神经网络之卷积篇:详解卷积步长(Strided convolutions)
详解卷积步长
卷积中的步幅是另一个构建卷积神经网络的基本操作,让向展示一个例子。
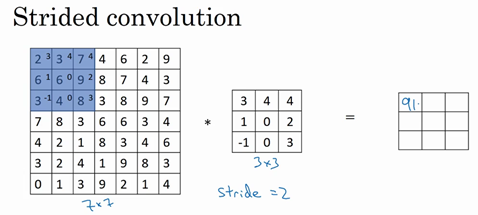
如果想用3×3的过滤器卷积这个7×7的图像,和之前不同的是,把步幅设置成了2。还和之前一样取左上方的3×3区域的元素的乘积,再加起来,最后结果为91。
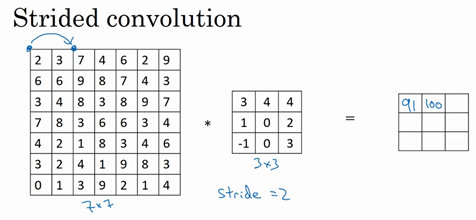
只是之前移动蓝框的步长是1,现在移动的步长是2,让过滤器跳过2个步长,注意一下左上角,这个点移动到其后两格的点,跳过了一个位置。然后还是将每个元素相乘并求和,将会得到的结果是100。
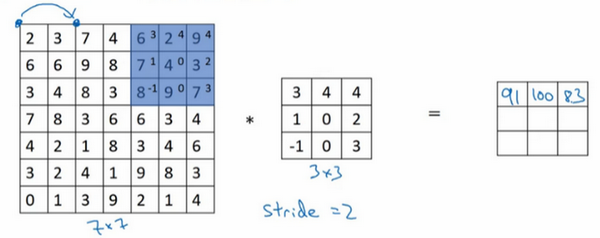
现在继续,将蓝色框移动两个步长,将会得到83的结果。当移动到下一行的时候,也是使用步长2而不是步长1,所以将蓝色框移动到这里:
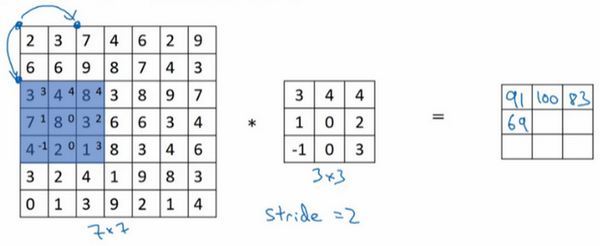
注意到跳过了一个位置,得到69的结果,现在继续移动两个步长,会得到91,127,最后一行分别是44,72,74。
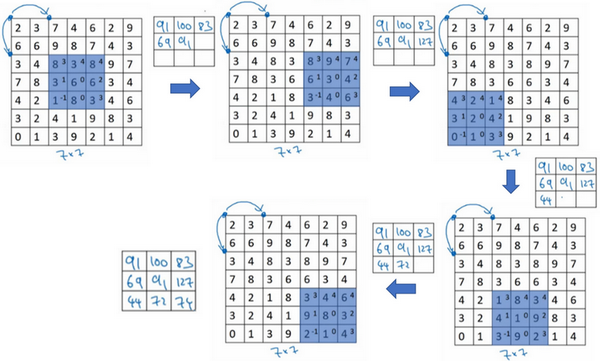
所以在这个例子中,用3×3的矩阵卷积一个7×7的矩阵,得到一个3×3的输出。输入和输出的维度是由下面的公式决定的。如果用一个\(f×f\)的过滤器卷积一个\(n×n\)的图像,padding为\(p\),步幅为\(s\),在这个例子中\(s=2\),会得到一个输出,因为现在不是一次移动一个步子,而是一次移动\(s\)个步子,输出于是变为\(\frac{n+2p - f}{s} + 1 \times \frac{n+2p - f}{s} + 1\)
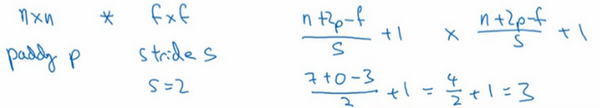
在这个例子里,\(n=7\),\(p=0\),\(f=3\),\(s=2\),\(\ \frac{7 + 0 - 3}{2} + 1 =3\),即3×3的输出。
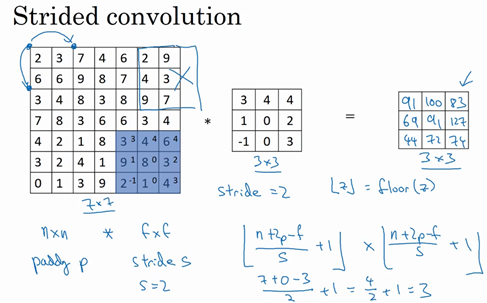
现在只剩下最后的一个细节了,如果商不是一个整数怎么办?在这种情况下,向下取整。\(⌊ ⌋\)这是向下取整的符号,这也叫做对\(z\)进行地板除(floor),这意味着\(z\)向下取整到最近的整数。这个原则实现的方式是,只在蓝框完全包括在图像或填充完的图像内部时,才对它进行运算。如果有任意一个蓝框移动到了外面,那就不要进行相乘操作,这是一个惯例。3×3的过滤器必须完全处于图像中或者填充之后的图像区域内才输出相应结果,这就是惯例。因此正确计算输出维度的方法是向下取整,以免\(\frac{n + 2p - f}{s}\)不是整数。

总结一下维度情况,如果有一个\(n×n\)的矩阵或者\(n×n\)的图像,与一个\(f×f\)的矩阵卷积,或者说\(f×f\)的过滤器。Padding是\(p\),步幅为\(s\)没输出尺寸就是这样:

可以选择所有的数使结果是整数是挺不错的,尽管一些时候,不必这样做,只要向下取整也就可以了。也可以自己选择一些\(n\),\(f\),\(p\)和\(s\)的值来验证这个输出尺寸的公式是对的。
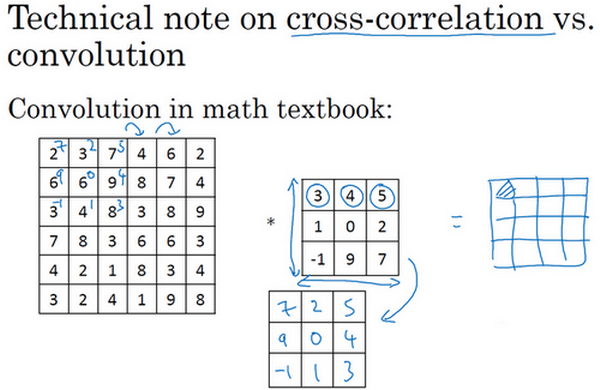
这里有一个关于互相关和卷积的技术性建议,这不会影响到构建卷积神经网络的方式,但取决于读的是数学教材还是信号处理教材,在不同的教材里符号可能不一致。如果看的是一本典型的数学教科书,那么卷积的定义是做元素乘积求和,实际上还有一个步骤是首先要做的,也就是在把这个6×6的矩阵和3×3的过滤器卷积之前,首先将3×3的过滤器沿水平和垂直轴翻转,所以\(\begin{bmatrix}3 & 4 & 5 \\ 1 & 0 & 2 \\ - 1 & 9 & 7 \\ \end{bmatrix}\)变为\(\begin{bmatrix} 7& 2 & 5 \\ 9 & 0 & 4 \\ - 1 & 1 & 3 \\\end{bmatrix}\),这相当于将3×3的过滤器做了个镜像,在水平和垂直轴上(整理者注:此处应该是先顺时针旋转90得到\(\begin{bmatrix}-1 & 1 & 3 \\ 9 & 0 & 4 \\ 7 & 2 & 5 \\\end{bmatrix}\),再水平翻转得到\(\begin{bmatrix} 7& 2 & 5 \\ 9 & 0 & 4 \\ - 1& 1 & 3 \\\end{bmatrix}\))。然后再把这个翻转后的矩阵复制到这里(左边的图像矩阵),要把这个翻转矩阵的元素相乘来计算输出的4×4矩阵左上角的元素,如图所示。然后取这9个数字,把它们平移一个位置,再平移一格,以此类推。
所以在这中定义卷积运算时,跳过了这个镜像操作。从技术上讲,实际上做的,在前面使用的操作,有时被称为互相关(cross-correlation)而不是卷积(convolution)。但在深度学习文献中,按照惯例,将这(不进行翻转操作)叫做卷积操作。
总结来说,按照机器学习的惯例,通常不进行翻转操作。从技术上说,这个操作可能叫做互相关更好。但在大部分的深度学习文献中都把它叫做卷积运算,因此将在这使用这个约定。如果读了很多机器学习文献的话,会发现许多人都把它叫做卷积运算,不需要用到这些翻转。
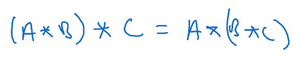
事实证明在信号处理中或某些数学分支中,在卷积的定义包含翻转,使得卷积运算符拥有这个性质,即\((A*B)*C=A*(B*C)\),这在数学中被称为结合律。这对于一些信号处理应用来说很好,但对于深度神经网络来说它真的不重要,因此省略了这个双重镜像操作,就简化了代码,并使神经网络也能正常工作。
根据惯例,大多数人都叫它卷积,尽管数学家们更喜欢称之为互相关,但这不会影响到在编程练习中要实现的任何东西,也不会影响阅读和理解深度学习文献。
神经网络之卷积篇:详解卷积步长(Strided convolutions)的更多相关文章
- 详解卷积神经网络(CNN)
详解卷积神经网络(CNN) 详解卷积神经网络CNN 概揽 Layers used to build ConvNets 卷积层Convolutional layer 池化层Pooling Layer 全 ...
- 【33】卷积步长讲解(Strided convolutions)
卷积步长(Strided convolutions) 卷积中的步幅是另一个构建卷积神经网络的基本操作,让我向你展示一个例子. 如果你想用3×3的过滤器卷积这个7×7的图像,和之前不同的是,我们把步幅设 ...
- PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
PHP函数篇详解十进制.二进制.八进制和十六进制转换函数说明 作者: 字体:[增加 减小] 类型:转载 中文字符编码研究系列第一期,PHP函数篇详解十进制.二进制.八进制和十六进制互相转换函数说明 ...
- 走向DBA[MSSQL篇] 详解游标
原文:走向DBA[MSSQL篇] 详解游标 前篇回顾:上一篇虫子介绍了一些不常用的数据过滤方式,本篇详细介绍下游标. 概念 简单点说游标的作用就是存储一个结果集,并根据语法将这个结果集的数据逐条处理. ...
- 基于双向BiLstm神经网络的中文分词详解及源码
基于双向BiLstm神经网络的中文分词详解及源码 基于双向BiLstm神经网络的中文分词详解及源码 1 标注序列 2 训练网络 3 Viterbi算法求解最优路径 4 keras代码讲解 最后 源代码 ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- 【python实现卷积神经网络】卷积层Conv2D反向传播过程
代码来源:https://github.com/eriklindernoren/ML-From-Scratch 卷积神经网络中卷积层Conv2D(带stride.padding)的具体实现:https ...
- 第十五节,卷积神经网络之AlexNet网络详解(五)
原文 ImageNet Classification with Deep ConvolutionalNeural Networks 下载地址:http://papers.nips.cc/paper/4 ...
- 详解卷积神经网络(CNN)在语音识别中的应用
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~ 作者:侯艺馨 前言 总结目前语音识别的发展现状,dnn.rnn/lstm和cnn算是语音识别中几个比较主流的方向.2012年,微软邓力和俞栋老 ...
- 神经网络:卷积神经网络CNN
一.前言 这篇卷积神经网络是前面介绍的多层神经网络的进一步深入,它将深度学习的思想引入到了神经网络当中,通过卷积运算来由浅入深的提取图像的不同层次的特征,而利用神经网络的训练过程让整个网络自动调节卷积 ...
随机推荐
- C# 设置PDF表单不可编辑、或提取PDF表单数据
PDF表单是PDF中的可编辑区域,允许用户填写指定信息.当表单填写完成后,有时候我们可能需要将其设置为不可编辑,以保护表单内容的完整性和可靠性.或者需要从PDF表单中提取数据以便后续处理或分析. 之前 ...
- Blender练习——SciFi枪械.md
Blender练习--SciFi枪械 一.基本操作 常用快捷键 E 挤出 B 倒角,中途可通过滚轮或S来调整细分 Alt+点选 循环选择 Ctrl Alt+点选 并排选择 F 补面,比如一个碗口,将碗 ...
- opencv在MAC下的安装
版本信息 MAC版本:10.10.5 Xcode版本:7.2 openCV版本:2.4.13 安装步骤: 联网 安装brew,在终端输入指令 /usr/bin/ruby -e "$(curl ...
- CentOS7安装最新版ruby
背景 直接通过yum安装的ruby版本太低,不能满足redis.fpm等软件的需求. 系统环境 CentOS7 安装步骤 下载ruby http://www.ruby-lang.org/en/down ...
- Atcoder Beginner Contest 321 G - Electric Circuit 题解 - 状压dp | 指定最低位
为了更好的阅读体验,请点击这里 题目链接:G - Electric Circuit 看到了 \(N\) 的数据范围,因此是显然的状压 dp. 不妨设 \(f_S\) 为仅使用 \(S\) 集合中的所有 ...
- FPGA对EEPROM驱动控制(I2C协议)
本文摘要:本文首先对I2C协议的通信模式和AT24C16-EEPROM芯片时序控制进行分析和理解,设计了一个i2c通信方案.人为按下写操作按键后,FPGA(Altera EP4CE10)对EEPROM ...
- 机器学习(三)——K最临近方法构建分类模型(matlab)
K最临近(K-Nearest Neighbors,KNN)方法是一种简单且直观的分类和回归算法,主要用于分类任务.其基本原理是用到表决的方法,找到距离其最近的K个样本,然后通过K个样本的标签进行表决, ...
- bs4解析-湖南农场品价格行情
import requests from bs4 import BeautifulSoup import csv url = 'https://price.21food.cn/market/174-p ...
- PHP转Go系列 | GET 和 POST 请求的使用姿势
大家好,我是码农先森. 说到 HTTP 请求工具想必对我们做 Web 开发的程序员都不陌生,只要涉及到网络请求都必须使用.对于我们 PHP 程序员来说,最熟悉不过的就是 CURL 扩展,只要安装的这个 ...
- Ubuntu下的NVIDIA显卡【安装与卸载、CUDA安装】
@ 目录 0. 显卡GPU的基础知识 1. 显卡安装 Optional: 卸载显卡(当你要换显卡的时候) 2. 安装CUDA 碎碎念:主要是把显卡相关的整合出来,基础知识后面再放上来 显卡安装后可以有 ...