)
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile$$anonfun$apply$1.applyOrElse(rules.scala:64)
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile$$anonfun$apply$1.applyOrElse(rules.scala:42)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformUp$1.apply(TreeNode.scala:289)
at org.apache.spark.sql.catalyst.trees.TreeNode$$anonfun$transformUp$1.apply(TreeNode.scala:289)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:70)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformUp(TreeNode.scala:288)
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile.apply(rules.scala:42)
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile.apply(rules.scala:37)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:87)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1$$anonfun$apply$1.apply(RuleExecutor.scala:84)
at scala.collection.LinearSeqOptimized$class.foldLeft(LinearSeqOptimized.scala:124)
at scala.collection.immutable.List.foldLeft(List.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:84)
at org.apache.spark.sql.catalyst.rules.RuleExecutor$$anonfun$execute$1.apply(RuleExecutor.scala:76)
at scala.collection.immutable.List.foreach(List.scala:381)
at org.apache.spark.sql.catalyst.rules.RuleExecutor.execute(RuleExecutor.scala:76)
at org.apache.spark.sql.catalyst.analysis.Analyzer.org$apache$spark$sql$catalyst$analysis$Analyzer$$executeSameContext(Analyzer.scala:124)
at org.apache.spark.sql.catalyst.analysis.Analyzer.execute(Analyzer.scala:118)
at org.apache.spark.sql.catalyst.analysis.Analyzer.executeAndCheck(Analyzer.scala:103)
at org.apache.spark.sql.execution.QueryExecution.analyzed$lzycompute(QueryExecution.scala:57)
at org.apache.spark.sql.execution.QueryExecution.analyzed(QueryExecution.scala:55)
at org.apache.spark.sql.execution.QueryExecution.assertAnalyzed(QueryExecution.scala:47)
at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:74)
at org.apache.spark.sql.SparkSession.table(SparkSession.scala:628)
at org.apache.spark.sql.SparkSession.table(SparkSession.scala:624)
at org.apache.spark.sql.DataFrameReader.table(DataFrameReader.scala:654)
... 49 elided
Caused by: org.apache.spark.sql.AnalysisException: Unsupported data source type for direct query on files: hive;
at org.apache.spark.sql.execution.datasources.ResolveSQLOnFile$$anonfun$apply$1.applyOrElse(rules.scala:56)
... 74 more
spark读取hive表,org.apache.spark.sql.AnalysisException: Unsupported data source type for direct query on files: hive;的更多相关文章
- 【原创】大叔经验分享(60)hive和spark读取kudu表
从impala中创建kudu表之后,如果想从hive或spark sql直接读取,会报错: Caused by: java.lang.ClassNotFoundException: com.cloud ...
- Spark(1) - Getting Started with Apache Spark
Introduction Apache Spark is a general-purpose cluster computing system to process big data workload ...
- java.lang.NoSuchMethodError: org.apache.spark.internal.Logging.$init$(Lorg/apache/spark/internal/Logging;)V
1.sparkML的版本不对应 请参考官网找到对于版本, 比如我的 spark2.3.3 spark MLlib 也是2.3.3
- Caused by: java.sql.SQLException: Failed to start database 'metastore_db' with class loader org.apache.spark.sql.hive.client.IsolatedClientLoader$$anon$1@d7c365, see the next exception for details.
解决方法:https://stackoverflow.com/questions/37442910/spark-shell-startup-errors 异常: 18/01/29 19:04:27 W ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- spark相关介绍-提取hive表(一)
本文环境说明 centos服务器 jupyter的scala核spylon-kernel spark-2.4.0 scala-2.11.12 hadoop-2.6.0 本文主要内容 spark读取hi ...
- Spark访问与HBase关联的Hive表
知识点1:创建关联Hbase的Hive表 知识点2:Spark访问Hive 知识点3:Spark访问与Hbase关联的Hive表 知识点1:创建关联Hbase的Hive表 两种方式创建,内部表和外部表 ...
- Spark记录-本地Spark读取Hive数据简单例子
注意:将mysql的驱动包拷贝到spark/lib下,将hive-site.xml拷贝到项目resources下,远程调试不要使用主机名 import org.apache.spark._ impor ...
- 新手福利:Apache Spark入门攻略
[编者按]时至今日,Spark已成为大数据领域最火的一个开源项目,具备高性能.易于使用等特性.然而作为一个年轻的开源项目,其使用上存在的挑战亦不可为不大,这里为大家分享SciSpike软件架构师Ash ...
随机推荐
- Go语言入门分享
简介: Go语言出自Ken Thompson.Rob Pike和Robert Griesemer之手,起源于2007年,并在2009年正式对外发布.Go的主要目标是"兼具Python等动态 ...
- [LLM] 开源 AI 大语言模型的本地化定制实践
LLM(Large Language Model,大型语言模型)是一种基于深度学习的自然语言处理模型,旨在理解和生成人类语言. 它们在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结.翻 ...
- WPF 已知问题 RadioButton 指定 GroupName 后关闭窗口可能导致无法选中
本文记录一个 WPF 已知问题,当 WPF 的 RadioButton 指定 GroupName 且将 IsChecked 状态绑定到 ViewModel 上,将包含以上控件的代码的窗口显示两个,接着 ...
- EPAI手绘建模APP常用工具栏_1
1.常用工具栏 图 1 常用工具栏 (1) 撤销 (2) 重做 (3) 删除 (4) 复制 ① 选中场景中的模型后,复制按钮变成可用状态,否则变成禁用状态.可以选择多个模型一起复制. (5) 变换 图 ...
- Linux内核之SPI协议
SPI(Serial Peripheral Interface,串行外设接口)是一种同步串行的行业标准,但是并没有像I2C那样有标准文档,它还有主从.可片选的特性. 图源自Serial Periphe ...
- join分析:shuffle hash join、broadcast hash join
Join 背景介绍 Join 是数据库查询永远绕不开的话题,传统查询 SQL 技术总体可以分为简单操作(过滤操作.排序操作 等),聚合操作-groupby 以及 Join 操作等.其中 Join 操作 ...
- apisix~lua插件开发与插件注册
开发插件的步骤 在APISIX中,要自定义插件,一般需要按照以下步骤进行操作: 编写Lua脚本:首先,你需要编写Lua脚本来实现你想要的功能.可以根据APISIX提供的插件开发文档和示例进行编写. 将 ...
- 网络安全—SSL安全访问应用
文章目录 网络拓扑 部署CA服务器颁发证书 开启Web服务 安装IIS服务 修改Web默认网页 申请Web证书 前提准备 申请文件生成 申请web证书 开始安装web证书 客户机访问web默认网站 使 ...
- 微信小程序 canvas 手写签名(2d)
canvas 2d 目前支持预览,不支持真机调试 index.wxml <canvas type="2d" id="canvas" bindtouchmo ...
- Github打不开解决办法(最新有效)
Github打不开解决办法(最新有效) 1. 先看没解决之前的截图: 2. 解决方法(手动修改DNS): 2.1 以win11为例,第一步:打开 设置 - 网络和Internet,找到 高级网络 ...