分组聚合不再难:Pandas groupby使用指南
处理大量数据时,经常需要对数据进行分组和汇总,groupby为我们提供了一种简洁、高效的方式来实现这些操作,从而简化了数据分析的流程。
1. 分组聚合是什么
分组是指根据一个或多个列的值将数据分成多个组,每个组包含具有相同键值(这里的键值即用来分组的列值)的数据行。
聚合或者汇总则是指,在分组后,可以对每个组应用聚合函数(如求和、平均值、计数等),从而得到每个组的汇总信息。
2. 准备数据
下面的示例中使用的数据采集自A股2024年1月和2月的真实交易数据。
数据下载地址:https://databook.top/。
导入数据:
import pandas as pd
fp = r'D:\data\2024\历史行情数据-不复权-2024.csv'
df = pd.read_csv(fp)
df = df.loc[:, ["股票代码", "日期", "开盘", "收盘", "最高", "最低", "成交量"]]
df

3. groupby 使用示例
下面通过具体的示例演示groupby常用的使用方法。
3.1. 单列分组再聚合
单列聚合是指针对某一列汇总计算,比如:
针对“股票代码”聚合,看看不同股票的开盘价和收盘价的平均值。
# 只保留需要的列
data = df.loc[:, ["股票代码", "开盘", "收盘"]]
# 根据股票代码聚合平均值
data.groupby(by=["股票代码"]).mean()
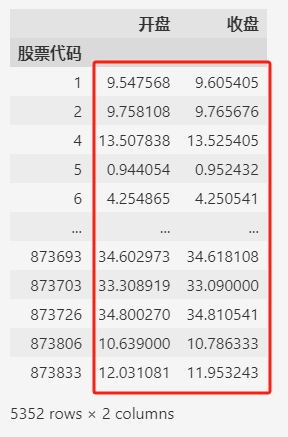
一共5352支股票,聚合之后,红色框内的是每支股票开盘价和收盘价的平均值。
3.2. 多列分组再聚合
多列分组聚合时,按照groupby中by参数的顺序,依次进行分组,然后再聚合。
本次的使用的数据包含2024年1月和2月的数据,
我们先按照“股票代码”分组,再按“月份”分组,最后汇总信息。
聚合之前,先把日期的格式转换成月的形式:
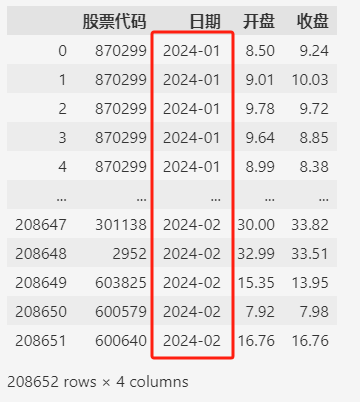
data = df.loc[:, ["股票代码", "日期", "开盘", "收盘"]]
data["日期"] = data["日期"].str.slice(0, 7)
data
根据“股票代码”和“日期”来聚合每支股票每个月的开盘价和收盘价的最大值:
data.groupby(by=["股票代码", "日期"]).max()
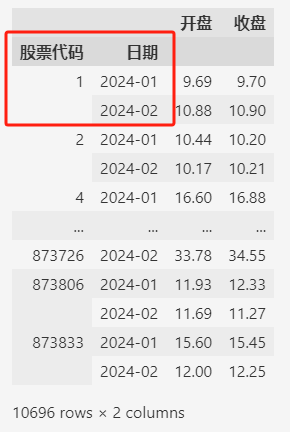
聚合之后的DataFrame,有2个Index(索引)。
3.3. 一次分组多次聚合
聚合汇总信息时,可以一次汇总多个信息,这样分组一次就可以了,不用每次聚合都重复调用groupby去分组。
比如,下面的示例一次汇总出每支股票每个月开盘价和收盘价的最大值,最小值,平均值:
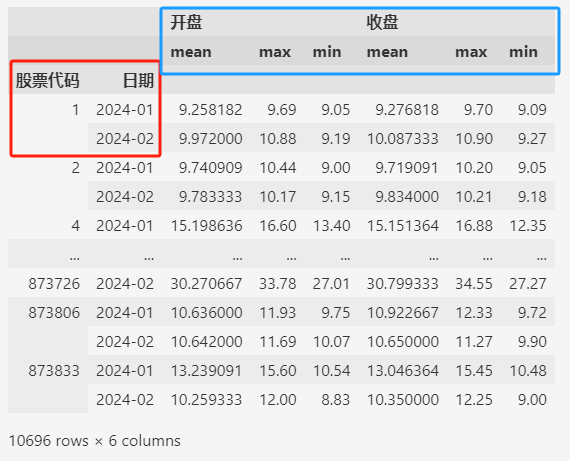
data.groupby(by=["股票代码", "日期"]).agg(["mean", "max", "min"])
3.4. 定制分组的聚合方式
更进一步,我们还可以针对不同的列采用不同的聚合方式。
比如,对开盘价汇总最大值和平均值,对收盘价汇总最小值和平均值:
data.groupby(by=["股票代码", "日期"]).agg(
{
"开盘": ["max", "mean"],
"收盘": ["min", "mean"],
}
)
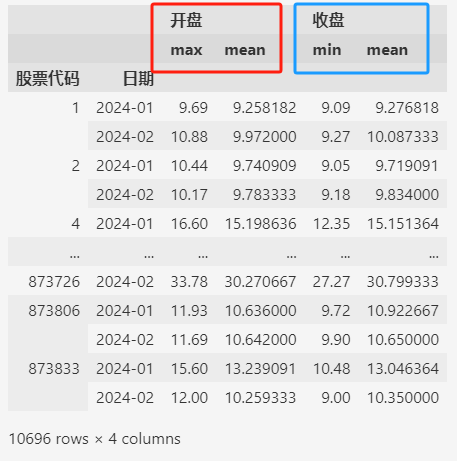
3.5. 聚合后重置索引
从上面聚合后数据的截图中,可以发现,聚合之后,分组用的列(比如 ["股票代码", "日期"])变为索引。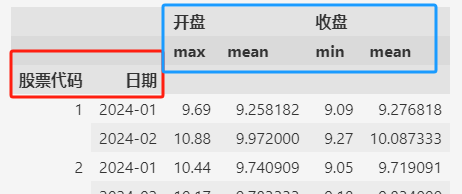
如上所示,聚合之后返回的DataFrame,红色框内的是索引(index),蓝色框内的是列(columns)。
如果,我们希望分组聚合统计之后,分组的列(比如 ["股票代码", "日期"])仍然作为DataFrame的列,
可以在groupby分组时使用as_index=False参数。
data.groupby(by=["股票代码", "日期"], as_index=False).agg(
{
"开盘": ["max", "mean"],
"收盘": ["min", "mean"],
}
)
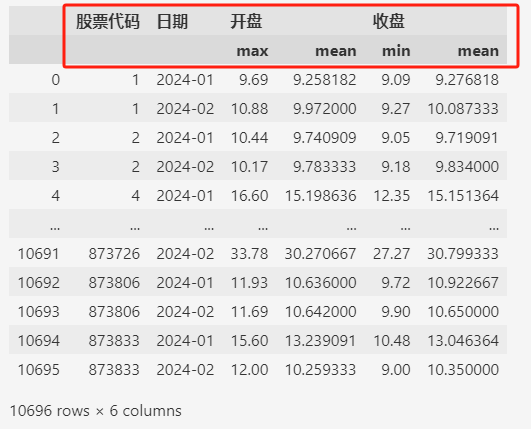
这样的话,分组的列(比如 ["股票代码", "日期"])就不会成为索引。
4. 总结
总的来说,groupby 函数是 pandas 库中一个非常常用的工具,它大大简化了数据处理和分析的过程,
使得用户能够更高效地洞察和理解数据。
分组聚合不再难:Pandas groupby使用指南的更多相关文章
- Pandas系列(九)-分组聚合详解
目录 1. 将对象分割成组 1.1 关闭排序 1.2 选择列 1.3 遍历分组 1.4 选择一个组 2. 聚合 2.1 一次应用多个聚合操作 2.2 对DataFrame列应用不同的聚合操作 3. t ...
- Pandas 分组聚合
# 导入相关库 import numpy as np import pandas as pd 创建数据 index = pd.Index(data=["Tom", "Bo ...
- Pandas | GroupBy 分组
任何分组(groupby)操作都涉及原始对象的以下操作之一: 分割对象 应用一个函数 结合的结果 在许多情况下,我们将数据分成多个集合,并在每个子集上应用一些函数.在应用函数中,可以执行以下操作: 聚 ...
- Pandas时间序列和分组聚合
#时间序列import pandas as pd import numpy as np # 生成一段时间范围 ''' 该函数主要用于生成一个固定频率的时间索引,在调用构造方法时,必须指定start.e ...
- Pandas 分组聚合 :分组、分组对象操作
1.概述 1.1 group语法 df.groupby(self, by=None, axis=0, level=None, as_index: bool=True, sort: bool=True, ...
- Atitit 数据存储的分组聚合 groupby的实现attilax总结
Atitit 数据存储的分组聚合 groupby的实现attilax总结 1. 聚合操作1 1.1. a.标量聚合 流聚合1 1.2. b.哈希聚合2 1.3. 所有的最优计划的选择都是基于现有统计 ...
- python pandas groupby
转自 : https://blog.csdn.net/Leonis_v/article/details/51832916 pandas提供了一个灵活高效的groupby功能,它使你能以一种自然的方式对 ...
- DataAnalysis-Pandas分组聚合
title: Pandas分组聚合 tags: 数据分析 python categories: DataAnalysis toc: true date: 2020-02-10 16:28:49 Des ...
- 数据分析04-pandas(apply函数、排序、数据合、分组聚合、透视表、交叉表及项目分析)
数据分析-04 排序 按标签(行)排序 按标签(列)排序 按某列值排序 数据合并 concat merge & join 分组聚合 分组 聚合 透视表与交叉表 透视表 交叉表 项目:分析影响学 ...
- crm使用FetchXml分组聚合查询
/* 创建者:菜刀居士的博客 * 创建日期:2014年07月09号 */ namespace Net.CRM.FetchXml { using System; using Micr ...
随机推荐
- 什么是ChatGPT,什么是大模型prompt
什么是ChatGpt ChatGPT是一个由美国的OpenAI公司开发的聊天机器人,它使用了大型语言模型,现在有GPT-3.GPT-3.5.GPT-4.0多个版本,目前还在快速发展,通过监督学习和强化 ...
- 利用Mybatis拦截器实现自定义的ID自增器
原生的Mybatis框架是没有ID自增器,但例如国产的Mybatis Plus却是支持,不过,Mybatis Plus却是缺少了自定属性的填充:例如:我们需要自定义填充一些属性,updateDate. ...
- 解锁ChatGLM-6B的潜力:优化大语言模型训练,突破任务困难与答案解析难题
解锁ChatGLM-6B的潜力:优化大语言模型训练,突破任务困难与答案解析难题 LLM(Large Language Model)通常拥有大量的先验知识,使得其在许多自然语言处理任务上都有着不错的性能 ...
- node版本控制工具nvm安装教程
一.安装nvm 查看node对应NPM:https://nodejs.org/en/about/previous-releases 1.卸载node,后删除node文件夹里的所有内容 2:安装nvm管 ...
- Docker生命周期,一张图秒懂docker
- Flink-启动后无法访问WebUI界面(Flink1.16)
问题描述 通过./bin/start-cluster.sh启动Flink程序,正常启动后无法通过浏览器访问web UI界面,http://192.168.80.133:8081. 问题原因 Flink ...
- Swoole从入门到入土(5)——TCP服务器[异步任务]
无论对于B/S还是C/S,程序再怎么变,唯一不变的是用户不想等太久的躁动心情.所以服务端对于客户的请求,能有多快就多快.如果服务端需要执行很耗时的操作,就需要异步任务处理机制,保证当前的响应速度不受影 ...
- 解决maven打包compliation failure程序包不存在
1.问题说明 spring boot项目,在cmd中使用mvn clean package打包报错如下: 说这个程序包不存在,而实际上在eclipse中查看是能找到的. 2.问题原因 后来看了一下这个 ...
- Error parsing HTTP request header--400 bad request
问题描述: JSP中通过form post方式请求URL传入json格式参数报错: 信息: Error parsing HTTP request header Note: further occur ...
- js常用知识点整理
说明:以下内容都是我工作中实际碰到的js知识点. 后面还会碰到其他知识点或对原来解决方案的改进,都会在本篇中持续不断的维护,希望给刚参加工作或初学的朋友一些参考. 1.给元素添加事件 $(" ...